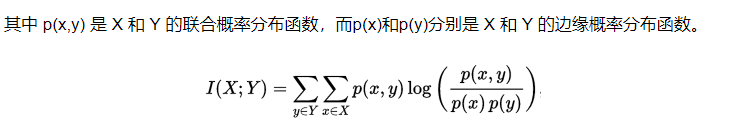关键词提取
目录
文本关键词提取
参考:https://blog.csdn.net/asialee_bird/article/details/96454544
概述
关键词 是能够表达文档中心内容的词语,常用于计算机系统标引论文内容特征、信息检索、系统汇集以供读者检阅。关键词提取是文本挖掘领域的一个分支,是文本检索、文档比较、摘要生成、文档分类和聚类等文本挖掘研究的基础性工作。
从算法的角度来看,关键词提取算法主要有两类: 无监督关键词提取 方法和 有监督关键词提取 方法。
无监督提取
无监督关键词提取方法主要有三类:基于统计特征的关键词提取(TF-IDF);基于词图模型的关键词提取(PageRank,TextRank);基于主题模型的关键词提取(LDA)
- 基于统计特征的关键词提取算法的思想是利用文档中词语的统计信息抽取文档的关键词;
- 基于词图模型的关键词提取首先要构建文档的语言网络图,然后对语言进行网络图分析,在这个图上寻找具有重要作用的词或者短语,这些短语就是文档的关键词;
- 基于主题关键词提取算法主要利用的是主题模型中关于主题分布的性质进行关键词提取;
有监督提取
将关键词抽取过程视为二分类问题,先提取出候选词,然后对于每个候选词划定标签,要么是关键词,要么不是关键词,然后训练关键词抽取分类器。当新来一篇文档时,提取出所有的候选词,然后利用训练好的关键词提取分类器,对各个候选词进行分类,最终将标签为关键词的候选词作为关键词。
TF-IDF算法提取
详见本博客TF-IDF有关内容
TextRank算法提取
详见本博客TextRank算法有关内容
LDA主题模型
详见本博客LDA主题模型有关内容
Word2Vec词聚类的关键词算法
步骤
- 对语料进行Word2Vec模型训练,得到词向量文件;
- 对文本进行预处理获得N个候选关键词;
- 遍历候选关键词,从词向量文件中提取候选关键词的词向量表示;
- 对候选关键词进行K-Means聚类,得到各个类别的聚类中心(需要人为给定聚类的个数);
- 计算各类别下,组内词语与聚类中心的距离(欧几里得距离或曼哈顿距离),按聚类大小进行降序排序;
- 对候选关键词计算结果得到排名前TopK个词语作为文本关键词。
互信息
- 标准化互信息(Normalized Mutual Information,NMI)可以用来衡量两种聚类结果的相似度。
- 标准化互信息Sklearn实现:metrics.normalized_mutual_info_score(y_train, x_train[:, i])。
- 点互信息(Pointwise Mutual Information,PMI)这个指标来衡量两个事物之间的相关性(比如两个词)。
点互信息(PMI):
\[ PMI(w, c) = log\frac{P(w,c)}{P(w)P(c)} = log \frac{N(w,c)|(w,c)|}{N(w)N(c)} \]