shortcode(置顶)
贴一下可以玩的shortcode。
音乐播放
播放列表
夏日口袋专辑:
播放单曲
最爱的一首(我是紬厨):
视频播放
bilibili
有多P可以选择集数admonition
类型有:note、abstract、info、tip、success、question、warning、failure、danger、bug、example、quote。
技巧
一个 技巧 横幅
贴一下可以玩的shortcode。
夏日口袋专辑:
最爱的一首(我是紬厨):
类型有:note、abstract、info、tip、success、question、warning、failure、danger、bug、example、quote。
------------------------------------------------------------------------------------------------------
# Qwen-1
+ Embedding and output projection. (Untied embedding for input embedding and output projection)
+ ROPE
+ QKV bias required
+ Pre-Norm & RMSNorm
+ SwiGLU
------------------------------------------------------------------------------------------------------
# Qwen-2
- Multi-Head Attention
+ MoE
+ Grouped Query Attention
+ Dual Chunk Attention
+ YARN
+ Expert Granularity
+ Expert Routing
+ Expert Initialization
+ Shared Experts
------------------------------------------------------------------------------------------------------
# Qwen-2.5
+ More control tokens. 3 -> 22
------------------------------------------------------------------------------------------------------
# Qwen-3
- QKV bias
- Shared experts
+ QK-Norm
------------------------------------------------------------------------------------------------------最近涌现了很多关于信用分配的论文,因此整理一下
在softmax的结果后添加一个静态的不可学习的偏置项。 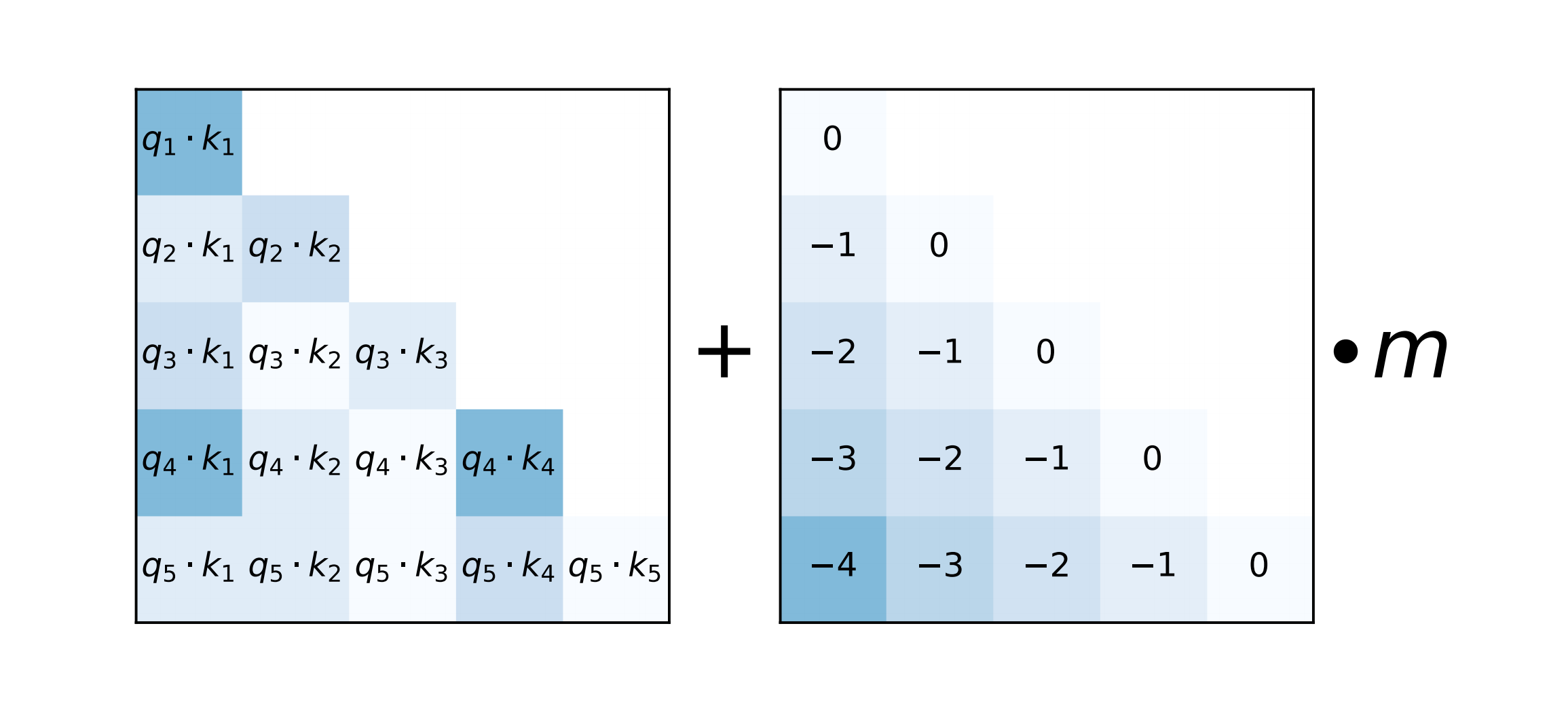 q1和k1之间的距离是0,所以对应位置就是0
q1和k1之间的距离是0,所以对应位置就是0
q2和k1之间的距离是「相对位置偏移为“k的索引”1」 -
「q的索引2」,得到1-2 = -1,就对应到了中间矩阵的取值为-1了
以此类推,相对距离矩阵的中间对角线上都是0,然后左下角的取值都是对应的「k的索引」-「q的索引」了
简单来说就是在Q和K矩阵上进行RMSNorm,即:
\[ \begin{aligned} O &= softmax(\bar{Q}\bar{K}^T)V \\ \bar{Q} &=RMSNorm(Q) \\ \bar{K} &=RMSNorm(V) \end{aligned}\ \]
但这种方法的问题是不适用MLA的推理阶段,因为推理阶段的MLA将Wk吸取到了Q中,具体见MLA
详细讲解一下verl中的RLHFDataset,它继承自torch的Dataset,需要实现__getitem__来返回数据。
class RLHFDataset(Dataset):
"""
Load and preprocess RLHF data from Parquet files.
- Caches files locally.
- Reads into a HuggingFace Dataset and tokenizes prompts.
- Optionally handles images/videos via a ProcessorMixin.
- Filters prompts over a max length.
- Supports resuming from checkpoints.
Args:
data_files (str or list): Path(s) to Parquet file(s).
tokenizer (PreTrainedTokenizer): For the tokenization of text to token IDs.
config (DictConfig): Options like cache_dir, prompt_key, max_prompt_length, truncation, etc.
processor (ProcessorMixin, optional): Multimodal preprocessor for images/videos.
"""
def __init__(
self,
data_files: str | list[str],
tokenizer: PreTrainedTokenizer,
config: DictConfig,
processor: Optional[ProcessorMixin] = None,
):
if not isinstance(data_files, list | ListConfig):
data_files = [data_files]
self.data_files = copy.deepcopy(data_files)
self.original_data_files = copy.deepcopy(data_files) # use for resume
self.tokenizer = tokenizer
self.processor = processor
self.config = config
self.cache_dir = os.path.expanduser(config.get("cache_dir", "~/.cache/verl/rlhf"))
self.prompt_key = config.get("prompt_key", "prompt")
self.image_key = config.get("image_key", "images")
self.video_key = config.get("video_key", "videos")
self.max_prompt_length = config.get("max_prompt_length", 1024)
self.return_raw_chat = config.get("return_raw_chat", False)
self.return_full_prompt = config.get("return_full_prompt", False)
self.truncation = config.get("truncation", "error")
self.filter_overlong_prompts = config.get("filter_overlong_prompts", True)
self.num_workers = config.get("filter_overlong_prompts_workers", max(1, os.cpu_count() // 4))
self.num_workers = min(self.num_workers, os.cpu_count())
self.use_shm = config.get("use_shm", False)
self.chat_template_func = config.get("chat_template_func", None)
self.need_tools_kwargs = config.get("need_tools_kwargs", False)
self.filter_prompts = config.get("filter_prompts", True)
self.serialize_dataset = False
self.return_multi_modal_inputs = config.get("return_multi_modal_inputs", True)
self._download()
self._read_files_and_tokenize()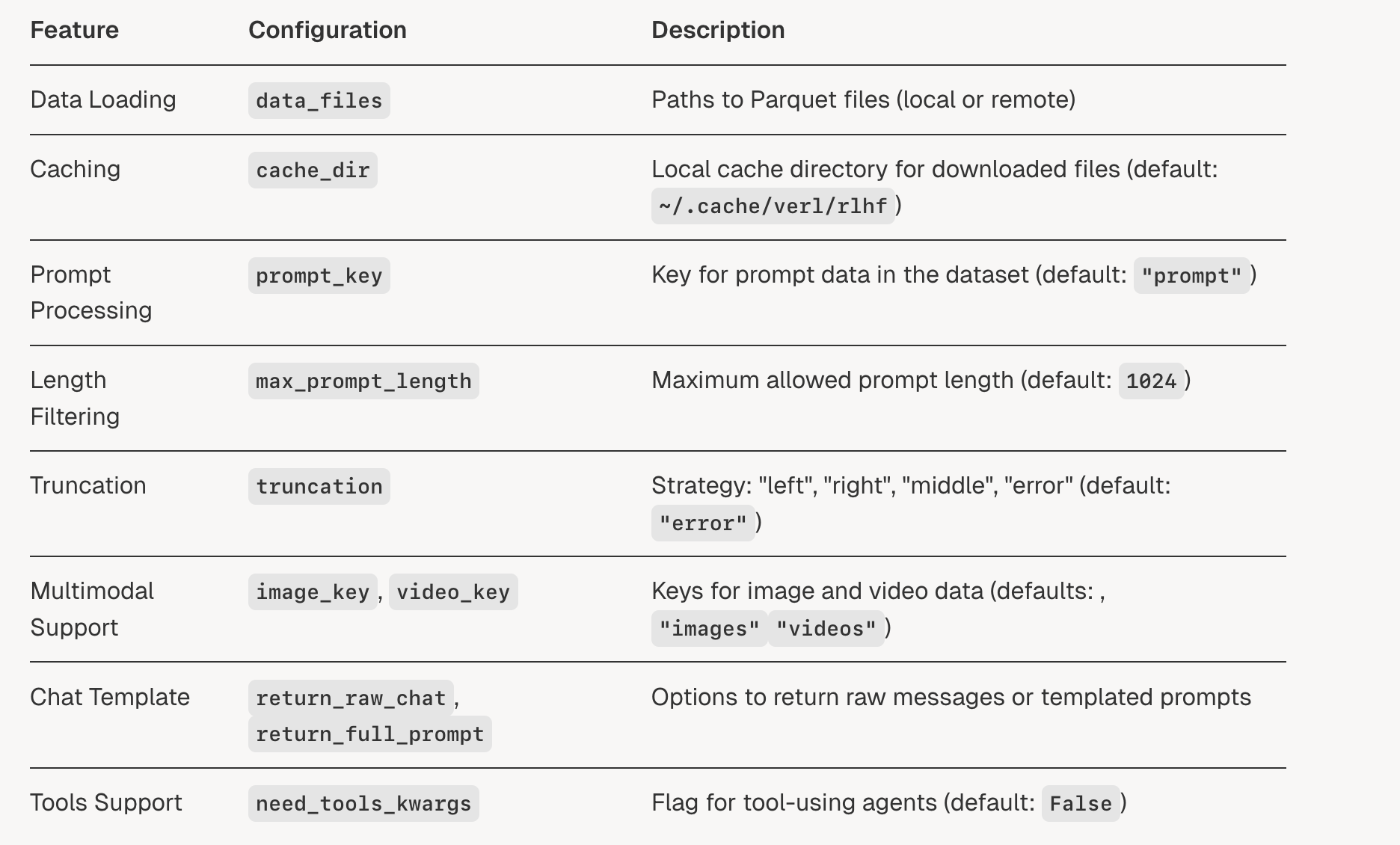 (来自deepwiki)
(来自deepwiki)
verl中有3个device_mesh,分别是: - 训练用的FSDP mesh(通常是一维) - 推理用的rollout mesh(包含tp维度) - Ulysses序列并行的mesh(dp×sp)
Verl 最近实现了 agent loop 功能,也就是多轮工具调用 RL ,弥补了 verl 中 vllm 无法使用多轮 rollout 的不足。整体流程大致如下(来自 https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/blob/main/rlhf/verl/multi-turn/imgs/Multi-Turn_Rollout_Workflow.png)
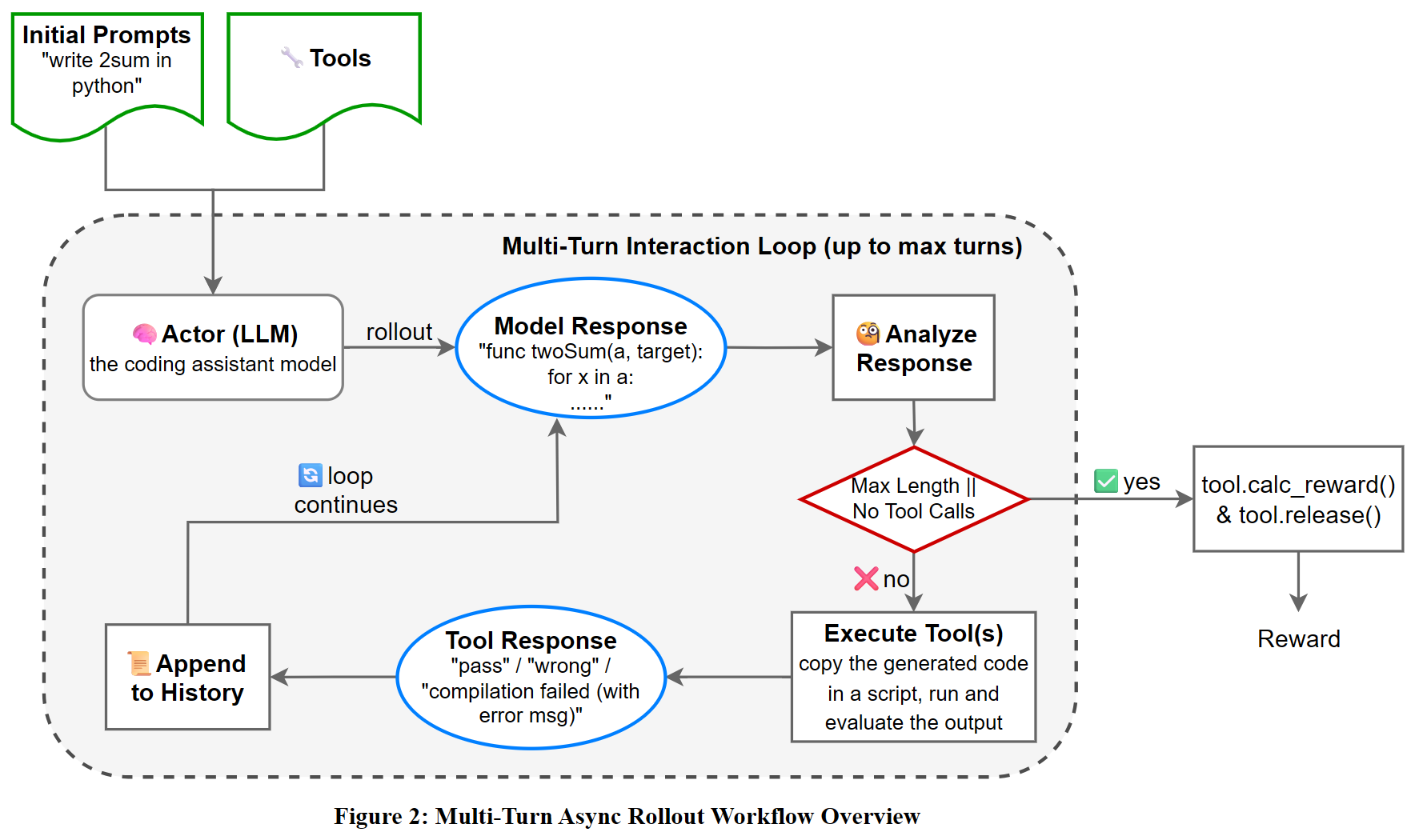
在官方实现中(目前在 verl/experimental/agent_loop 目录下),核心代码在 agent_loop.py中,single_turn_agent_loop.py和tool_agent_loop对应两种agent_loop,tool_parser.py定义了hermes工具解析类。所以重点就是在agent_loop.py中,各个类的协作流程如下图: