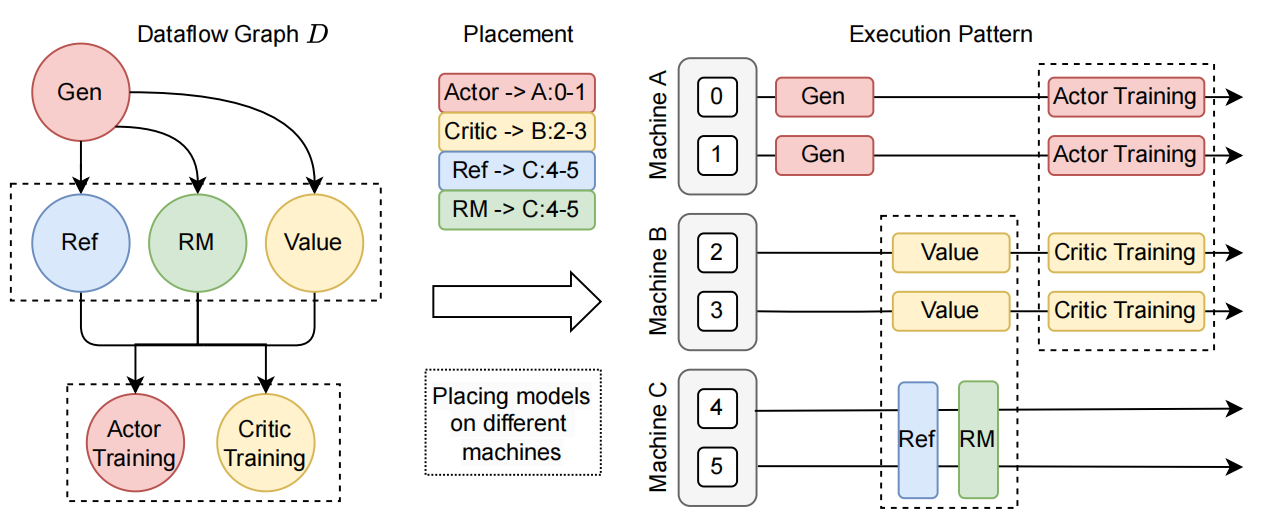
verl总体概览
Hybrid Engine
在 RLHF 流程中,actor model 的 generation 和 rollout 占据了绝大多数运行时间(在 veRL 是 58.9%)。并且,由于 PPO 是 online 算法,经验(experiences)必须来自于被 train 的模型本身,因此,rollout 和 training 是必须串行的。如果这两者使用不同的资源组,比如 rollout 用 2 张卡,而 training 用 4 张卡,rollout 的时候 training 的资源闲置,training 的时候 rollout 的资源闲置,无论如何都会浪费大量的计算资源。由此,veRL 将 training 和 rollout engine 放置在同一个资源组中串行执行。training 时,将 rollout engine 的显存回收(offload 到 CPU 上 或者直接析构掉),rollout 时,再将 training engine 的显存释放掉。这种将 actor model 的不同 engine 放置在同一个资源组上的方案,就称为 hybrid engine。