tokenization
Tokenization技术
本文章主要说说NLP领域中的Tokenization技术,这是很基础的但也是很容易被忽视的一个步骤。在我接的单子中经常会有此类问题,并且都是外国学校的,说明外国学校还是比较注重这一块的基础的。 首先明确一个概念:token可以理解为一个符号,就代表一个语言单位,tokenize的意思就是把一个句子或语料分成token.
word
char
子词(subword)
BPE
BPE 是一种简单的数据压缩算法,它在 1994 年发表的文章“A New Algorithm for Data Compression”中被首次提出。下面的示例将解释 BPE。老规矩,我们先用一句话概括它的核心思想:
BPE每一步都将最常见的一对相邻数据单位替换为该数据中没有出现过的一个新单位,反复迭代直到满足停止条件。
BPE 确保最常见的词在token列表中表示为单个token,而罕见的词被分解为两个或多个subword tokens,因此BPE也是典型的基于subword的tokenization算法。
合并字符可以让你用最少的token来表示语料库,这也是 BPE 算法的主要目标,即数据的压缩。为了合并,BPE 寻找最常出现的字节对。在这里,我们将字符视为与字节等价。当然,这只是英语的用法,其他语言可能有所不同。现在我们将最常见的字节对合并成一个token,并将它们添加到token列表中,并重新计算每个token出现的频率。这意味着我们的频率计数将在每个合并步骤后发生变化。我们将继续执行此合并步骤,直到达到我们预先设置的token数限制或迭代限制。
算法过程
- 准备语料库,确定期望的 subword 词表大小等参数
- 通常在每个单词末尾添加后缀 ,统计每个单词出现的频率,例如,low 的频率为 5,那么我们将其改写为 “l o w ”:5
- 将语料库中所有单词拆分为单个字符,用所有单个字符建立最初的词典,并统计每个字符的频率,本阶段的 subword 的粒度是字符
- 挑出频次最高的符号对 ,比如说
t和h组成的th,将新字符加入词表,然后将语料中所有该字符对融合(merge),即所有t和h都变为th。 - 重复上述操作,直到词表中单词数达到设定量 或下一个最高频数为 1 ,如果已经打到设定量,其余的词汇直接丢弃
例子
获取语料库,这样一段话为例:“ FloydHub is the fastest way to build, train and deploy deep learning models. Build deep learning models in the cloud. Train deep learning models. ”
拆分,加后缀
</w>,统计词频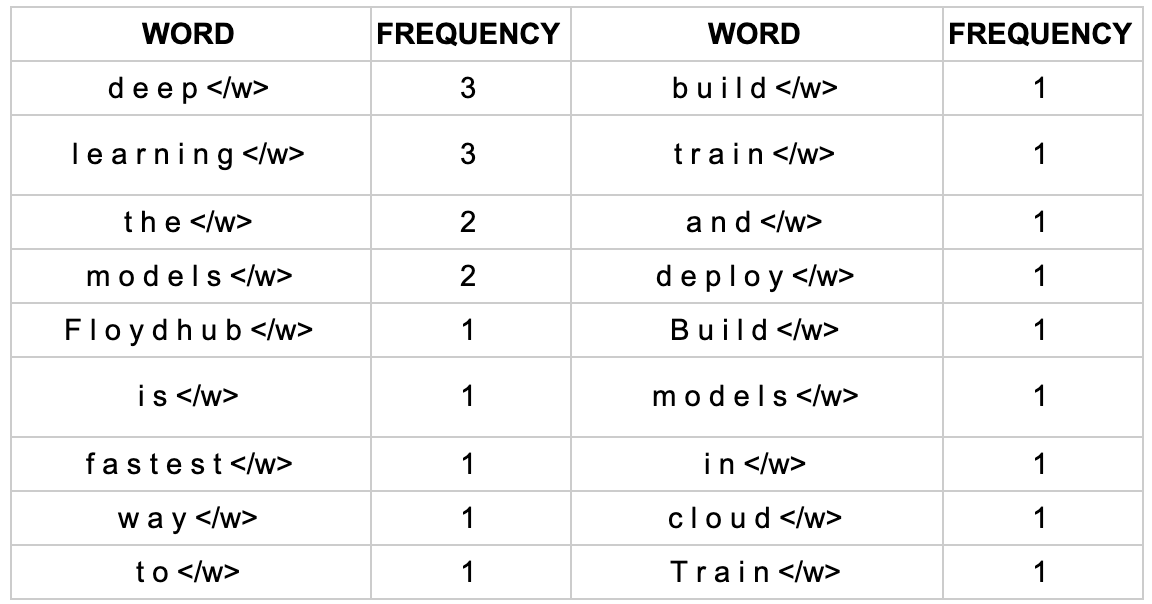
建立词表,统计字符频率(顺便排个序):
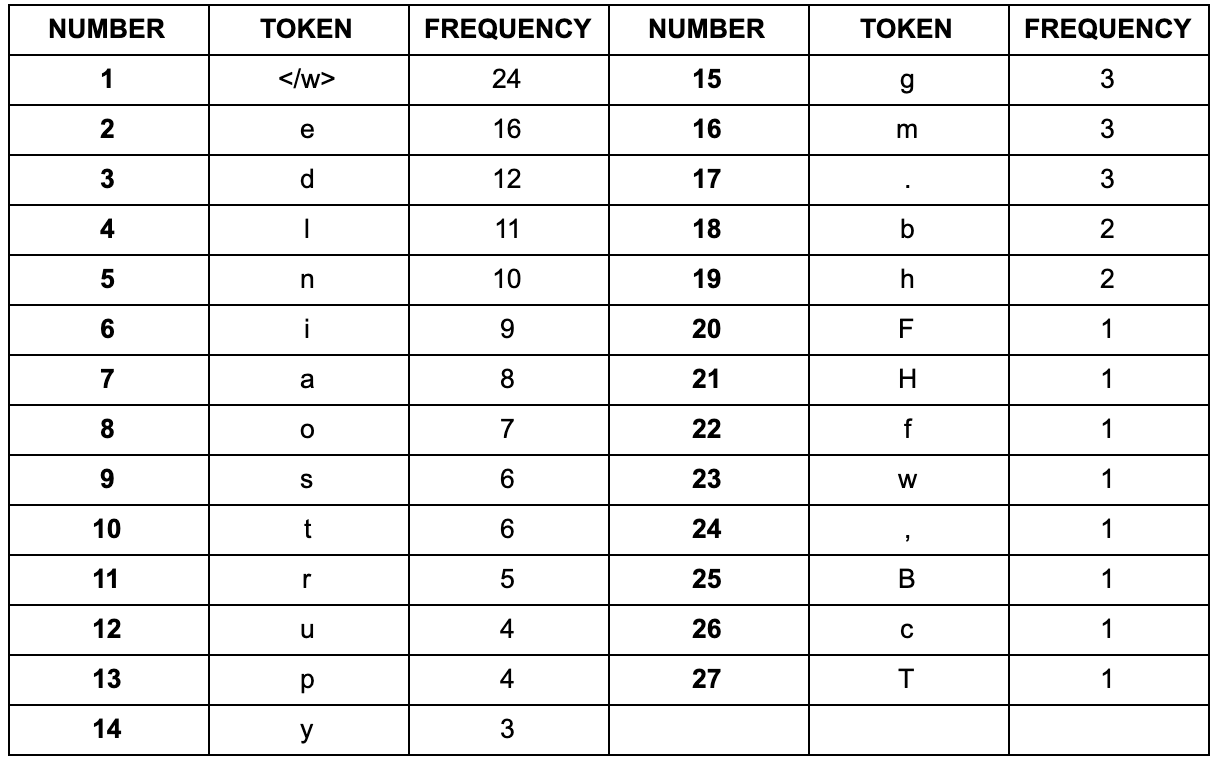
以第一次迭代为例,将字符频率最高的
d和e替换为de,后面依次迭代: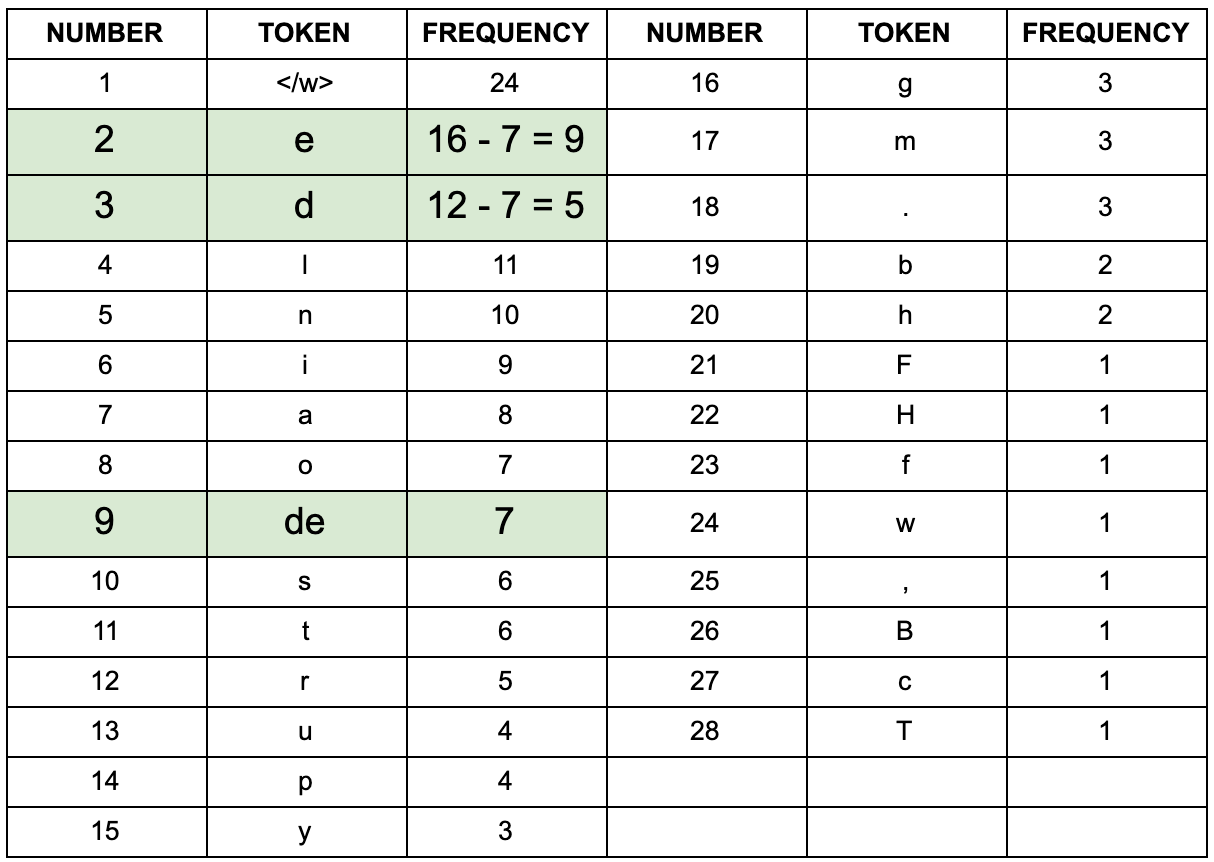
更新词表
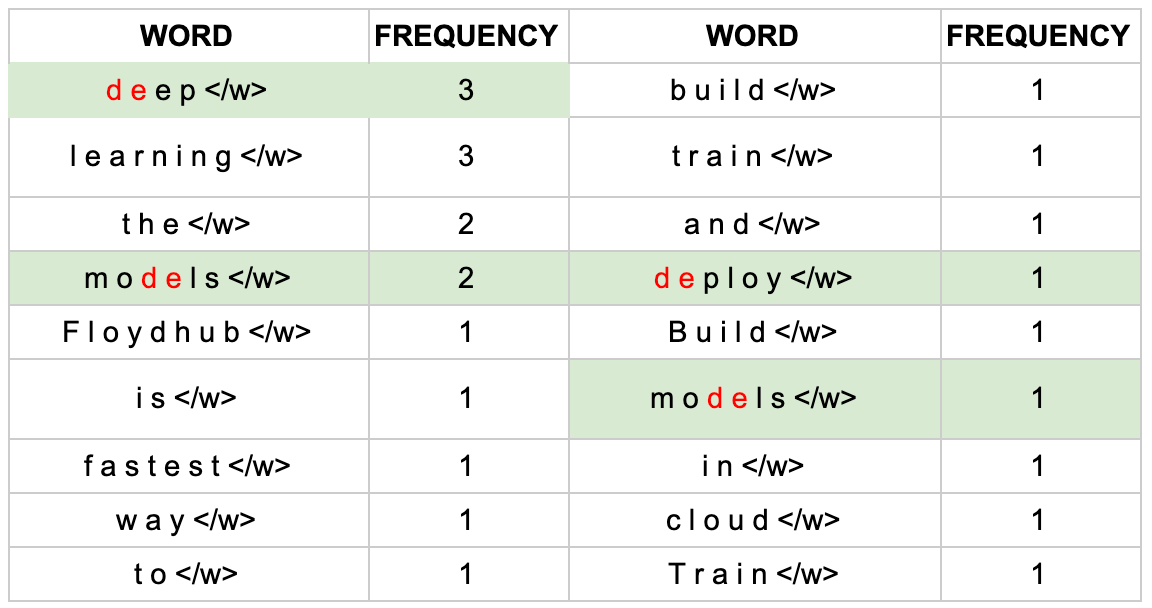 继续迭代直到达到预设的 subwords 词表大小或下一个最高频的字节对出现频率为
1。 ### 优点 BPE
的优点就在于,可以很有效地平衡词典大小和编码步骤数(将语料编码所需要的
token 数量)。
继续迭代直到达到预设的 subwords 词表大小或下一个最高频的字节对出现频率为
1。 ### 优点 BPE
的优点就在于,可以很有效地平衡词典大小和编码步骤数(将语料编码所需要的
token 数量)。
随着合并的次数增加,词表大小通常先增加后减小。迭代次数太小,大部分还是字母,没什么意义;迭代次数多,又重新变回了原来那几个词。所以词表大小要取一个中间值。
适用范围
BPE 一般适用在欧美语言拉丁语系中,因为欧美语言大多是字符形式,涉及前缀、后缀的单词比较多。而中文的汉字一般不用 BPE 进行编码,因为中文是字无法进行拆分。对中文的处理通常只有分词和分字两种。理论上分词效果更好,更好的区别语义。分字效率高、简洁,因为常用的字不过 3000 字,词表更加简短。
编码过程
BPE的总体思想就是利用替换字节对来逐步构造词汇表。在使用的过程有编码和解码两种。 在之前的算法中,我们已经得到了subword的词表,对该词表按照子词长度由大到小排序。编码时,对于每个单词,遍历排好序的子词词表寻找是否有token是当前单词的子字符串,如果有,则该token是表示单词的tokens之一。
我们从最长的token迭代到最短的token,尝试将每个单词中的子字符串替换为token。 最终,我们将迭代所有tokens,并将所有子字符串替换为tokens。 如果仍然有子字符串没被替换但所有token都已迭代完毕,则将剩余的子词替换为特殊token,如
编码的计算量很大。 在实践中,我们可以pre-tokenize所有单词,并在词典中保存单词tokenize的结果。 如果我们看到字典中不存在的未知单词。 我们应用上述编码方法对单词进行tokenize,然后将新单词的tokenization添加到字典中备用。
代码
import re, collections
def get_vocab(filename):
vocab = collections.defaultdict(int)
with open(filename, 'r', encoding='utf-8') as fhand:
for line in fhand:
words = line.strip().split()
for word in words:
vocab[' '.join(list(word)) + ' </w>'] += 1
return vocab
def get_stats(vocab): # 构建字符对频数字典
pairs = collections.defaultdict(int)
for word, freq in vocab.items():
symbols = word.split()
for i in range(len(symbols)-1):
pairs[symbols[i],symbols[i+1]] += freq
return pairs
def merge_vocab(pair, v_in): # 将频率最大的字符对替换
v_out = {}
bigram = re.escape(' '.join(pair)) # 不转义
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)') # 意思是bigram前面没有非空格字符,后面也没有非空格字符
for word in v_in:
w_out = p.sub(''.join(pair), word)
v_out[w_out] = v_in[word]
return v_out
def get_tokens(vocab):
tokens = collections.defaultdict(int)
for word, freq in vocab.items():
word_tokens = word.split()
for token in word_tokens:
tokens[token] += freq
return tokens
vocab = {'l o w </w>': 5, 'l o w e r </w>': 2, 'n e w e s t </w>': 6, 'w i d e s t </w>': 3}
print('==========')
print('Tokens Before BPE')
tokens = get_tokens(vocab)
print('Tokens: {}'.format(tokens))
print('Number of tokens: {}'.format(len(tokens)))
print('==========')
num_merges = 5
for i in range(num_merges):
pairs = get_stats(vocab)
if not pairs:
break
best = max(pairs, key=pairs.get)
vocab = merge_vocab(best, vocab)
print('Iter: {}'.format(i))
print('Best pair: {}'.format(best))
print(vocab)
# tokens = get_tokens(vocab)
# print('Tokens: {}'.format(tokens))wordpiece
构造
wordpiece 词表的构造与BPE很相似,都是选择两个子词合并成新的子词。
最大的区别在于,BPE是选择频数最高的相邻子词合并,而wordpiece选择能够提升语言模型概率最大的相邻子词加入词表。
如何理解?
假设各个子词之间是独立存在的,则句子S的语言模型似然值等价于所有子词概率的乘积
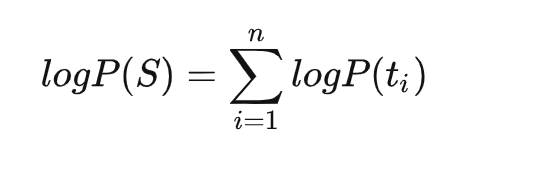 假设把相邻位置的x和y两个子词进行合并,合并后产生的子词记为z,此时句子S似然值的变化可表示为:
假设把相邻位置的x和y两个子词进行合并,合并后产生的子词记为z,此时句子S似然值的变化可表示为:
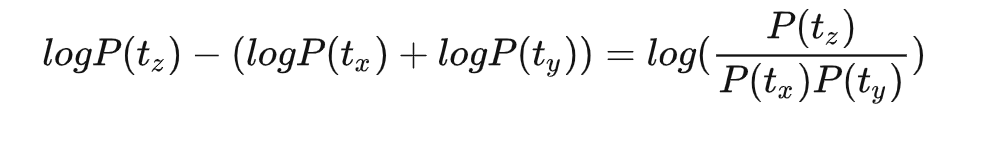 从上面的公式,很容易发现,似然值的变化就是两个子词之间的互信息。简而言之,WordPiece每次选择合并的两个子词,他们具有最大的互信息值,也就是两子词在语言模型上具有较强的关联性,它们经常在语料中以相邻方式同时出现。
与BPE相似,通过以上方式构建词表。 ### 编码 1.
从第一个位置开始,由于是最长匹配,结束位置需要从最右端依次递减,所以遍历的第一个子词
是其本身 unaffable,该子词不在词汇表中 2. 结束位置左移一位得到子词
unaffabl,同样不在词汇表中 3. 重复这个操作,直到
un,该子词在词汇表中,将其加入 output_tokens,以第一个位置开始
的遍历结束 4. 跳过 un,从其后的 a
开始新一轮遍历,结束位置依然是从最右端依次递减,但此时需要在前 面加上 ##
标记,得到 ##affable 不在词汇表中 5. 结束位置左移一位得到子词
##affabl,同样不在词汇表中 6. 重复这个操作,直到
##aff,该字词在词汇表中, 将其加入 output_tokens,此轮遍历结束 7. 跳过
aff,从其后的 a 开始新一轮遍历,结束位置依然是从最右端依次递减。##able
在词汇 表中,将其加入 output_tokens 8. able
后没有字符了,整个遍历结束
从上面的公式,很容易发现,似然值的变化就是两个子词之间的互信息。简而言之,WordPiece每次选择合并的两个子词,他们具有最大的互信息值,也就是两子词在语言模型上具有较强的关联性,它们经常在语料中以相邻方式同时出现。
与BPE相似,通过以上方式构建词表。 ### 编码 1.
从第一个位置开始,由于是最长匹配,结束位置需要从最右端依次递减,所以遍历的第一个子词
是其本身 unaffable,该子词不在词汇表中 2. 结束位置左移一位得到子词
unaffabl,同样不在词汇表中 3. 重复这个操作,直到
un,该子词在词汇表中,将其加入 output_tokens,以第一个位置开始
的遍历结束 4. 跳过 un,从其后的 a
开始新一轮遍历,结束位置依然是从最右端依次递减,但此时需要在前 面加上 ##
标记,得到 ##affable 不在词汇表中 5. 结束位置左移一位得到子词
##affabl,同样不在词汇表中 6. 重复这个操作,直到
##aff,该字词在词汇表中, 将其加入 output_tokens,此轮遍历结束 7. 跳过
aff,从其后的 a 开始新一轮遍历,结束位置依然是从最右端依次递减。##able
在词汇 表中,将其加入 output_tokens 8. able
后没有字符了,整个遍历结束
代码
(来自https://github.com/google-research/bert/blob/master/tokenization.py)
class WordpieceTokenizer(object):
"""Runs WordPiece tokenziation."""
def __init__(self, vocab, unk_token="[UNK]", max_input_chars_per_word=200):
self.vocab = vocab
self.unk_token = unk_token
self.max_input_chars_per_word = max_input_chars_per_word
def tokenize(self, text):
"""Tokenizes a piece of text into its word pieces.
This uses a greedy longest-match-first algorithm to perform tokenization
using the given vocabulary.
For example:
input = "unaffable"
output = ["un", "##aff", "##able"]
Args:
text: A single token or whitespace separated tokens. This should have
already been passed through `BasicTokenizer.
Returns:
A list of wordpiece tokens.
"""
text = convert_to_unicode(text)
output_tokens = []
for token in whitespace_tokenize(text):
chars = list(token)
if len(chars) > self.max_input_chars_per_word:
output_tokens.append(self.unk_token)
continue
is_bad = False
start = 0
sub_tokens = []
while start < len(chars):
end = len(chars)
cur_substr = None
while start < end:
substr = "".join(chars[start:end])
if start > 0:
substr = "##" + substr
if substr in self.vocab:
cur_substr = substr
break
end -= 1
if cur_substr is None:
is_bad = True
break
sub_tokens.append(cur_substr)
start = end
if is_bad:
output_tokens.append(self.unk_token)
else:
output_tokens.extend(sub_tokens)
return output_tokensUnigram Language Model
与WordPiece一样,Unigram Language Model(ULM)同样使用语言模型来挑选子词。不同之处在于,BPE和WordPiece算法的词表大小都是从小到大变化,属于增量法。而Unigram Language Model则是减量法,即先初始化一个大词表,根据评估准则不断丢弃词表,直到满足限定条件。ULM算法考虑了句子的不同分词可能,因而能够输出带概率的多个子词分段。
- 初始时,建立一个足够大的词表(使用一些算法)。一般,可用语料中的所有字符加上常见的子字符串初始化词表,也可以通过BPE算法初始化。
- 针对当前词表,用EM算法求解每个子词在语料上的概率。
- 对于每个子词,计算当该子词被从词表中移除时,总的loss降低了多少,记为该子词的loss。
- 将子词按照loss大小进行排序,丢弃一定比例loss最小的子词(比如20%),保留下来的子词生成新的词表。这里需要注意的是,单字符不能被丢弃,这是为了避免OOV情况。
- 重复步骤2到4,直到词表大小减少到设定范围。
可以看出,ULM会保留那些以较高频率出现在很多句子的分词结果中的子词,因为这些子词如果被丢弃,其损失会很大。 ### 代码
encode代码
def encode_word(word, model):
# word初步分词,model中为-log值
best_segmentations = [{"start": 0, "score": 1}] + [
{"start": None, "score": None} for _ in range(len(word))
]
for start_idx in range(len(word)):
# This should be properly filled by the previous steps of the loop
best_score_at_start = best_segmentations[start_idx]["score"]
for end_idx in range(start_idx + 1, len(word) + 1):
token = word[start_idx:end_idx]
if token in model and best_score_at_start is not None:
score = model[token] + best_score_at_start # 加上start,即前缀对应的损失,log中相加等于原来概率相乘
# If we have found a better segmentation ending at end_idx, we update
if (
best_segmentations[end_idx]["score"] is None
or best_segmentations[end_idx]["score"] > score # score即loss。越小越好
):
best_segmentations[end_idx] = {"start": start_idx, "score": score}
print(token)
print(best_segmentations[end_idx]["score"], score)
print(best_segmentations)
segmentation = best_segmentations[-1]
if segmentation["score"] is None:
# We did not find a tokenization of the word -> unknown
return ["<unk>"], None
# 从后向前的最佳路径,即维特比算法
score = segmentation["score"]
start = segmentation["start"]
end = len(word)
tokens = []
while start != 0:
tokens.insert(0, word[start:end])
next_start = best_segmentations[start]["start"]
end = start
start = next_start
tokens.insert(0, word[start:end])
return tokens, score计算Loss
def compute_loss(model):
loss = 0
for word, freq in word_freqs.items():
_, word_loss = encode_word(word, model)
loss += freq * word_loss
return loss计算score(用于删除token)
import copy
def compute_scores(model):
scores = {}
model_loss = compute_loss(model)
for token, score in model.items():
# We always keep tokens of length 1
if len(token) == 1:
continue
model_without_token = copy.deepcopy(model)
_ = model_without_token.pop(token)
scores[token] = compute_loss(model_without_token) - model_loss
return scores