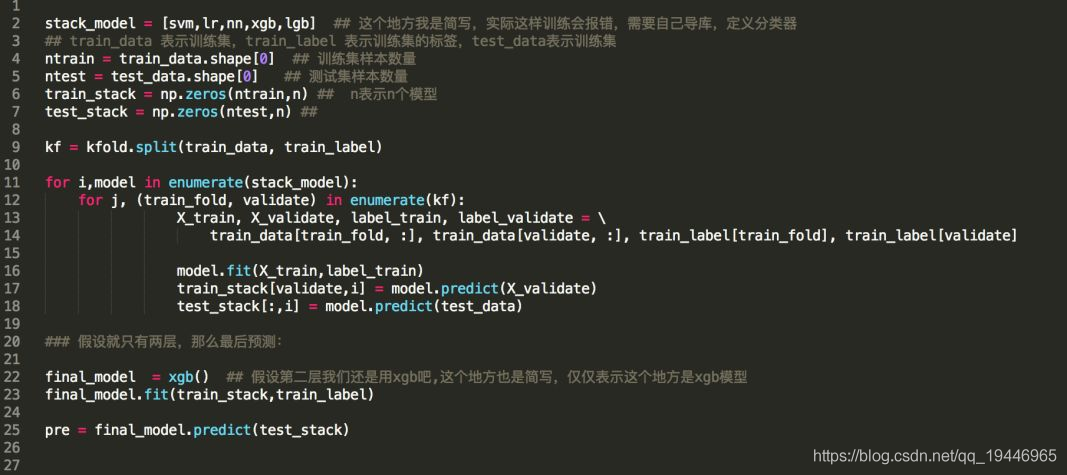
Stacking
Stacking
思想简介
简单得理解,就是对于多个学习器,分别对结果进行预测,然后将预测的结果作为特征,再对结果进行预测。
上一张经典的图: 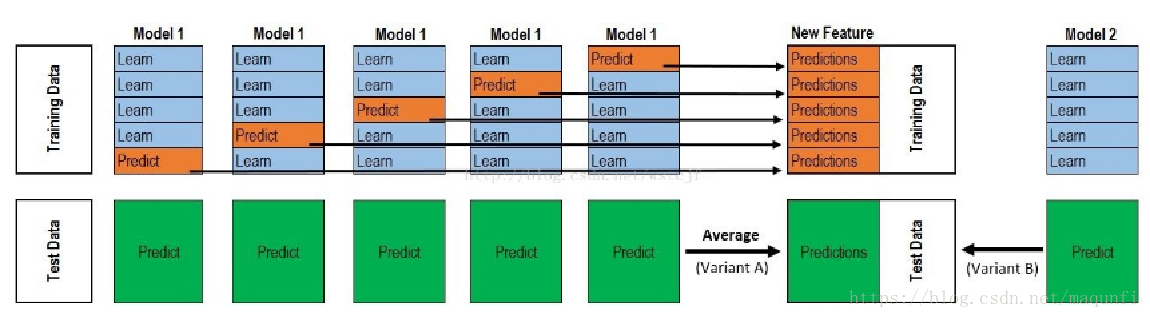 以这个5折stacking为例:
以这个5折stacking为例:
- 首先将所有数据集生成测试集和训练集(假如训练集为10000,测试集为2500行),那么上层会进行5折交叉检验,使用训练集中的8000条作为训练集,剩余2000行作为验证集(橙色)。
- 每次验证相当于使用了蓝色的8000条数据训练出一个模型,使用模型对验证集进行验证得到2000条数据,并对测试集进行预测,得到2500条数据,这样经过5次交叉检验,可以得到中间的橙色的\(5\times 2000\)条验证集的结果(相当于每条数据的预测结果),\(5\times 2500\)条测试集的预测结果。
- 接下来会将验证集的\(5\times 2000\)条预测结果拼接成10000行长的矩阵,标记为A1,而对于\(5\times 2500\)行的测试集的预测结果进行加权平均,得到一个2500一列的矩阵,标记为B1。
- 上面得到一个基模型在数据集上的预测结果A1、B1,这样当我们对3个基模型进行集成的话,相于得到了A1、A2、A3、B1、B2、B3六个矩阵。
- 之后我们会将A1、A2、A3并列在一起成10000行3列的矩阵作为training data,B1、B2、B3合并在一起成2500行3列的矩阵作为testing data,让下层学习器基于这样的数据进行再训练。
- 再训练是基于每个基础模型的预测结果作为特征(三个特征),次学习器会学习训练如果往这样的基学习的预测结果上赋予权重w,来使得最后的预测最为准确。
伪代码