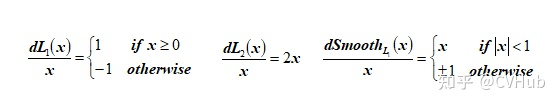Smooth L1 Loss
L1 Loss
也称为Mean Absolute Error,即平均绝对误差(MAE),它衡量的是预测值与真实值之间距离的平均误差幅度,作用范围为0到正无穷。
优点: 对离群点(Outliers)或者异常值更具有鲁棒性。
缺点: 由图可知其在0点处的导数不连续,使得求解效率低下,导致收敛速度慢;而对于较小的损失值,其梯度也同其他区间损失值的梯度一样大,所以不利于网络的学习。
L2 Loss
也称为Mean Squred Error,即均方差(MSE),它衡量的是预测值与真实1值之间距离的平方和,作用范围同为0到正无穷。
优点: 收敛速度快,能够对梯度给予合适的惩罚权重,而不是“一视同仁”,使梯度更新的方向可以更加精确。
缺点: 对异常值十分敏感,梯度更新的方向很容易受离群点所主导,不具备鲁棒性。
提一嘴,真的不理解鲁棒性这个翻译的含义,后来才知道是音译,真的是,毒害了多少人。。理解成稳定性就行。
Smooth L1 Loss
以上两种方法都有各自的优缺点,大部分的情况下其实二者都不使用,因此需要新的损失函数。即平滑的L1损失(SLL)。
SLL通过综合L1和L2损失的优点,在0点处附近采用了L2损失中的平方函数,解决了L1损失在0点处梯度不可导的问题,使其更加平滑易于收敛。此外,在|x|>1的区间上,它又采用了L1损失中的线性函数,使得梯度能够快速下降。
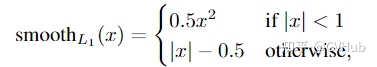
通过对这三个损失函数进行求导可以发现,L1损失的导数为常数,如果不及时调整学习率,那么当值过小时,会导致模型很难收敛到一个较高的精度,而是趋向于一个固定值附近波动。反过来,对于L2损失来说,由于在训练初期值较大时,其导数值也会相应较大,导致训练不稳定。最后,可以发现Smooth L1在训练初期输入数值较大时能够较为稳定在某一个数值,而在后期趋向于收敛时也能够加速梯度的回传,很好的解决了前面两者所存在的问题。