seq2seq
Seq2Seq
(本文只介绍最原始的seq2seq,带有注意力在attention文章中)
RNN
有关RNN
Seq2Seq是典型的Encoder-decoder框架的模型,其中编码器和解码器都采用的RNN模型或者RNN模型的变体:GRU、LSTM等。
一般的RNN模型有几种形式,分别为一对一、一对多、多对一、多对多。
- 一对一: 就是一般的MLP,并不能称之为RNN模型
- 一对多: 典型的例子就是语音生成,比如输入某个值可以由程序生成一段音乐。
- 多对一: 最常见的文本分类或者情感分析就是这个模型架构
- 多对多: 序列标注、NER、分词,大多数标注任务就是用的这个模型架构。而Seq2Seq也属于多对多的任务,不过由于输入和输出的长度可能会不一样,因此采用encoder-decoder的框架,主要思想就是通过encoder将输入的信息编码,然后传入decoder再进行解码得到想要的结果。这常用于生成式的任务,比如说机器翻译、对话系统、文本摘要等等,都可以使用这个框架进行实现。著名的Transformer 就是使用的这个框架。
encoder-decoder 框架
encoder-decoder框架可以看作一种深度学习领域的研究模式,应用场景十分广泛,
文本处理领域的Encoder-Decoder框架可以这么直观地去理解:可以把它看作适合处理由一个句子(或篇章)生成另外一个句子(或篇章)的通用处理模型。对于句子对<Source,Target>,我们的目标是给定输入句子Source,期待通过Encoder-Decoder框架来生成目标句子Target。Source和Target可以是同一种语言,也可以是两种不同的语言。而Source和Target分别由各自的单词序列构成。
\[ Source = <x_1, x_2, \dots, x_m> \\\\ Target = <y_1, y_2, \dots, y_n> \]
Encoder顾名思义就是对输入句子Source进行编码,将输入句子通过非线性变换转化为中间语义表示C:
\[ C = F(x_1, x_2, \dots, x_m) \]
对于解码器Decoder来说,其任务是根据句子Source的中间语义表示C和之前已经生成的历史信息\(y_1,y_2,\dots, y_{i-1}\)来生成i时刻要生成的单词\(y_i\):
\[ y_i = G(C, y_1,y_2,\dots,y_{i-1}) \]
每个yi都依次这么产生,那么看起来就是整个系统根据输入句子Source生成了目标句子Target。如果Source是中文句子,Target是英文句子,那么这就是解决机器翻译问题的Encoder-Decoder框架;如果Source是一篇文章,Target是概括性的几句描述语句,那么这是文本摘要的Encoder-Decoder框架;如果Source是一句问句,Target是一句回答,那么这是问答系统或者对话机器人的Encoder-Decoder框架。由此可见,在文本处理领域,Encoder-Decoder的应用领域相当广泛。
Encoder-Decoder框架不仅仅在文本领域广泛使用,在语音识别、图像处理等领域也经常使用。对于“图像描述”任务来说,Encoder部分的输入是一副图片,Decoder的输出是能够描述图片语义内容的一句描述语。一般而言,文本处理和语音识别的Encoder部分通常采用RNN模型,图像处理的Encoder一般采用CNN模型。
Seq2Seq模型
Seq2Seq模型是输出的长度不确定时采用的模型,这种情况一般是在机器翻译的任务中出现,将一句中文翻译成英文,那么这句英文的长度有可能会比中文短,也有可能会比中文长,所以输出的长度就不确定了。
结构
seq2seq属于encoder-decoder结构的一种,这里看看常见的encoder-decoder结构,基本思想就是利用两个RNN,一个RNN作为encoder,另一个RNN作为decoder。encoder负责将输入序列压缩成指定长度的向量,这个向量就可以看成是这个序列的语义,这个过程称为编码,获取语义向量最简单的方式就是直接将最后一个输入的隐状态作为语义向量C。也可以对最后一个隐含状态做一个变换得到语义向量,还可以将输入序列的所有隐含状态做一个变换得到语义变量。
而decoder则负责根据语义向量生成指定的序列,这个过程也称为解码,最简单的方式是将encoder得到的语义变量作为初始状态输入到decoder的RNN中,得到输出序列。可以看到上一时刻的输出会作为当前时刻的输入,而且其中语义向量C只作为初始状态参与运算,后面的运算都与语义向量C无关。
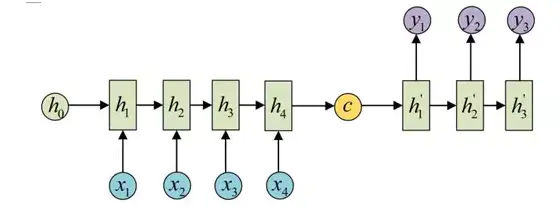
decoder处理方式还有另外一种,就是语义向量C参与了序列所有时刻的运算,如下图,上一时刻的输出仍然作为当前时刻的输入,但语义向量C会参与所有时刻的运算。
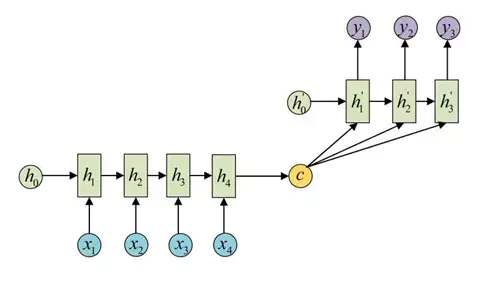 上面的这两种结构是我刚学的时候疑惑的一个地方,因为我在有的地方看到的代码是第一种结构的,而沐神的教程中的结构用的是第二种结构,其实这两种都是可以的。
### 训练
上面的这两种结构是我刚学的时候疑惑的一个地方,因为我在有的地方看到的代码是第一种结构的,而沐神的教程中的结构用的是第二种结构,其实这两种都是可以的。
### 训练
最主要的思路就是语言模型,因为在RNN中,每一个step的输出层的大小就是单词表的大小,要预测最大概率出现的那个词汇,即最大化最有可能是当前输出的单词所在神经元的概率,实际上就是一个多分类问题,使用softmax归一化表示概率。
encoder就是简单的RNN系列模型,前文说的可以有多种方式计算语义向量c,并且c可以有两种方式参与到decoder的计算中。
decoder的主要训练方式就是将前一时刻的结果作为后一时刻的输入,也就是自回归。在训练中的体现是将语料进行错位训练,比如[“你好“
世界”],在训练中decoder中就是输入为[“S” ”你好“
“世界”],而标签也就是实际值为[“你好” “世界” ”E“]
,按照这样的方式进行训练,训练过后,再进行测试,测试的过程就是严格按照前一时刻的输出作为后一时刻的输入,因为这时你也没有要输入的数据。也就是说训练时和测试时的decoder是不一样的。训练的时候我们有真实的数据,而预测的时候没有,只能自产自销,其实就是一个语言模型,叫做条件语言模型。这里引用两张图
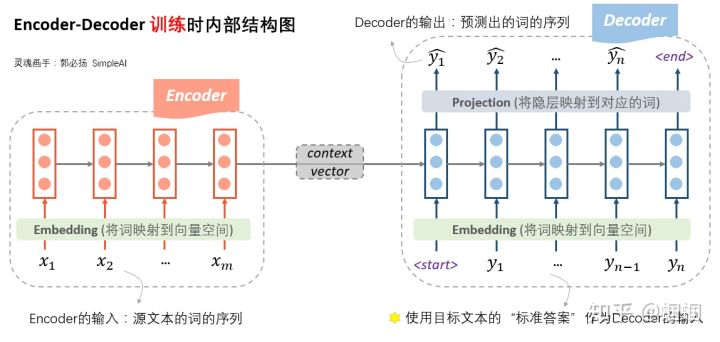
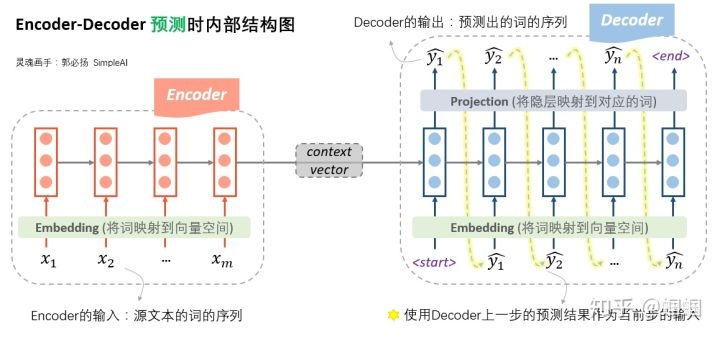
既然是语言模型,可以用极大似然估计最大化输出序列的概率:
\[ \begin{aligned} P(y_1,\dots,y_{T} | x_1, \dots x_T) = \prod_{t=1}^TP(y_t|y_1 , \dots y_{t-1}; c) \end{aligned} \] 在计算损失的时候,我们使用交叉熵作为损失函数,所以我们要找出这个V维向量中,正确预测对应的词的那一维的概率大小\(\hat{p}\),则这一步的损失就是它的负导数\(-log(\hat{p})\),将每一步的损失求和,即得到总体的损失函数:
\[ \begin{aligned} J = -\frac{1}{T}\sum_{i}^Tlog(p(\hat{y_i})) \end{aligned} \] 其中的\(p(\hat{y_i})\)为时间t=i上的正确输出节点的概率值,即softmax值。 其中有三个特殊的标记,一个是S代表句子的开头,E代表句子的结尾,P代表Padding。 ## 束搜索(beam search)
一般来说,用前一步的结果作为下一步的输出,这种方式就是贪心策略,但也存在问题,也就是说每一步最优并不是全局最优,改进的办法就是束搜索。思想很简单,每一步就是多选几个作为候选,最后综合考虑,选出最优的组合。是不是和HMM中的维特比算法很像呢?
以下为束搜索的步骤: - 首先需要设定一个候选集的大小beam size=k。 -
每一步的开始,我们从每个当前输入对应的所有可能输出,计算每一条路的序列得分
- 保留序列得分最大的k个作为下一步的输入 -
不断重复以上步骤,直至结束,选择序列得分最大的那个序列作为最终结果。
其中序列得分为: \[
score(y_1,y_2, \dots y_t) = \sum_{i=1}^t \log P(y_i|y_1,y_2,\dots
y_{i-1};x)
\] 过程如图所示: 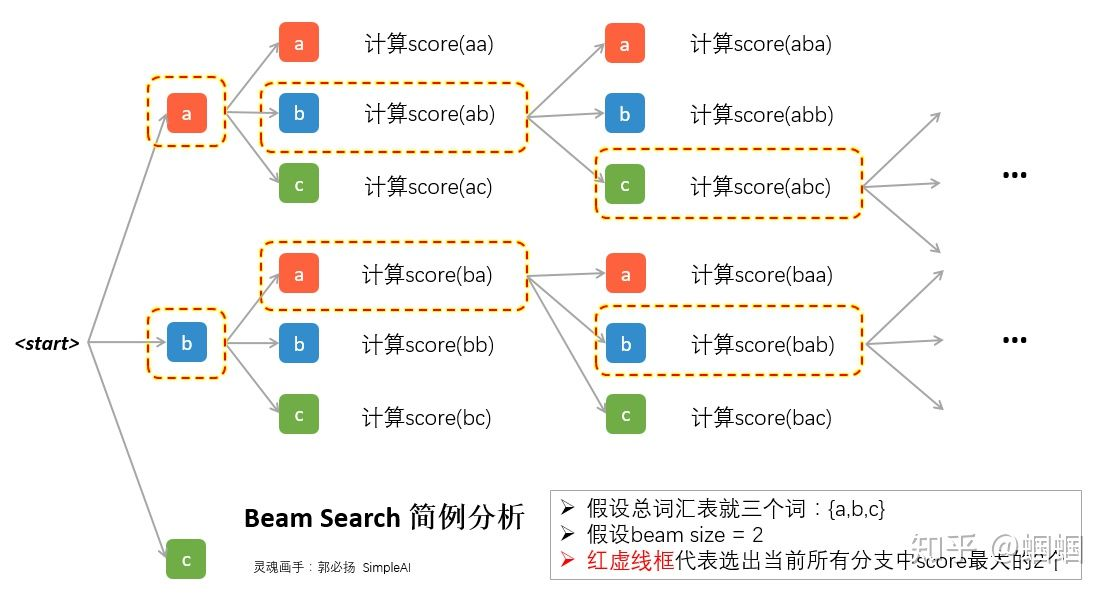
评价标准
BLUE指标
BLEU,全称是Bilingual Evaluation Understudy,它的主要思想是基于N-gram等特征来比较人工翻译和机器翻译结果的相似程度。 我们将BLEU定义为:
\[ \exp \left(\min\left(0,1-\frac{len_{\text {label }}}{len_{\text {pred }}}\right)\right) \prod_{n=1}^{k} p_{n}^{1 / 2^{n}} \]
长的 \(n\) 元语法。另外, 用 \(p_{n}\) 表示 \(n\) 元语法的精确度, 它是两个数量的比值:第一个是预测序 列与标签序列中匹配的 \(n\) 元语法的数量, 第二个是预测序列中 \(n\) 元语法的数量的比率。具体 地说, 给定标签序列 \(A 、 B 、 C 、 D 、 E 、 F\) 和预测序列 \(A 、 B 、 B 、 C 、 D\), 我们有 \(p_{1}=4 / 5 、 p_{2}=3 / 4 、 p_{3}=1 / 3\) 和 \(p_{4}=0\) 。 根据 (9.7.4)中BLEU的定义,当预测序列与标签序列完全相同时, BLEU为 1 。 此外, 由于 \(n\) 元语法越长则匹配难度越大, 所以BLEU为更长的 \(n\) 元语法的精确度分配更大的权重。具体 来说, 当 \(p_{n}\) 固定时, \(p_{n}^{1 / 2^{n}}\) 会随着 \(n\) 的增长而增加(原始论文使用 \(p_{n}^{1 / n}\) )。而且, 由于预测 的序列越短获得的 \(p_{n}\) 值越高, 所以 (9.7.4)中乘法项之前的系数用于惩罚较短的预测序列。 例如, 当 \(k=2\) 时,给定标签序列 \(A 、 B 、 C 、 D 、 E 、 F\) 和预测序列 \(A 、 B\) ,尽管 \(p_{1}=p_{2}=1\) , 惩罚因子 \(\exp (1-6 / 2) \approx 0.14\) 会降低BLEU。
代码
# code by Tae Hwan Jung @graykode
import numpy as np
import torch
import torch.nn as nn
# S: Symbol that shows starting of decoding input
# E: Symbol that shows starting of decoding output
# P: Symbol that will fill in blank sequence if current batch data size is short than time steps
def make_batch():
input_batch, output_batch, target_batch = [], [], []
for seq in seq_data:
for i in range(2):
seq[i] = seq[i] + 'P' * (n_step - len(seq[i]))
input = [num_dic[n] for n in seq[0]]
output = [num_dic[n] for n in ('S' + seq[1])]
target = [num_dic[n] for n in (seq[1] + 'E')]
input_batch.append(np.eye(n_class)[input])
output_batch.append(np.eye(n_class)[output])
target_batch.append(target) # not one-hot
# make tensor
return torch.FloatTensor(input_batch), torch.FloatTensor(output_batch), torch.LongTensor(target_batch)
# make test batch
def make_testbatch(input_word):
input_batch, output_batch = [], []
input_w = input_word + 'P' * (n_step - len(input_word))
input = [num_dic[n] for n in input_w]
output = [num_dic[n] for n in 'S' + 'P' * n_step]
input_batch = np.eye(n_class)[input]
output_batch = np.eye(n_class)[output]
return torch.FloatTensor(input_batch).unsqueeze(0), torch.FloatTensor(output_batch).unsqueeze(0)
# Model
class Seq2Seq(nn.Module):
def __init__(self):
super(Seq2Seq, self).__init__()
self.enc_cell = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5)
self.dec_cell = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5)
self.fc = nn.Linear(n_hidden, n_class)
def forward(self, enc_input, enc_hidden, dec_input):
enc_input = enc_input.transpose(0, 1) # enc_input: [max_len(=n_step, time step), batch_size, n_class]
dec_input = dec_input.transpose(0, 1) # dec_input: [max_len(=n_step, time step), batch_size, n_class]
# enc_states : [num_layers(=1) * num_directions(=1), batch_size, n_hidden]
_, enc_states = self.enc_cell(enc_input, enc_hidden)
# outputs : [max_len+1(=6), batch_size, num_directions(=1) * n_hidden(=128)]
outputs, _ = self.dec_cell(dec_input, enc_states)
model = self.fc(outputs) # model : [max_len+1(=6), batch_size, n_class]
return model
if __name__ == '__main__':
n_step = 5
n_hidden = 128
char_arr = [c for c in 'SEPabcdefghijklmnopqrstuvwxyz']
num_dic = {n: i for i, n in enumerate(char_arr)}
seq_data = [['man', 'women'], ['black', 'white'], ['king', 'queen'], ['girl', 'boy'], ['up', 'down'], ['high', 'low']]
n_class = len(num_dic)
batch_size = len(seq_data)
model = Seq2Seq()
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
input_batch, output_batch, target_batch = make_batch()
for epoch in range(5000):
# make hidden shape [num_layers * num_directions, batch_size, n_hidden]
hidden = torch.zeros(1, batch_size, n_hidden)
optimizer.zero_grad()
# input_batch : [batch_size, max_len(=n_step, time step), n_class]
# output_batch : [batch_size, max_len+1(=n_step, time step) (becase of 'S' or 'E'), n_class]
# target_batch : [batch_size, max_len+1(=n_step, time step)], not one-hot
output = model(input_batch, hidden, output_batch)
# output : [max_len+1, batch_size, n_class]
output = output.transpose(0, 1) # [batch_size, max_len+1(=6), n_class]
loss = 0
for i in range(0, len(target_batch)):
# output[i] : [max_len+1, n_class, target_batch[i] : max_len+1]
loss += criterion(output[i], target_batch[i])
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
loss.backward()
optimizer.step()
# Test
def translate(word):
input_batch, output_batch = make_testbatch(word)
# make hidden shape [num_layers * num_directions, batch_size, n_hidden]
hidden = torch.zeros(1, 1, n_hidden)
output = model(input_batch, hidden, output_batch)
# output : [max_len+1(=6), batch_size(=1), n_class]
predict = output.data.max(2, keepdim=True)[1] # select n_class dimension
decoded = [char_arr[i] for i in predict]
end = decoded.index('E')
translated = ''.join(decoded[:end])
return translated.replace('P', '')
print('test')
print('man ->', translate('man'))
print('mans ->', translate('mans'))
print('king ->', translate('king'))
print('black ->', translate('black'))
print('upp ->', translate('upp'))