Routine:A Structural Planning Framework for LLM Agent System in Enterprise
论文深度解读:从“混沌”到“有序”,Routine框架如何驯服企业级AI智能体
当前,以大型语言模型(LLM)为核心的自主智能体(Autonomous Agents)正以前所未有的速度发展,展现出在数据分析、人机交互等领域的巨大潜力。然而,当我们将这些通用智能体置于规则严密、流程复杂的企业环境中时,往往会遭遇“水土不服”的窘境。论文开篇就指出了这一核心挑战:
The deployment of agent systems in an enterprise environment is often hindered by several challenges: common models lack domain-specific process knowledge, leading to disorganized plans, missing key tools, and poor execution stability. (在企业环境中部署智能体系统常常受到几个挑战的阻碍:通用模型缺乏领域特定的流程知识,导致规划混乱、关键工具缺失以及执行稳定性差。)
通用大模型如同一个拥有渊博知识但缺乏特定公司工作经验的“实习生”,在面对企业内部复杂的工具链和业务逻辑时,常常会“手足无措”,无法稳定、准确地完成多步骤任务。
为了解决这一难题,论文作者提出了 Routine 框架,其本质是一个结构化的、面向任务的规划脚本。它不再让模型在运行时进行完全自主、不可预测的“自由发挥”,而是像一份详尽的“标准作业程序”(SOP),清晰地指导模型每一步应该做什么、调用哪个工具。这标志着一种从追求“完全自主”到强调“可靠可控”的范式转变,而后者恰恰是企业应用最看重的品质。
Routine的设计精妙之处在于它将一个复杂的智能体任务清晰地解耦为两个核心环节:
- 规划(Planning):这个环节负责生成Routine。它可以由领域专家提供草稿,再由一个能力强大的大模型(如GPT-4o)进行优化和补全,生成包含明确步骤、工具和参数描述的结构化计划。这一过程可以离线完成,确保了计划的质量和周密性。
- 执行(Execution):这个环节由一个相对轻量级、经过专门微调的模型负责。它的任务不再是复杂的推理和规划,而仅仅是严格遵循Routine的指令,一步步调用工具并传递参数。
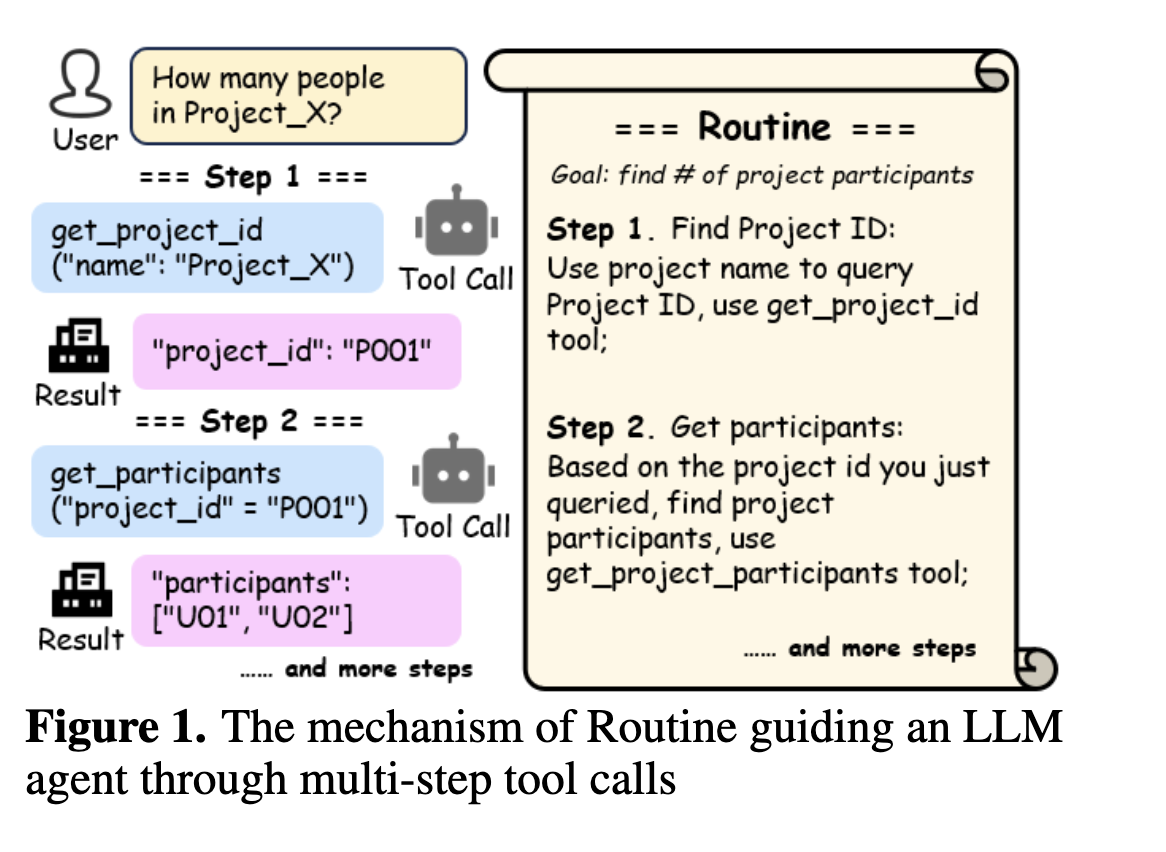
这种“规划与执行分离”的架构带来了显而易见的优势:它允许我们用最强大的大脑(大模型+专家)来做最复杂的规划,同时用一个更经济、更高效的小模型来处理高频的执行任务,实现了能力与成本的最佳平衡。
为了支撑这套框架,论文还设计了一套完整的系统架构,如Figure
2所示,包括规划模块、执行模块、工具模块(MCP
Server)和创新的双重内存模块(Memory
Module)。其中,内存模块的设计尤其值得称道: *
程序内存(Procedure
Memory):用于存储和检索整个Routine库。当用户提出请求时,系统能快速匹配到最合适的Routine。
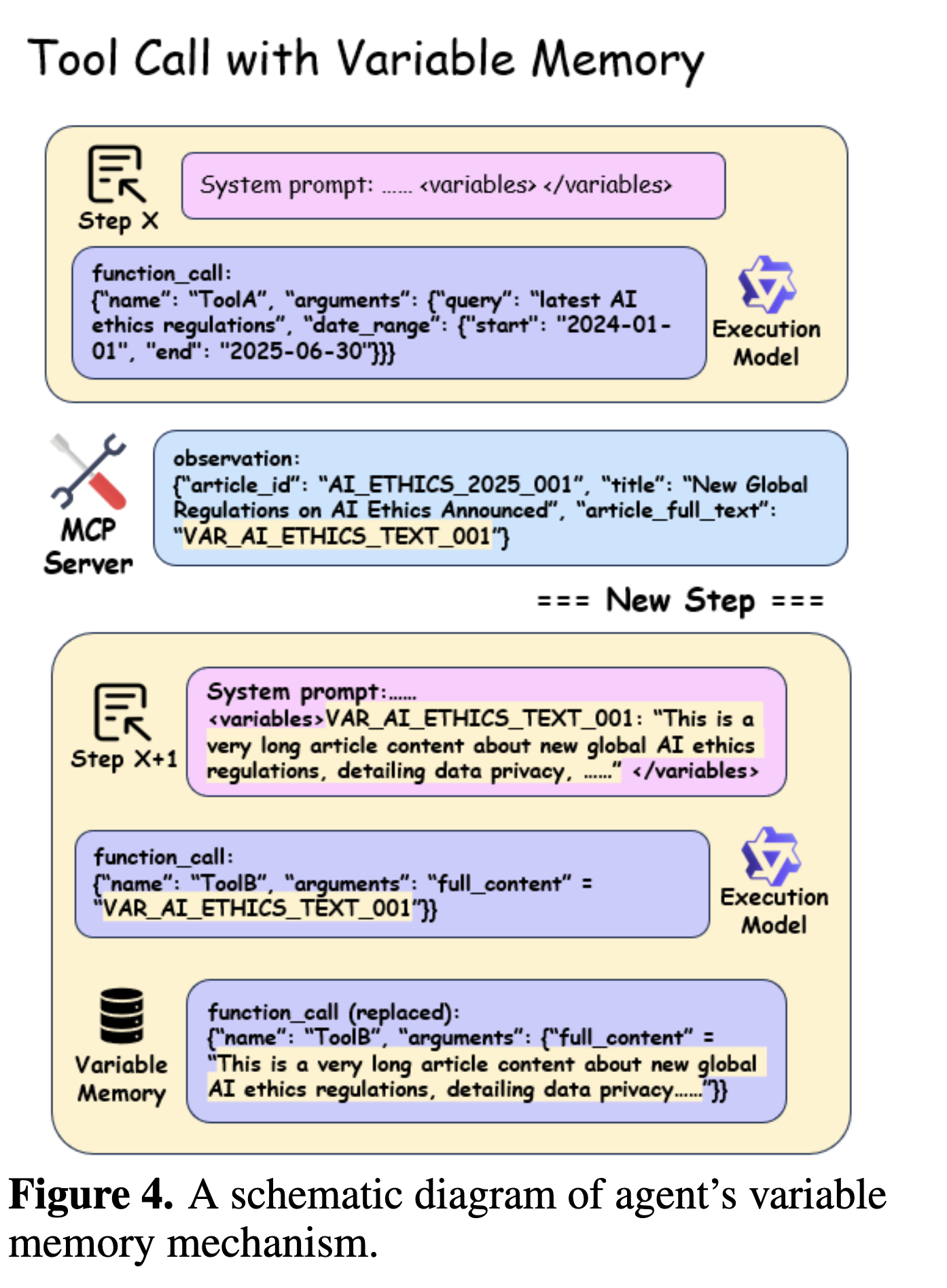
* 变量内存(Variable
Memory):这是一个巧妙的上下文管理机制。当工具调用返回过长的结果(如一整篇文章)时,系统会将其存入变量内存,并只在上下文中保留一个简短的键(如VAR_AI_ETHICS_TEXT_001)。这极大地压缩了上下文长度,降低了token消耗,并减少了长文本可能导致的模型“分心”或语法错误。
当然,仅有框架是不够的,如何让模型真正“学会”使用Routine是关键。为此,论文提出了两种互补的训练策略: 1. 通用Routine遵循能力训练:使用一个开源的多工具数据集(BUTTON),通过GPT-4o生成对应的Routine,然后用这些数据对模型进行微调。目的是让模型学会理解并遵循Routine这种结构化指令的“语法”。 2. 特定场景知识蒸馏(Knowledge Distillation):这是论文的另一大亮点。针对具体场景(如文中的HR Agent),研究者让“教师模型”(GPT-4o)在Routine的指导下,生成大量高质量的、包含完整多步工具调用的“完美范例”。然后,用这些“蒸馏”出的数据去微调一个“学生模型”(如Qwen3-14B)。这一过程,本质上是将蕴含在Routine中的流程知识和教师模型的强大执行能力,“烘焙”进了轻量级模型的参数中。
实验结果是惊人的。论文在一个包含25个工具的真实HR Agent场景中进行了严谨的测试。关键数据显示(见Table 2),在没有Routine指导时,即便是强大的GPT-4o,其多步工具调用的端到端准确率也仅有41.1%。而引入Routine后,其准确率飙升至96.3%!对于开源模型Qwen3-14B,效果同样显著,准确率从32.6%提升到83.3%。
更具启发性的是,经过特定场景知识蒸馏后,轻量级的Qwen3-14B模型在没有Routine指导的情况下,准确率也能达到90.2%,当再次获得Routine指导时,准确率更是高达95.5%,几乎追平了GPT-4o。这雄辩地证明了,Routine框架不仅能作为一种外部“提示”来指导模型,还能作为一种有效的“知识载体”,通过蒸馏将领域知识内化到小模型中,从而构建出高稳定、低成本的企业级智能体。
总而言之,这篇论文为业界提供了一份极具操作性的蓝图,它巧妙地平衡了智能体的自主性与可靠性,通过结构化规划、执行解耦和知识蒸馏等一系列创新方法,为大模型在严肃、复杂的企业场景中大规模落地铺平了道路,真正向着“AI for Process”(AI赋能流程)的技术愿景迈出了坚实的一步。
接下来,我将按照您提出的六个问题,进行更详细的解读。
### 1. 论文的研究目标是什么?想要解决什么实际问题?这个问题对于行业发展有什么重要意义?
- 研究目标:
- 核心目标:设计并验证一个名为 Routine 的结构化规划框架,旨在显著提升LLM智能体在执行特定领域、多步骤工具调用任务时的稳定性、准确性和可靠性。
- 延伸目标:探索如何通过该框架,使得轻量级、低成本的本地化模型能够在特定企业场景中达到甚至逼近顶级闭源模型的性能水平。
- 解决的实际问题:
- 问题:当前通用大模型在企业环境中落地时面临的“最后一公里”难题。即便是最先进的模型,在面对企业内部特有的、复杂的业务流程和工具集时,也常常因为缺乏专门的领域知识而表现出“规划混乱、执行不稳”的问题。例如,模型可能会选择错误的工具、遗漏关键步骤(如权限验证),或在多步任务中途“迷失方向”,导致任务失败。
- 具体场景:想象一下一个企业HR智能体,需要处理“查询某员工上个季度的绩效、其所在部门的平均绩效、并生成一份对比报告”的请求。这涉及查询员工信息、查询部门数据、调用分析工具、调用报告生成工具等多个步骤,且步骤之间存在依赖关系。通用模型很可能在这个链条的某一步出错。
- 对行业发展的重要性:
- 推动AI在企业核心业务中的应用:目前,AI在企业的应用多集中在客服、内容生成等外围环节。要深入到ERP、CRM、SCM等核心业务流程,系统的可靠性是第一要求。Routine框架通过提供一种可控、可预测的执行模式,极大地增强了企业对AI智能体的信任,是AI从“玩具”走向“生产力工具”的关键一步。
- 降低企业部署AI的门槛和成本:顶级大模型的API调用费用高昂,且存在数据隐私风险。Routine框架通过知识蒸馏,使得企业可以部署性能媲美大模型、但成本更低、数据更安全的本地化小模型。这对于广大中小型企业或对数据安全要求极高的行业(如金融、医疗)意义重大。
- 催生新的技术生态和商业模式:围绕Routine的设计、管理、优化和分发,可能会诞生新的“智能体流程编排平台”、“领域知识蒸馏服务”等,为AI产业带来新的增长点。
### 2. 论文提出了哪些新的思路、方法或模型?跟之前的方法相比有什么特点和优势?
论文的核心创新在于提出了一整套系统性的方法论,而不仅仅是单一模型。
新的思路、方法与模型:
- Routine框架本身:
- 特点:它是一种人类可读、机器可执行的中间表示(Intermediate Representation)。它将模糊的自然语言任务意图,转化为结构化的、包含明确步骤、描述、工具和I/O的计划。
- 优势:与之前依赖模型在运行时进行“黑盒”规划的Plan-and-Act模式相比,Routine将“Plan”过程前置和显式化,使得整个工作流变得透明、可调试、可维护。开发者可以轻易地修改、增加或删除Routine中的步骤。
- “规划-执行”解耦架构(Decoupling Planning and
Execution):
- 特点:系统在架构上明确分离了负责生成Routine的规划模块(高能力大模型)和负责执行Routine的执行模块(轻量级小模型)。
- 优势:这是对资源的最优化配置。复杂的、低频的规划任务由“最强大脑”完成,保证了计划的质量;而简单的、高频的执行任务由“经济小脑”完成,保证了效率和成本。这与传统软件工程中“控制面”与“数据面”分离的思想不谋而合。
- AI辅助的Routine生成与优化流程:
- 特点:论文展示了一个半自动化的流程(见Figure
3),即领域专家只需提供一个简单的草稿(
Routine Draft),强大的规划模型就能自动将其丰富、细化为一个完整的Routine。 - 优势:这大大降低了创建和维护Routine的门槛和工作量,使其具有更好的可扩展性,避免了完全依赖人工编写的瓶颈。
- 特点:论文展示了一个半自动化的流程(见Figure
3),即领域专家只需提供一个简单的草稿(
- 双重内存机制(Dual Memory):
- 程序内存(Procedure Memory):这类似于一个“流程库”,负责存储和检索Routines。
- 变量内存(Variable Memory):这是针对LLM上下文长度限制的精巧设计,通过键值对的方式传递长信息。
- 优势:相比于将所有信息(工具定义、历史记录等)一股脑塞进Prompt的粗暴方式,这种精细化的内存管理机制更加高效和稳定,能有效避免因上下文过长导致的性能下降和成本激增。
- 面向特定场景的知识蒸馏管道:
- 特点:构建了一个“教师(GPT-4o + Routine)-> 范例 -> 学生(Qwen3-14B)”的知识转移链条。
- 优势:这是一种非常高效的领域知识迁移方法。它证明了程序性的、流程性的知识(
procedural knowledge)同样可以通过蒸馏被模型“学会”,而不仅限于事实性知识。这使得训练高度定制化的、专业的“小钢炮”模型成为可能。
- Routine框架本身:
### 3. 论文通过什么实验来验证所提出方法的有效性?实验是如何设计的?实验数据和结果如何?
论文的实验设计非常严谨、扎实,紧密围绕其核心主张展开。
实验设置:
- 场景:一个真实的企业HR智能体应用。这个场景足够复杂,因为它包含:
- 多样的子任务:7个不同的子场景,最终可分解为10个无分支的Routines。
- 丰富的工具集:一个包含25个不同功能(数据查询、权限验证、模型生成等)的MCP服务器。
- 真实的依赖关系:任务步骤之间存在参数依赖,必须按特定顺序执行。
- 评估框架:采用了开源的伯克利函数调用排行榜(BFCL) 的评估方法,基于抽象语法树(AST)进行分层评估,能精确地将错误归因于结构错误(Structural Error)、工具选择错误(Tool Selection Error) 和 参数错误(Parameter Error)。
- 场景:一个真实的企业HR智能体应用。这个场景足够复杂,因为它包含:
实验设计与关键数据:
- 核心有效性验证(Impact of Routine):
- 设计:对比了同一模型在三种不同配置下的表现:无Routine(基线)、有线性Routine、有带分支的Routine。
- 结果:如Table 2所示,这是最有说服力的结果。 >
Without Routine guidance, all baseline models performed poorly, with
none exceeding 50% overall accuracy. … In particular, GPT-4-Turbo’s
performance approached perfection, and the Qwen series models also
demonstrated significant gains. >
(在没有Routine指导的情况下,所有基线模型表现不佳,整体准确率均未超过50%……
特别是,GPT-4-Turbo的表现接近完美,Qwen系列模型也显示出显著增益。)
- 关键数据:Qwen3-14B 的准确率从 32.6% 跃升至 83.3%,提升了约 50个百分点。这证明了Routine框架的普适性和巨大价值。错误分析表明,性能提升主要来源于工具选择准确率的大幅提高。
- 模型训练效果验证(Impact of Model Training):
- 设计:对比了原始模型、经过“通用Routine遵循训练”的模型、以及经过“特定场景知识蒸馏”的模型在不同配置下的表现。
- 结果:
- 通用训练能提升模型在有Routine指导时的执行力,但在无Routine时反而会下降,说明模型被“训练”成了一个忠实的执行者,而非规划者。
- 知识蒸馏的效果非常惊艳。经过蒸馏的Qwen3-14B,在没有Routine的情况下,准确率达到了90.2%,远超其原始基线(32.6%),甚至超过了有Routine指导时的原始表现(83.3%)。这表明领域知识成功内化了。
- 消融研究(Ablation Study):
- Routine组件影响(Table 3):移除了Routine中的“工具名称”,只保留步骤描述,模型的准确率大幅下降(Qwen3-14B从79.1%降至69.5%)。这证明了明确的工具指令是保证执行准确性的核心要素。
- Routine生成方式影响(Table 4):对比了用户草稿、AI优化、人工标注三种Routine。结果显示,AI优化后的Routine(AI Optimization) 已经能达到很高的水平(Qwen3-14B为76.7%),非常接近甚至在某些模型上超过了完美的人工标注(Human Annotation)版本(83.3%),证明了AI辅助生成流程的巨大潜力。
- Routine数量影响(Table 5):在Prompt中提供多个候选Routine(1个正确,其余为干扰项)会显著降低模型性能。这强调了程序内存(Procedure Memory) 进行高精度检索的重要性,一次只给模型最相关的那个Routine才是最佳实践。
- 核心有效性验证(Impact of Routine):
### 4. 结合大模型领域的当前学术理解,未来在该研究方向上还有哪些值得进一步探索的问题和挑战?
这篇论文打开了一扇通往可靠企业智能体的大门,同时也揭示了更多值得探索的方向。
值得探索的问题和挑战:
- Routine的动态适应与自主学习:
- 挑战:目前的Routine是静态的,当企业业务流程或工具集发生变化时,需要人工或半自动地更新Routine。这是一个可扩展性的瓶颈。
- 探索方向:结合强化学习(Reinforcement Learning)。智能体可以在执行Routine的基础上进行探索(Exploration),如果发现了更优的路径或成功处理了异常,就可以通过奖励信号来更新或生成新的Routine。这篇论文的第6节也提到了这一点,这是从“死板执行”到“动态进化”的关键一步。
- 从文档到Routine的全自动生成:
- 挑战:目前Routine的生成仍需要专家提供草稿。如何实现“零人工”的全自动化?
- 探索方向:训练一个专门的“流程理解模型”,能够自动阅读企业的内部文档(如SOP、API文档、知识库),并直接从中抽取出结构化的Routine。这需要强大的文档理解、实体关系抽取和逻辑推理能力。
- 层级化与多智能体协作(Hierarchical & Multi-Agent
Systems):
- 挑战:对于极其复杂的企业级任务(如全流程的供应链管理),单一的线性Routine可能过于冗长和脆弱。
- 探索方向:构建一个层级化的多智能体系统。一个“总指挥”智能体负责顶层规划,将任务分解,并生成宏观的Routine;然后将子任务分配给多个高度专业化的“执行者”智能体,每个执行者再依据自己的、更具体的Routine来完成任务。这能极大提升系统的模块化和鲁棒性。
- Routine的动态适应与自主学习:
可能催生的新技术和投资机会:
- 企业智能体流程编排(Orchestration)平台:提供可视化界面,让业务人员可以通过拖拉拽的方式设计、测试和管理Routine库,并一键部署到不同的执行模型上。
- 领域知识蒸馏即服务(Knowledge Distillation as a Service):专门为企业提供服务,利用其私有数据和业务流程,通过类似本文的蒸馏管道,为其训练出轻量、高效、安全的定制化智能体模型。
- “AI流程挖掘”工具:能够分析企业现有的操作日志和数据流,自动发现并生成最优的业务流程(Routines),帮助企业实现流程再造和自动化。
### 5. 退一步,从批判的视角看,这篇论文还存在哪些不足及缺失?
尽管这篇论文非常出色,但从批判性的学术角度审视,仍有一些可以探讨的局限性。
潜在的不足与缺失:
- 灵活性与泛化能力的权衡:
- 不足:Routine框架的核心优势是其结构性和稳定性,但这同时牺牲了智能体的灵活性和处理未知情况的能力。如果用户提出了一个偏离所有已知Routine的“边缘请求”,系统可能会束手无策或错误地匹配到一个不完全适用的Routine。论文承认了这是一个权衡,但未深入探讨如何优雅地处理“Routine Miss”的情况。
- Routine创建与维护的隐性成本:
- 不足:虽然论文提出了AI辅助优化,但整个流程的起点仍然是“专家草稿”。对于拥有成百上千个业务流程的大型企业而言,创建和持续维护这个“Routine库”的真实人力成本和时间成本可能非常高昂。论文对此没有进行量化分析。
- 实验场景的单一性:
- 不足:尽管HR场景很典型,但它仍然是相对封闭和确定的。在一些更加开放和动态的领域,比如市场分析(需要实时调用外部API、处理非结构化新闻)、软件开发(代码库和需求频繁变更),Routine框架的有效性是否依然如此出色?需要更多样化的案例来验证其普适性。
- 对“程序内存”的检索精度要求过高:
- 存疑之处:论文的消融研究(Table 5)表明,即使只增加一个干扰Routine,模型的性能也会大幅下降。这反向说明,系统中的“程序内存”模块必须要有极高的检索精度,确保每次都能“又快又准”地找到唯一正确的Routine。然而,论文并未详细阐述这个高精度检索模块是如何实现的,这是一个非平凡的挑战。
- 灵活性与泛化能力的权衡:
### 6. 我希望从这篇论文中找一些拿来即用的创新想法,我应该从这篇论文中重点学什么?
这篇论文是理论与实践结合的典范,充满了可以借鉴的智慧。
重点学习与启发:
- 拥抱务实主义:可靠性优于完全自主性。
- 启发:在企业级应用中,不要盲目追求一个无所不能、完全自主的“黑盒”AI。一个行为可预测、结果稳定、过程可追溯的系统远比一个时而惊艳、时而犯错的天才更有价值。将复杂任务流程化、结构化,是让AI落地的关键。
- 分而治之:解耦复杂问题。
- 启发:“规划与执行分离”的思想极具普适性。在设计任何复杂AI系统时,都可以思考:哪些是需要强大推理能力的、低频的“决策任务”?哪些是需要高效稳定执行的、高频的“操作任务”?尝试为它们匹配不同能力和成本的模型或模块。
- 知识蒸馏是实现“小模型、大能力”的利器。
- 启发:当你想让一个小模型掌握特定领域的复杂能力时,不要只想着喂给它原始数据。可以先用一个大模型(或者规则引擎、或者人类专家)在这个领域生成大量“高质量的解题过程”,然后让小模型去学习这些“过程”,而不是“结果”。这是一种高效的知识迁移模式。
- 中间表示(IR)的力量。
- 启发:Routine本质上是一种精心设计的IR。一个好的IR能够成为系统不同模块之间清晰的“沟通语言”,同时兼具人类可读性和机器可处理性。在你自己的项目中,思考一下是否也能设计一个类似的IR来解耦系统、降低复杂度。
- 拥抱务实主义:可靠性优于完全自主性。
需要补充的背景知识:
- LLM Agent主流框架:了解像 ReAct (Reason+Act)、Plan-and-Act 等基础的智能体工作模式,以便更好地理解Routine框架的创新之处。
- 模型微调技术:特别是 LoRA (Low-Rank Adaptation),了解其原理,明白为什么可以用较低的成本对大模型进行有效微调。
- 知识蒸馏(Knowledge Distillation):理解其基本概念,即“教师模型”如何将知识转移给“学生模型”。
- 企业业务流程管理(BPM):了解企业中标准作业程序(SOP)、工作流等概念,你会发现Routine的思想与之有异曲同工之妙,它是AI时代的动态SOP。