remove_padding
即 packing,将不同长度的序列紧凑存储,避免填充,减少不必要的计算和存储,提升效率。
动机
sft进行微调,因为gpu是并行计算的,所以如果一个batch里面的数据,每条数据长度不相等,就需要对数据进行truncation(截断)和padding(pad数据到相同的seq_length)。显然,如果使用了padding,那么一个batch里面,就会有很多的pad_token,这些pad_token输入进入到了模型,但是却没有样本训练,造成了计算量的浪费。
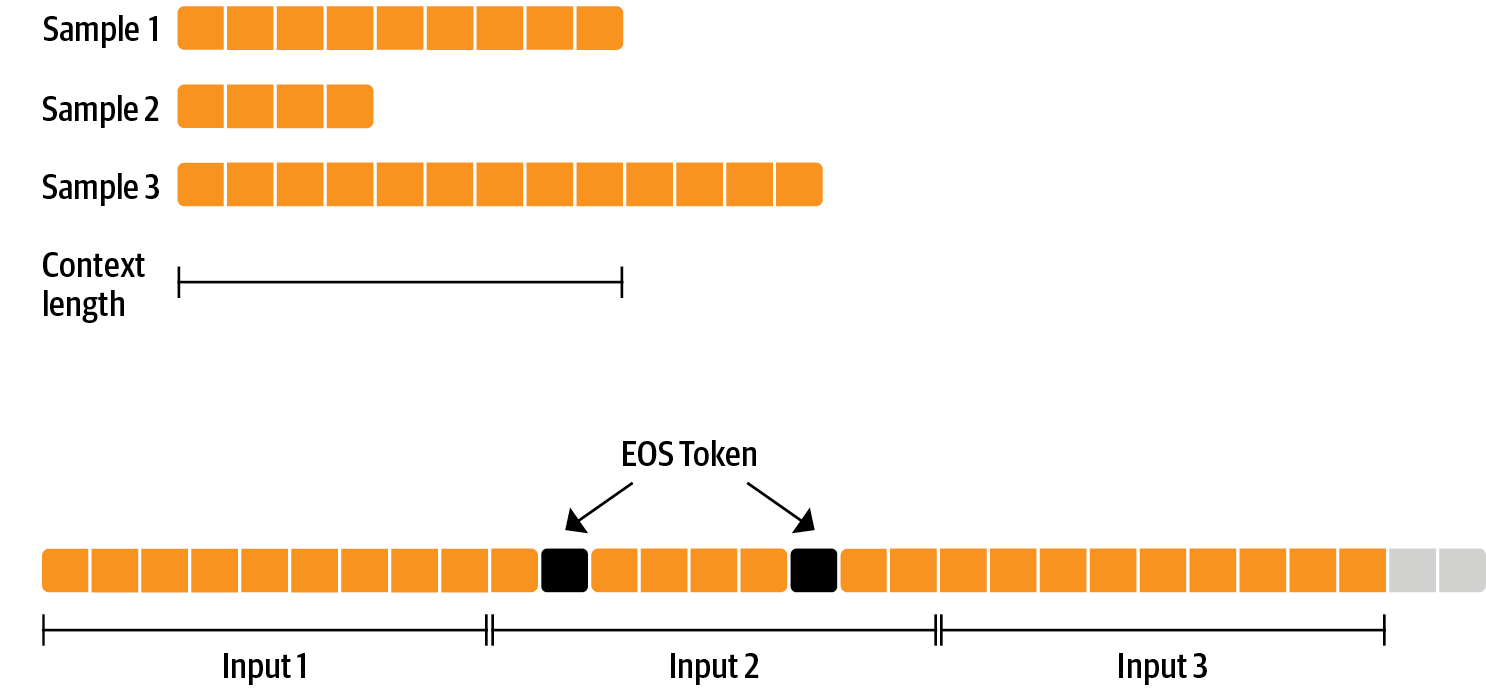
因此,对于这些长度不相等的样本,就可以使用packing(类似于打包),把这些样本拼接成长度相等的文本(比如20480, 4096, 8192)等长度。这样就能够是样本全部训练,增加了样本的计算效率。如图所示。每个样本之间不等长,但是可以使用eos_token进行拼接,达到加速训练的目的
带来的问题和解决方案(理论上)
如果使用了packing,需要考虑两个问题:attention和位置编码。相比于不使用packing,使用packing导致:
- atteniton有问题:本来我只需要和sample1的token计算attention,现在packing以后,我的attention不仅仅是sample1内部计算。现在是sample1,sample2,sample3,通通一起计算attention。这样是不是会有问题?
- 位置编码:本来sample1的位置编码是从0开始的,现在我sample1,2,3一起packing,那sample2,3的位置编码就变了,无法和单条样本训练一致。
解决方案: -
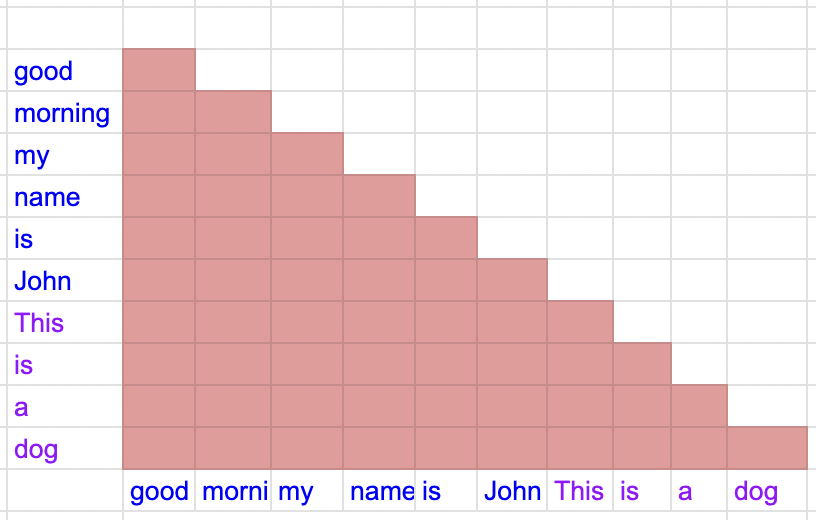
将packing中的attention方式进行修改(每条样本只和自己内部做attention),如下图
 -
将packing的位置编码,修改成和不使用packing一样的位置编码。
-
将packing的位置编码,修改成和不使用packing一样的位置编码。
代码做法
引用 verl 中 tests 的代码:
def test_hf_casual_models():
batch_size = 4
seqlen = 128
response_length = 127
for config in test_configs:
# config = AutoConfig.from_pretrained(test_case)
with torch.device("cuda"):
model = AutoModelForCausalLM.from_config(
config=config, torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2"
)
model = model.to(device="cuda")
breakpoint()
input_ids = torch.randint(low=0, high=config.vocab_size, size=(batch_size, seqlen), device="cuda")
attention_mask = create_random_mask(
input_ids=input_ids,
max_ratio_of_left_padding=0.1,
max_ratio_of_valid_token=0.8,
min_ratio_of_valid_token=0.5,
)
position_ids = compute_position_id_with_mask(
attention_mask
) # TODO(sgm): we can construct the position_ids_rmpad here
input_ids_rmpad, indices, *_ = unpad_input(
input_ids.unsqueeze(-1), attention_mask
) # input_ids_rmpad (total_nnz, ...)
input_ids_rmpad = input_ids_rmpad.transpose(0, 1) # (1, total_nnz)
# unpad the position_ids to align the rotary
position_ids_rmpad = index_first_axis(
rearrange(position_ids.unsqueeze(-1), "b s ... -> (b s) ..."), indices
).transpose(0, 1)
# input with input_ids_rmpad and postition_ids to enable flash attention varlen
logits_rmpad = model(
input_ids_rmpad, position_ids=position_ids_rmpad, use_cache=False
).logits # (1, total_nnz, vocab_size)
origin_logits = model(
input_ids=input_ids, attention_mask=attention_mask, position_ids=position_ids, use_cache=False
).logits
origin_logits_rmpad, origin_logits_indices, *_ = unpad_input(origin_logits, attention_mask)
logits_rmpad = logits_rmpad.squeeze(0)
log_probs = log_probs_from_logits_all_rmpad(
input_ids_rmpad=input_ids_rmpad,
logits_rmpad=logits_rmpad,
indices=indices,
batch_size=batch_size,
seqlen=seqlen,
response_length=response_length,
) # (batch, seqlen)
origin_log_probs = log_probs_from_logits_all_rmpad(
input_ids_rmpad=input_ids_rmpad,
logits_rmpad=origin_logits_rmpad,
indices=origin_logits_indices,
batch_size=batch_size,
seqlen=seqlen,
response_length=response_length,
) # (batch, seqlen)
torch.testing.assert_close(
masked_mean(log_probs, attention_mask[:, -response_length - 1 : -1]),
masked_mean(origin_log_probs, attention_mask[:, -response_length - 1 : -1]),
atol=1e-2,
rtol=1e-5,
)
print("Check pass")其中 unpad_input 函数简化逻辑的代码如下:
def unpad_input(hidden_states, attention_mask):
# 1. 找到所有有效 token 的位置
# seqlens_in_batch 是一个包含批次中每个序列实际长度的列表,例如 [3, 4]
seqlens_in_batch = attention_mask.sum(dim=-1, dtype=torch.int32)
# indices 是一个一维张量,包含了所有值为1的 mask 元素的展平后索引
indices = torch.nonzero(attention_mask.flatten(), as_tuple=False).flatten()
# 2. 从 hidden_states 中提取出所有有效的 token
# 首先将 hidden_states 展平成 (batch_size * sequence_length, ...)
flat_hidden_states = hidden_states.reshape(-1, hidden_states.shape[-1])
# 然后使用 indices 来挑选出所有有效的 token
hidden_states_unpadded = flat_hidden_states[indices]
# 3. 计算累积序列长度 (cu_seqlens)
# 例如,如果 seqlens_in_batch 是 [3, 4],cu_seqlens 会是 [0, 3, 7]
cu_seqlens = torch.cat(
[torch.zeros(1, dtype=torch.int32), seqlens_in_batch.cumsum(dim=0)], dim=0
)
max_seqlen_in_batch = seqlens_in_batch.max().item()
return hidden_states_unpadded, indices, cu_seqlens, max_seqlen_in_batch这里的 cu_seqlens 就是不需要传入 attention_mask 的原因,相当于取代了 mask 的功能。 调试输出一些张量的 shape:
(Pdb) input_ids.shape
torch.Size([4, 128])
(Pdb) attention_mask.shape
torch.Size([4, 128])
(Pdb) position_ids.shape
torch.Size([4, 128])
(Pdb) input_ids_rmpad.shape
torch.Size([1, 359]) # 也就是说去掉pad后4个sample在一起的有效长度为359简单来说,indices 是一个“索引地图”。它的核心作用是记录在原始的、带填充的、被展平(flattened)的批次数据中,所有有效(非填充)词元的位置。
当 unpad_input 处理 input_ids 时,它会丢掉所有的填充词元,只保留有效词元,并生成这个 indices 地图。这个地图至关重要,因为批次中的数据往往不止 input_ids,还有与之严格对齐的 position_ids、token_type_ids 等。
indices 的主要用途是:确保其他辅助张量(如 position_ids)能够以与 input_ids 完全相同的方式被“解填充”(unpad),从而保持数据的一致性和对齐。 如果 position_ids 的解填充方式与 input_ids 不一致,那么旋转位置编码(Rotary Position Embedding, RoPE)等依赖位置信息的操作就会完全错乱。