regex
正则表达式
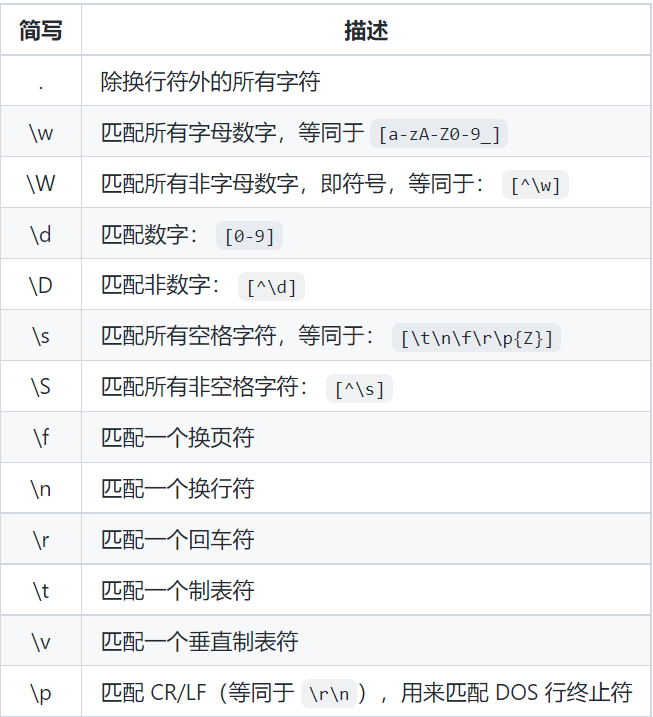
[abcd]匹配中括号里的所有字符[^abcd]匹配除了括号里的所有字符[A-Za-z]匹配所有字母[\s\S]是匹配所有空白符,包括换行,非空白符,包括换行[\w]匹配字母、数字、下划线。等价于[A-Za-z0-9_]匹配有特殊含义的,比如* ^ 等 记得要加上反斜杠进行转义
?匹配前面的表达式0次或1次
**.匹配除*
+匹配前面的表达式1次或多次
*匹配前面的表达式0次或多次
{n}匹配n次,{n,m}最少匹配n次,最多m次,{n,}至少匹配n次
定位符:^ $ 即限定在哪里匹配
()灵活应用
[.]等价于\.
运算优先级

零宽度断言(前后预查)
?=…正先行断言
?=...表示正先行断言,表示第一部分表达式之后必须跟着?=...定义的表达式。
返回结果只包含满足匹配条件的第一部分表达式。
定义一个正先行断言要使用 ()。在括号内部使用一个问号和等号: (?=...)。
正先行断言的内容写在括号中的等号后面。
例如,表达式 (T|t)he(?=\sfat) 匹配 The 和 the,在括号中我们又定义了正先行断言 (?=\sfat) ,即 The 和 the 后面紧跟着 (空格)fat。
?!… 负先行断言
负先行断言 ?! 用于筛选所有匹配结果,筛选条件为
其后不跟随着断言中定义的格式。 正先行断言 定义和 负先行断言 正好相反。
表达式 (T|t)he(?!\sfat) 匹配 The 和 the,且其后不跟着 (空格)fat。
### ?<=… 正后发断言
正后发断言
记作(?<=...) 用于筛选所有匹配结果,筛选条件为
其前跟随着断言中定义的格式。
例如,表达式 (?<=(T|t)he\s)(fat|mat) 匹配 fat 和 mat,且其前跟着 The 或 the。
### ?<!… 负后发断言 负后发断言
记作 (?<!...) 用于筛选所有匹配结果,筛选条件为
其前不跟随着断言中定义的格式。
例如,表达式 (?<!(T|t)he\s)(cat) 匹配 cat,且其前不跟着 The 或 the。
此外还有一种是?:,用于括号匹配中,即non-capturing
group, # 实战
Matching a decimal numbers
来源:https://regexone.com/problem/matching_decimal_numbers
意思就是要匹配Match的还要避开Skip的
具体实现:
^-?\d+(,\d+)*(\.\d+(e\d+)?)?$
解释:
开头匹配负号,其实这里可以变成[\\-\\+]? 以防出现正号
然后匹配带逗号的数字,匹配0次或多次
然后匹配带小数点的数字,匹配0次或1次,因为小数点最多出现一次
显然后面跟着匹配指数,显然指数也最多出现一次。