ray前置知识
原生Ray
代码改编自# verl 解读 -
ray 相关前置知识 (part1)
ray分配资源的单位是bundle,一个bundle一般由1个cpu和1个gpu构成。
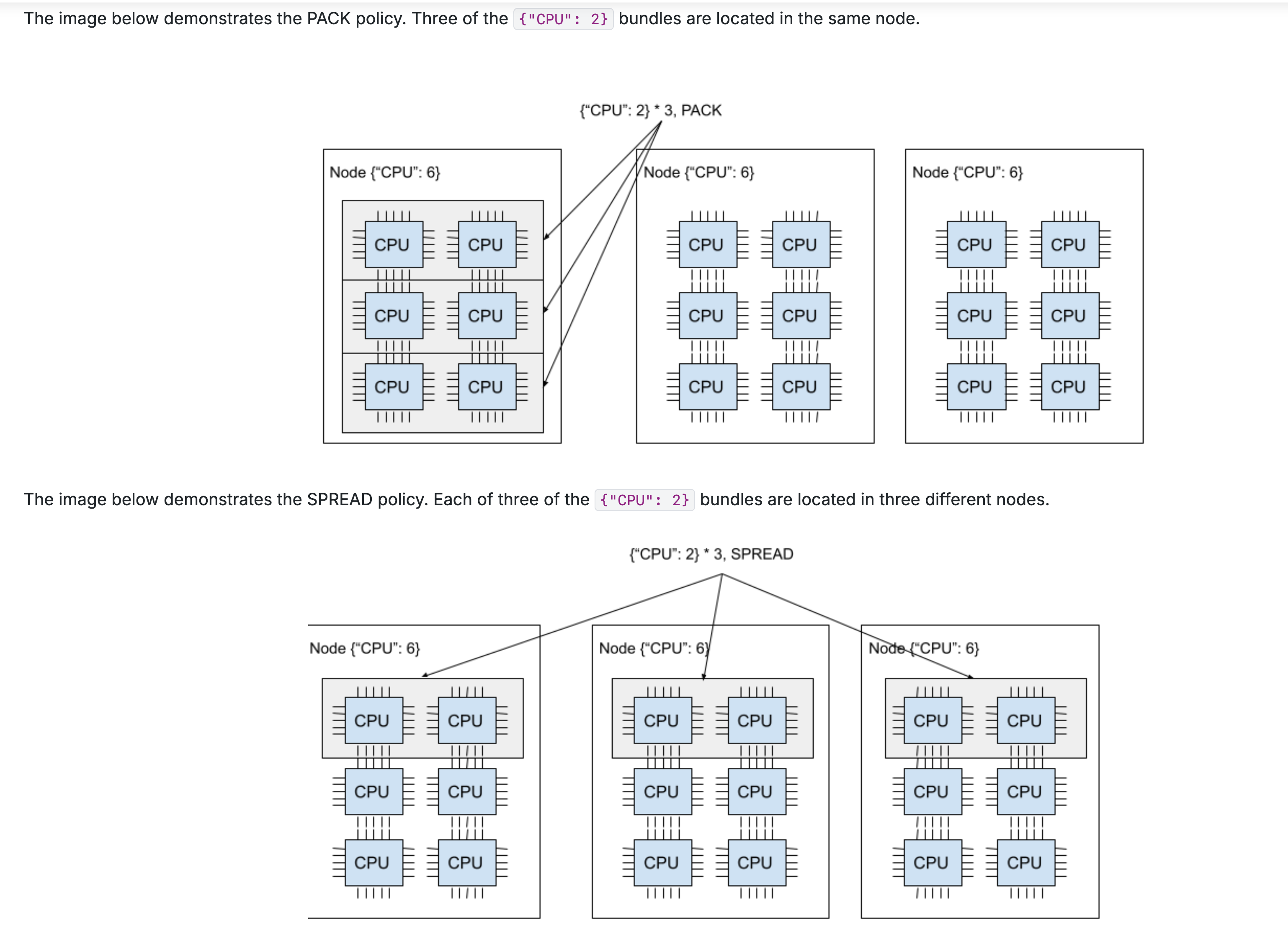
而一个placement_group由多个bundle组成,当参数设置为pack通常为同1个node上的bundle构成的。参数设置为spread为不同node的bundle组成。如下图所示:
在python中,定义placement_group如下:
pg = placement_group([
{"CPU": 1, "GPU": 1} for _ in range(total_devices)
], strategy="STRICT_PACK", name="ray_multi_group_comm")
ray.get(pg.ready())
print(f"=> Placement group is ready, total_devices: {total_devices}")ray中的基本单位有task和actor,一个无状态,一个有状态(可以简单理解为一个是函数,一个是面向对象的类)。都需要用worker来代替运行。因此我们需要定义一个worker来完成各种任务。这个worker都是上述资源的分配单位,它只会看到ray分配给它的资源,而看不到其它的资源,对于分布式训练而言,可以在这个worker中定义分布式训练的各种东西、加载模型、前向训练等。一个worker定义如下:
class WorkerBase:
"""
通用的 Worker 基类。
每个 Worker 实例是一个 Ray Actor,它会在一个独立的进程中运行,并持有一个模型副本。
"""
def __init__(self, model_cls, temp_init: bool = False):
# 获取当前 Ray Actor 所在的节点 ID 和 Actor ID
self._node_id = ray.get_runtime_context().get_node_id()
self._actor_id = ray.get_runtime_context().get_actor_id()
# 获取当前主机的 IP 地址
self._ip_address = socket.gethostbyname(socket.gethostname())
if temp_init: # 如果是临时初始化,则直接返回,不进行模型和分布式环境的设置
return
# 设置随机种子
self._set_seed(42)
# 初始化 PyTorch 分布式环境
if not dist.is_initialized(): # 检查是否已经初始化
dist.init_process_group(
backend="nccl", # 使用 NCCL 作为后端,适用于 NVIDIA GPU
world_size=int(os.getenv("WORLD_SIZE", "1")), # 从环境变量获取 world_size
rank=int(os.getenv("RANK", "0")), # 从环境变量获取当前进程的 rank
# 从环境变量获取主节点的地址和端口,用于建立连接
init_method=f"tcp://{os.getenv('MASTER_ADDR')}:{os.getenv('MASTER_PORT')}"
)
self._rank = dist.get_rank() # 获取当前进程的排名
self._world_size = dist.get_world_size() # 获取分布式组的大小
self.model = model_cls() # 实例化传入的模型类
self.model.to("cuda") # 将模型移动到 GPU
# 打印初始化信息
print(f"=> Rank {self._rank}/{self._world_size} in group '{os.getenv('GROUP_NAME')}' initialized model: {self.model.__class__.__name__}")
def get_actor_info(self):
"""返回该 actor 的网络信息。"""
return { "ip_address": self._ip_address }
def _set_seed(self, seed: int = 42):
"""设置随机种子。"""
set_random_seed(seed)
def train_step(self, data):
"""执行一个训练步骤。"""
x = data.to("cuda") # 将输入数据移动到 GPU
y = self.model(x) # 模型前向传播
loss = y.sum() # 计算一个简单的损失(所有输出的和)
loss.backward() # 反向传播,计算梯度
return loss.cpu() # 返回在 CPU 上的 loss 值
def sample_grads(self):
"""采样一个参数的梯度用于验证。"""
for name, p in self.model.named_parameters(): # 遍历所有带名字的参数
if p.requires_grad is True: # 找到第一个需要梯度的参数
return name, p.grad.cpu() # 返回参数名和它在 CPU 上的梯度其中model_cls就是定义的各种模型。 然后就可以给各种worker绑定资源。这里我定义了两种模型,node上有4张gpu,我实现的是两种模型分别占2张不同的卡:
def setup_and_create_workers(pg, model_cls, group_name, start_bundle_index, num_workers_in_group):
"""
一个辅助函数,用于设置一个分布式组并为其创建 workers。
"""
print(f"\\n========== 正在设置组: {group_name} ==========")
# 将 WorkerBase 类包装成 Ray Remote Actor
Worker = ray.remote(WorkerBase)
# 创建一个临时 worker 来获取该组的网络信息
# 这个 worker 会被放置在指定的 placement group bundle 上
temp_worker = Worker.options(
scheduling_strategy=PlacementGroupSchedulingStrategy(
placement_group=pg,
placement_group_bundle_index=start_bundle_index,
),
num_gpus=1,
).remote(model_cls=model_cls, temp_init=True) # 使用 temp_init=True,避免完全初始化
# 获取临时 worker 的网络信息,特别是 IP 地址,用作该组的 master 地址
network_info = ray.get(temp_worker.get_actor_info.remote())
master_addr = network_info["ip_address"]
master_port = str(find_free_port()) # 为该组找到一个空闲端口
ray.kill(temp_worker) # 销毁临时 worker
print(f"为组 {group_name} 使用的主节点地址: {master_addr}:{master_port}")
workers = [] # 存储创建的 worker
# 循环创建指定数量的 worker
for i in range(num_workers_in_group):
rank = i # 当前 worker 在其组内的 rank
bundle_index = start_bundle_index + i # 该 worker 在 placement group 中的 bundle 索引
# 设置分布式环境所需的环境变量
env_vars = {
"WORLD_SIZE": str(num_workers_in_group),
"RANK": str(rank),
"MASTER_ADDR": master_addr,
"MASTER_PORT": master_port,
"GROUP_NAME": group_name
}
# 创建一个正式的 worker actor
workers.append(
Worker.options(
name=f"{group_name}_rank_{rank}", # 为 actor 命名,方便调试
scheduling_strategy=PlacementGroupSchedulingStrategy(
placement_group=pg,
placement_group_bundle_index=bundle_index,
),
runtime_env={"env_vars": env_vars}, # 将环境变量传递给 actor
num_gpus=1, # 为每个 actor 分配一个 GPU
).remote(model_cls=model_cls) # 传入模型类进行实例化
)
print(f"========== 组 {group_name} 设置完成 ==========")
return workers # 返回创建的 worker 列表其中Woker.options()是分配资源的关键部分.placement_group代表使用的pg,而bundle_index代表分别的资源是编号为多少的bundle 以及num_gpus=1代表worker需要1个gpu资源,这是最关键的地方。
传入的环境变量在worker类内部获取,见上一段代码。这样就实现了两张卡放一个模型,另两张卡放另一个模型。
最后是启动代码:
def main():
"""主执行函数"""
set_random_seed(42) # 设置全局随机种子
ray.init() # 初始化 Ray
total_devices = 4 # 定义总共使用的设备(GPU)数量
num_devices_per_group = 2 # 定义每个分布式组中的设备数量
# 创建一个 Placement Group,请求 total_devices 个 "bundle"
# 每个 bundle 需要 1 个 CPU 和 1 个 GPU
# "STRICT_PACK" 策略会尝试将这些 bundle 放置在同一个节点上
pg = placement_group([
{"CPU": 1, "GPU": 1} for _ in range(total_devices)
], strategy="STRICT_PACK", name="ray_multi_group_comm")
ray.get(pg.ready()) # 等待 placement group 的资源被成功分配
print(f"=> Placement group 已就绪, 总设备数: {total_devices}")
# --- 设置组 A,使用 DummyAttn 模型 ---
workers_a = setup_and_create_workers(
pg=pg,
model_cls=DummyAttn, # 指定模型类
group_name="GroupA_DummyAttn", # 组名
start_bundle_index=0, # 在 placement group 中的起始 bundle 索引
num_workers_in_group=num_devices_per_group # 该组的 worker 数量
)
# --- 设置组 B,使用 NewDummyModel 模型 ---
workers_b = setup_and_create_workers(
pg=pg,
model_cls=NewDummyModel, # 指定模型类
group_name="GroupB_NewDummyModel", # 组名
start_bundle_index=2, # 在 placement group 中的起始 bundle 索引(紧接着组 A)
num_workers_in_group=num_devices_per_group # 该组的 worker 数量
)
# --- 训练并验证组 A (DummyAttn) ---
print("\\n--- 正在训练并验证组 A (DummyAttn) ---")
# 创建一批随机数据
datas_a = torch.randn(4, 128, 1024)
# 异步执行 train_step
# 将数据分块 (chunk) 并分发给每个 worker
ray.get([worker.train_step.remote(datas_a.chunk(num_devices_per_group)[i]) for i, worker in enumerate(workers_a)])
# 从每个 worker 获取梯度样本
grads_a = ray.get([worker.sample_grads.remote() for worker in workers_a])
print("正在验证组 A 的梯度...")
# 验证组内所有 worker 的梯度是否一致
for i in range(1, len(grads_a)):
# 使用 torch.allclose 比较两个梯度张量是否在数值上足够接近
assert torch.allclose(grads_a[0][1], grads_a[i][1]), "组 A 的梯度不匹配!"
print("✅ 组 A 的梯度一致。")
# --- 训练并验证组 B (NewDummyModel) ---
print("\\n--- 正在训练并验证组 B (NewDummyModel) ---")
# 创建一批随机数据
datas_b = torch.randn(4, 512)
# 异步执行 train_step
# 将数据分块并分发给每个 worker
ray.get([worker.train_step.remote(datas_b.chunk(num_devices_per_group)[i]) for i, worker in enumerate(workers_b)])
# 从每个 worker 获取梯度样本
grads_b = ray.get([worker.sample_grads.remote() for worker in workers_b])
print("正在验证组 B 的梯度...")
# 验证组内所有 worker 的梯度是否一致
for i in range(1, len(grads_b)):
assert torch.allclose(grads_b[0][1], grads_b[i][1]), "组 B 的梯度不匹配!"
print("✅ 组 B 的梯度一致。")
ray.shutdown() # 关闭 Ray最后的输出:
2025-06-26 15:23:47,563 INFO worker.py:1879 -- Started a local Ray instance. View the dashboard at http://127.0.0.1:8266
=> Placement group 已就绪, 总设备数: 4
\n========== 正在设置组: GroupA_DummyAttn ==========
为组 GroupA_DummyAttn 使用的主节点地址: 127.0.1.1:49335
========== 组 GroupA_DummyAttn 设置完成 ==========
\n========== 正在设置组: GroupB_NewDummyModel ==========
为组 GroupB_NewDummyModel 使用的主节点地址: 127.0.1.1:50477
========== 组 GroupB_NewDummyModel 设置完成 ==========
\n--- 正在训练并验证组 A (DummyAttn) ---
(WorkerBase pid=2898182) => Rank 0/2 in group 'GroupA_DummyAttn' initialized model: DummyAttn
正在验证组 A 的梯度...
✅ 组 A 的梯度一致。
\n--- 正在训练并验证组 B (NewDummyModel) ---
(WorkerBase pid=2898392) => Rank 0/2 in group 'GroupB_NewDummyModel' initialized model: NewDummyModel
正在验证组 B 的梯度...
✅ 组 B 的梯度一致。
(WorkerBase pid=2898181) => Rank 1/2 in group 'GroupA_DummyAttn' initialized model: DummyAttn
(WorkerBase pid=2898391) => Rank 1/2 in group 'GroupB_NewDummyModel' initialized model: NewDummyModelveRL中的Ray
使用# 【AI Infra】【RLHF框架】二、VeRL中colocate实现源码解析中的代码:
import ray
from verl.single_controller.base import Worker
from verl.single_controller.base.decorator import register, Dispatch
from verl.single_controller.ray.base import RayResourcePool, RayClassWithInitArgs, RayWorkerGroup, create_colocated_worker_cls
from verl import DataProto
@ray.remote
class Actor(Worker):
def __init__(self) -> None:
super().__init__()
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def add(self, data: DataProto):
data.batch['a'] = data.batch['a'].to("cuda")
data.batch['a'] += self.rank
return data
@ray.remote
class Critic(Worker):
def __init__(self, config) -> None:
super().__init__()
self.config = config
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def sub(self, data: DataProto):
data.batch['a'] = data.batch['a'].to("cuda")
data.batch['a'] -= self.config['b']
return data
def test_colocated_workers():
ray.init()
import torch
# 构建一个DataProto,其中属性a是维度为10的零向量。
data = DataProto.from_dict({'a': torch.zeros(10)})
print(data.batch["a"])
# 利用RayClassWithInitArgs将自定义的worker和参数封装起来
actor_cls = RayClassWithInitArgs(cls=Actor)
critic_cls = RayClassWithInitArgs(cls=Critic, config={'b': 10})
# 定义资源池,仅包含一个2GPU的节点
resource_pool = RayResourcePool(process_on_nodes=[2])
# 利用create_colocated_worker_cls将自定义的两个worker绑定到WorkerDict上
cls_dict = {'actor': actor_cls, 'critic': critic_cls}
ray_cls_with_init = create_colocated_worker_cls(cls_dict)
# 启动WorkerDict
wg_dict = RayWorkerGroup(resource_pool=resource_pool, ray_cls_with_init=ray_cls_with_init)
# 分别获取actor和critic的workergroup
spawn_wg = wg_dict.spawn(prefix_set=cls_dict.keys())
colocated_actor_wg = spawn_wg['actor']
colocated_critic_wg = spawn_wg['critic']
# actor执行add、critic执行sub
actor_output = colocated_actor_wg.add(data)
critic_output = colocated_critic_wg.sub(data)
# actor_output.batch["a"]==[0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
# critic_output.batch["a"]==[-10, -10, -10, -10, -10, -10, -10, -10, -10, -10]
print(actor_output.batch["a"])
print(critic_output.batch["a"])
ray.shutdown()
if __name__ == '__main__':
test_colocated_workers()具体的操作我会在init_workers章节进行讲解,这里是对veRL中的single_controller的一个初探。
问题
有一个常见的问题是为什么在placement_group中分配了一个bundle为1个gpu,为什么还要指定num_gpus=1,这个参数有什么含义吗?
简单来说,两者都需要,因为它们在 Ray 的调度系统中扮演着不同但互补的角色:
placement_group中的{"GPU": 1}:这是在做资源“预留” (Reservation)。- 它的作用是告诉 Ray 集群:“我需要你为我准备好一个资源包(bundle),这个包里必须包含 1 个 CPU 和 1 个 GPU。”
placement_group的主要目的是确保一组相关的资源能够被原子性地、协同地调度。比如,strategy="STRICT_PACK"确保了所有这些 bundles 都会被放置在同一个节点上,这对于需要低延迟通信的分布式训练至关重要。- 这就像是为一场宴会预订了一个能容纳4位客人的包间,并确保这4个座位都在同一张桌子上。它只是圈占了资源,但还没有指定谁来使用这些资源。
Worker.options(num_gpus=1):这是在为 Actor 提出具体的“资源请求” (Request)。- 它的作用是告诉 Ray:“我即将创建的这个
WorkerActor,它本身在运行时需要消耗 1 个 GPU。” - Ray 的调度器需要根据这个明确的请求来为 Actor 分配具体的物理设备。没有这个声明,Ray 调度器会认为该 Actor 不需要 GPU。
- 这就像是告诉宴会的主管:“这位客人需要一个座位。”
- 它的作用是告诉 Ray:“我即将创建的这个
为什么缺一不可?
PlacementGroupSchedulingStrategy将这两者联系起来。它告诉 Ray:“请将这个需要1个GPU的Actor (num_gpus=1),安排到我们之前预留的那个包含GPU的bundle ({"GPU": 1}) 上去。”如果只有
placement_group的预留而没有 Actor 的num_gpus=1请求,Ray 的调度器会看到一个矛盾:你试图将一个声称不需要 GPU 的 Actor 安排在一个为 GPU 使用者保留的“席位”上。这可能会导致调度失败或资源分配混乱。反之,如果只有 Actor 的
num_gpus=1请求而没有placement_group,Ray 会在整个集群中寻找任何一个可用的 GPU 来满足这个 Actor,但无法保证它会和其他相关的 Actor 运行在同一个节点上,从而失去了分布式训练的性能优势。
总结:
placement_group
是一个宏观的、用于资源预留和协同定位的机制,而
num_gpus=1 是一个微观的、用于声明单个 Actor
实际资源消耗的机制。两者必须同时使用并保持一致,才能确保 Ray
能够精确、高效地将需要特定资源的 Actor
调度到你为它们预留的、具有特定拓扑结构的资源包中。这种显式的设计让复杂的分布式资源管理变得更加清晰和可控。