ppo
PPO (openrlhf 库)
重点记录一下 experience 的采集过程。训练其实很简单。Actor 在 RLHF
会进行 auto-regressive decoding,而 critic, reward 和 reference 则只会
prefill,不会 decode。所以,我们将 actor 的推理特定称为
rollout,而其他模型的推理称为 inference。 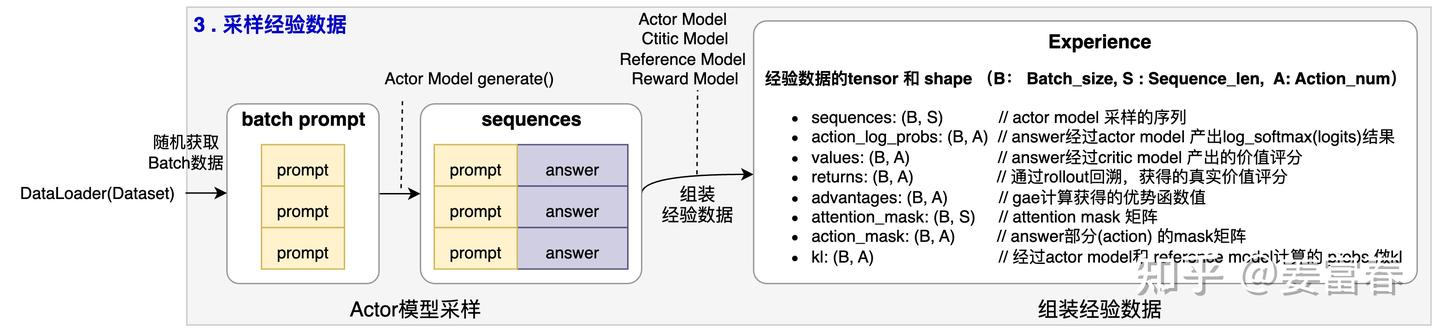
获取 experience 的总体流程:
####################
# 1. 调用Actor generate()方法获取Prompt的生成结果,把结果存储到Sample对象
####################
samples_list = self.generate_samples(all_prompts, **generate_kwargs)
torch.distributed.barrier()
####################
# 2. 调用make_experience 对每个Sample做处理,组装Experience部分字段(除了advantage和return)
####################
experiences = []
for samples in samples_list:
experiences.append(self.make_experience(samples).to_device("cpu"))
experiences, rewards = self.process_experiences(experiences)
####################
# 3. 通过从后往前回溯计算的方式,获取advantage和return值
####################
for experience, reward in zip(experiences, rewards):
num_actions = experience.info["num_actions"]
if self.advantage_estimator == "gae":
experience.advantages, experience.returns = self.get_advantages_and_returns(
experience.values,
reward,
experience.action_mask,
generate_kwargs["gamma"],
generate_kwargs["lambd"],
)
if not getattr(self, "packing_samples", False):
return_sums = reward.sum(dim=-1)
else:
return_sums = torch.tensor(
[each_reward.sum() for each_reward in reward], device=torch.cuda.current_device()
)
experience.info["return"] = return_sums
return experiences关于句子序列中的 state 和 action 定义如下: 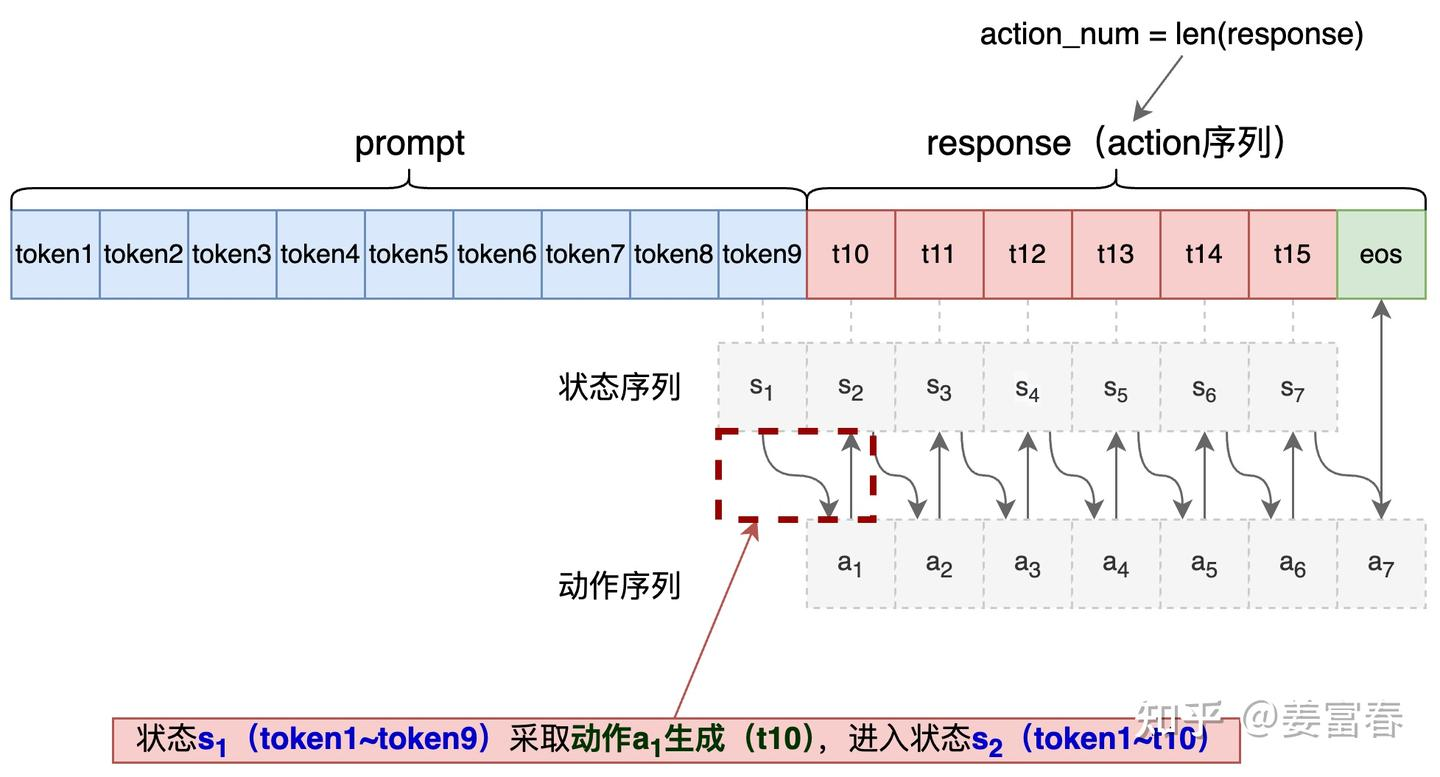 ## Prompt -> sample 首先对 batch 进行 pad,
注意推理时需要左 pad。
## Prompt -> sample 首先对 batch 进行 pad,
注意推理时需要左 pad。 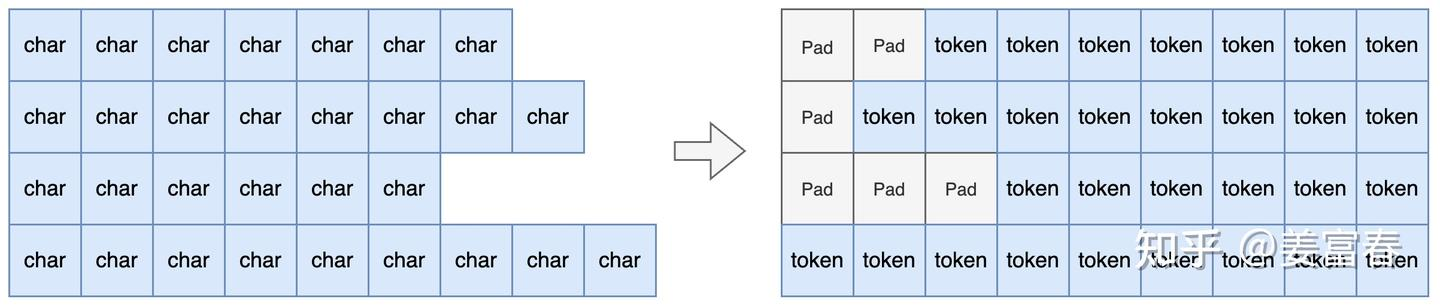 然后生成 sequences,attention_mask, action_mask:
Sequences:
然后生成 sequences,attention_mask, action_mask:
Sequences: 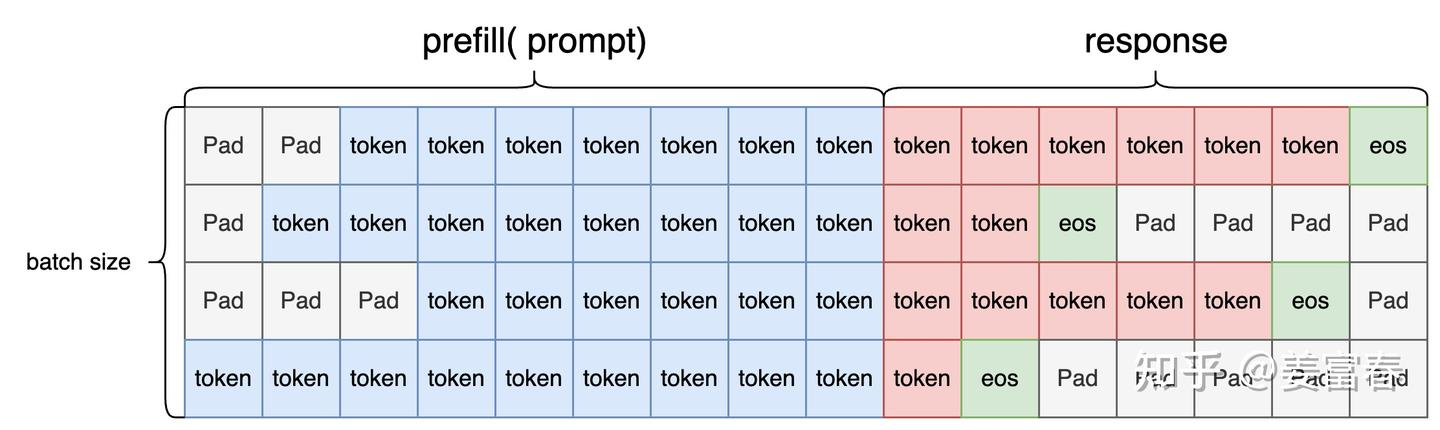 Attention_mask:
Attention_mask: 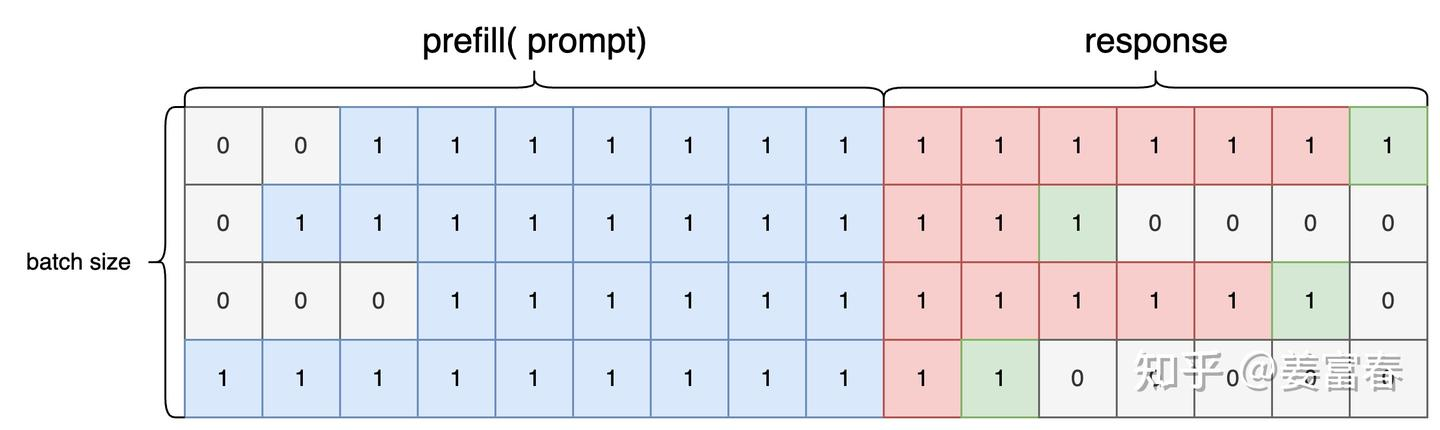 Action_mask:
Action_mask: 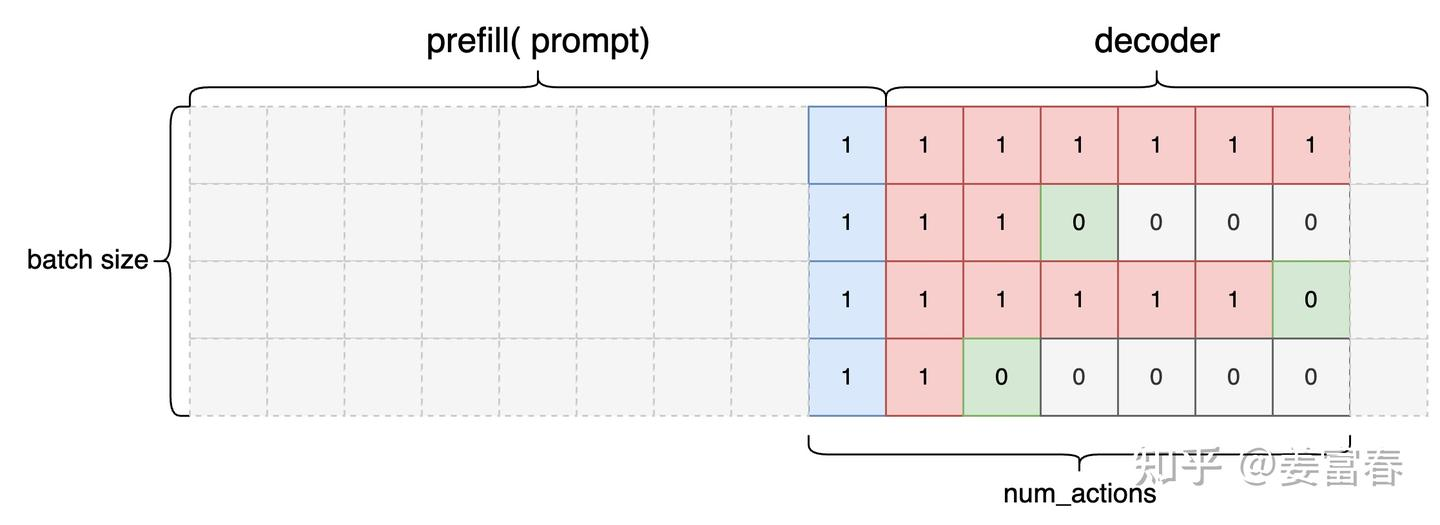 至此 sample 数据就得到了。 ## Sample -> experience
首先根据前面 generate 的 prompt+response 计算得到 response 部分的 logp:
至此 sample 数据就得到了。 ## Sample -> experience
首先根据前面 generate 的 prompt+response 计算得到 response 部分的 logp:
 同样的方式得到 reference_model 的
logp,然后就可以计算 kl 散度。
同样的方式得到 reference_model 的
logp,然后就可以计算 kl 散度。
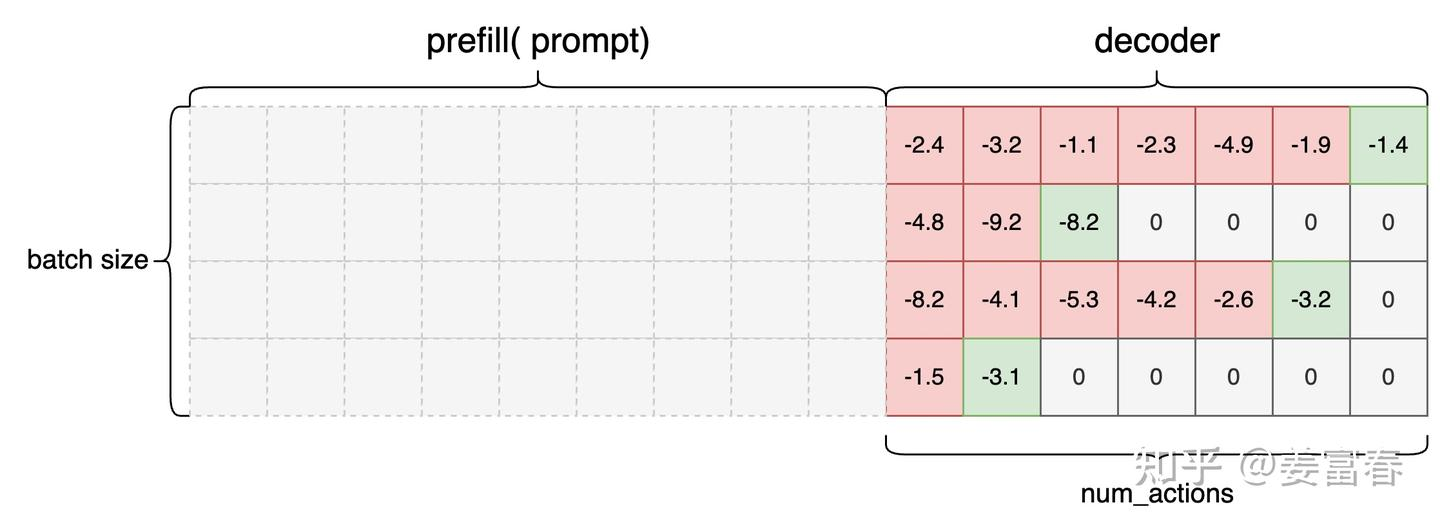
Critic 是预估状态的价值,看代码实现时,参考图 3,先理解 LLM
中状态的起始位置。最终状态序列长度是 num_actions (生成 token
的数量),状态序列起始位置是 Prompt 的最后一个 token,结束位置是最后 eos
token 前一个 token,所以计算出的 Critic 预估状态价值的数据为:  注意,图里 eos token 和 pad token
的位置输出应该并不是 0,是 regression head
的输出(小实数值),只是我们期望良好的价值函数在这些位置输出 0
注意,图里 eos token 和 pad token
的位置输出应该并不是 0,是 regression head
的输出(小实数值),只是我们期望良好的价值函数在这些位置输出 0
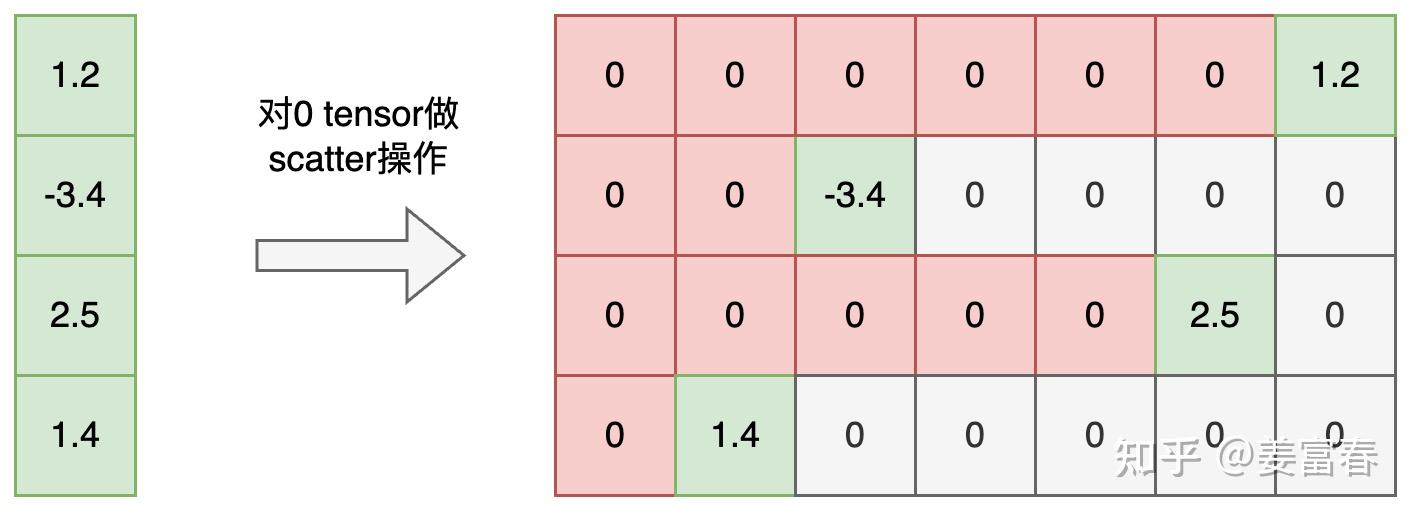
在 RLHF 中,Reward Model 是一个 ORM(outcome Reward Model)
也就是对完整的生成 response 输出一个打分。代码实现上取每个 sequence eos
token 位置的预估打分值。如图 11,图中”xx”也是会并行计算出的 Reward
值,单最终只取了序列最后 eos 位置的 score 作为完整序列的打分值。最后
reward 处理成[B, 1]格式,每个序列一个打分。 
 Gae (Generalized Advantage Estimation) 是 PPO
论文中实现的优势奖励值计算方法,可平衡优势预估的偏差和方差。结合公式和图片内容更容易理解:
Gae (Generalized Advantage Estimation) 是 PPO
论文中实现的优势奖励值计算方法,可平衡优势预估的偏差和方差。结合公式和图片内容更容易理解:
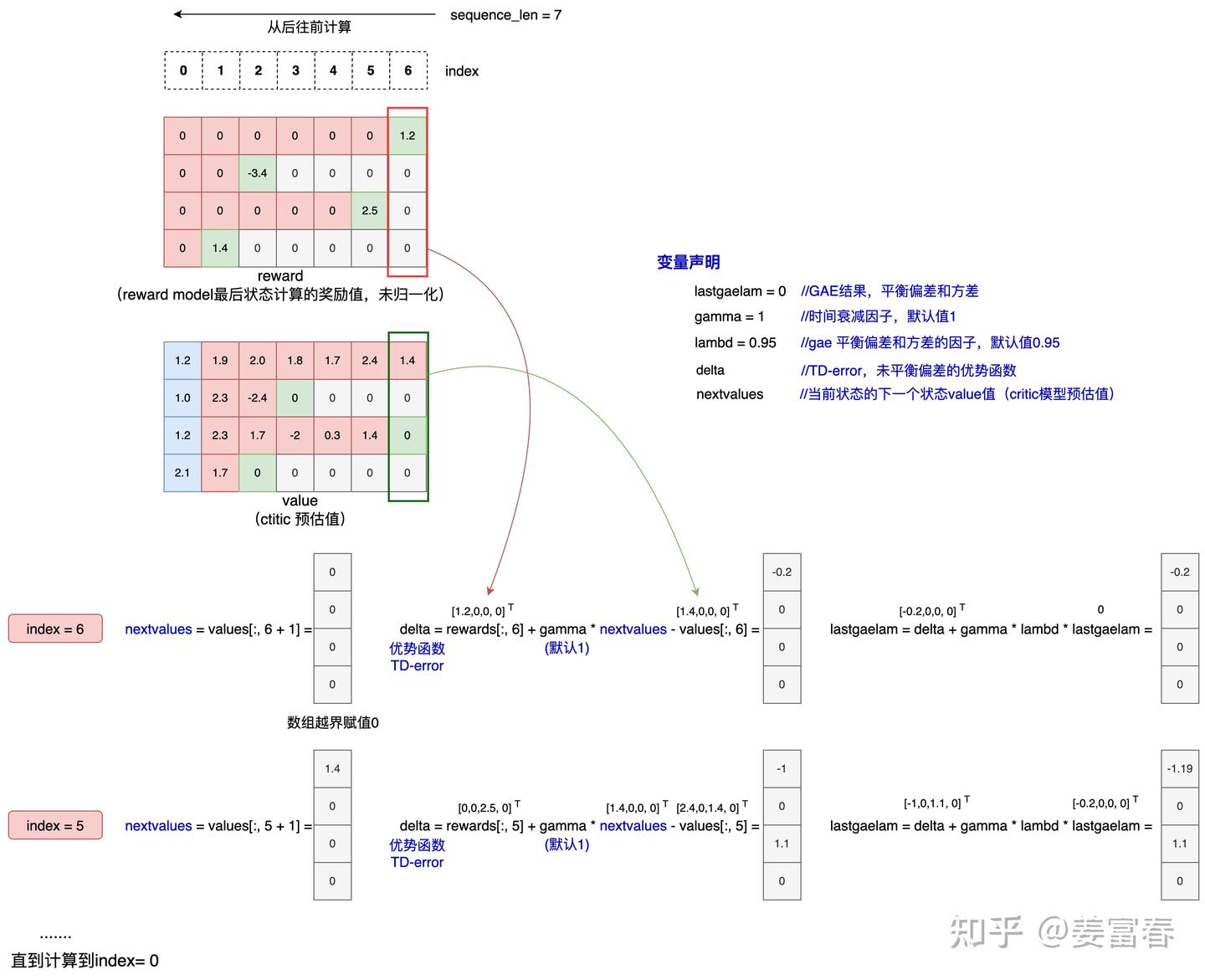
def get_advantages_and_returns(values: torch.Tensor, rewards: torch.Tensor,)
Advantages looks like this:
Adv1 = R1 + γ * λ * R2 + γ^2 * λ^2 * R3 + ...
- V1 + γ * (1 - λ) V2 + γ^2 * λ * (1 - λ) V3 + ...
Returns looks like this:
Ret1 = R1 + γ * λ * R2 + γ^2 * λ^2 * R3 + ...
+ γ * (1 - λ) V2 + γ^2 * λ * (1 - λ) V3 + ... 计算 returns:
计算 returns: 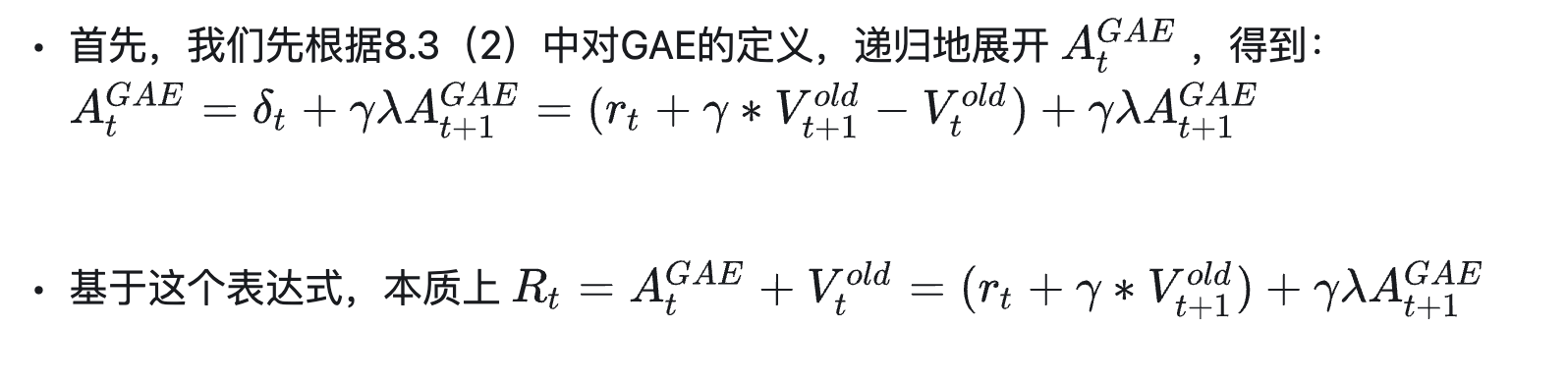
此时我们就完成了 experience 的采集过程。
Clip 的一些细节

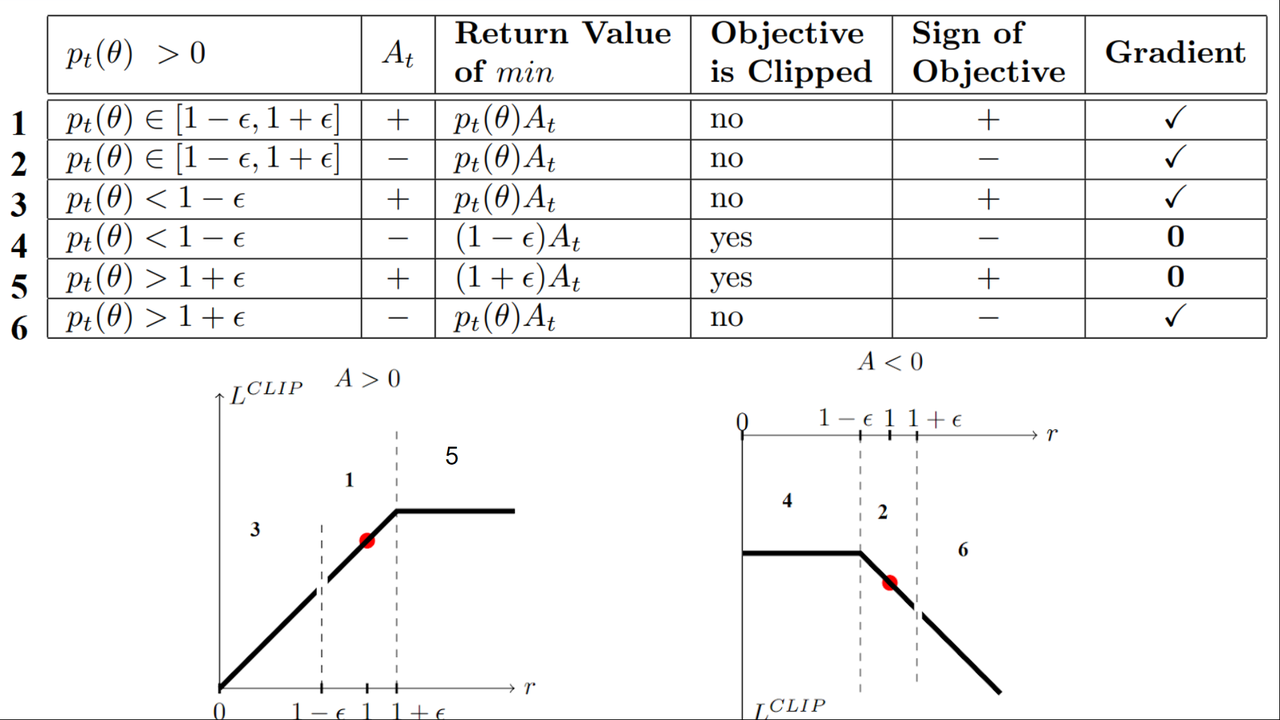
上面这张图是很经典的一张图,来分析什么情况下 clip 项计算梯度。
例子

state对于文本序列来说就是之前生成的所有tokens,V(s)就是当前所有tokens为状态下的回报。而reward是对于整个句子而言的,因此只有最后一个状态才有reward。
参考
如何理解Q值和V值 (https://zhuanlan.zhihu.com/p/14569025663)