并查集
def find(x):
if (p[x] != x):
p[x] = find(p[x])
return p[x]上面是y总的模板,实现了路径压缩。
def find(x):
if (p[x] != x):
p[x] = find(p[x])
return p[x]上面是y总的模板,实现了路径压缩。
温度超参数t,一般为softmax结果除以该参数,或者在对比学习中,相似度除以参数t。
如图: 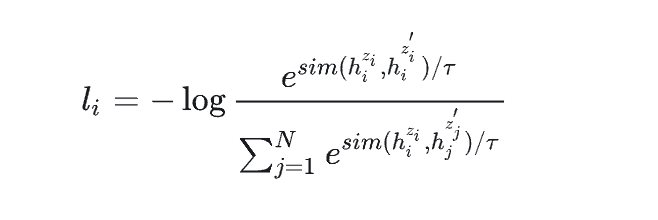 上图为无监督simcse中的损失函数。
上图为无监督simcse中的损失函数。
t越大,结果越平滑,t越小,得到的概率分布更“尖锐”。
当t趋于0时: 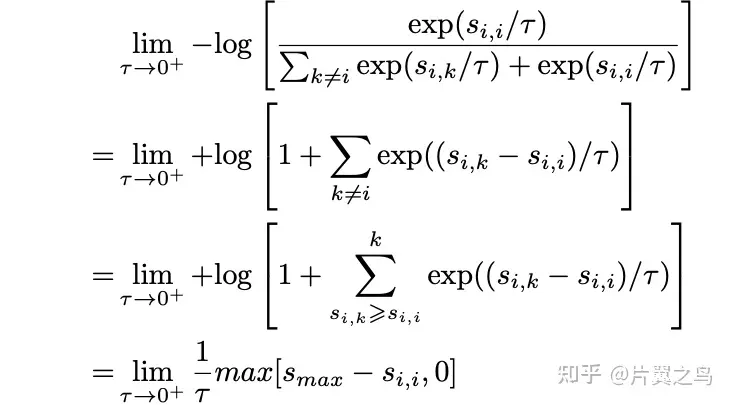 此时只关注最困难的负样本(smax)。 当t趋于∞时:
此时只关注最困难的负样本(smax)。 当t趋于∞时: 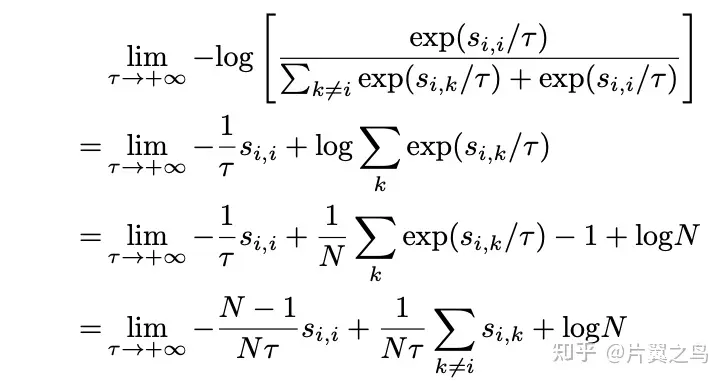 此时对比损失对所有负样本的权重都相同。
此时对比损失对所有负样本的权重都相同。
leetcode地址:953. 验证外星语词典 - 力扣(LeetCode)
python列表之间也可以进行比较(太灵活了),比如[1, 2, 3] < [2, 2, 3]成立,即按照字典序进行比较,与其是一样的比较规则。因此对于本题可以利用python的特性轻松解决。
好久没写python了,变得很生疏,一开始写的很蠢:















L2正则化是在损失函数上做文章。 权重衰减是在梯度更新时增加一项。 
Pre-norm:\(X_t+1=X_{t}+F_{t}(Norm(X_{t}))\)
\(先来看Pre-norm^{+},递归展开:\) \[X_{t+1}=X_t+F_t(Norm(X_t))\] \(=X_{0}+F_{1}(Norm(X_{1}))+\ldots+F_{t-1}(Norm(X_{t-1}))+F_{t}(Norm(X_{t}))\) 其中,展开\(^{+}\)后的每一项( \(F_{1}( Norm( X_{1}) ) , \ldots\), \(F_{t- 1}( Norm( X_{t- 1}) )\), \(F_{t}( Norm( X_{t}) )\))之间都是同一量级的, 所以\(F_1(Norm(X_1))+\ldots F_{t-1}(Norm(X_{t-1}))+F_t(Norm(X_t))\)和 \(F_1(Norm(X_1))+\ldots F_{t-1}(Norm(X_{t-1}))\)之间的区别就像t和t-1的区别一样,我们可以将 其记为\(X_t+ 1= \mathscr{O} ( t+ 1)\) . 这种特性就导致当t足够大的时候,\(X_{t+1}\)和\(X_t\)之间区别可以忽略不计(直觉上),那么就有:
在机器学习中,hinge loss是一种损失函数,它通常用于”maximum-margin”的分类任务中,如支持向量机。数学表达式为:
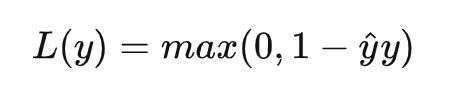
其中 \(\hat{y}\) 表示预测输出,通常都是软结果(就是说输出不是0,1这种,可能是0.87。), \(y\) 表示正确的类别。 - 如果 \(\hat{y}y<1\) ,则损失为: \(1-\hat{y}y\) - 如果\(\hat{y}y>1\) ,则损失为:0
前几天试着投了简历,没想到有两家约了面试,一个是得物一个是北京百分点,得物面试没有怎么准备,太仓促了,二面挂了,百分点拿到了offer,但决定考研了就没去,记录一下面试的问题。岗位是nlp算法岗。