remove_padding
即 packing,将不同长度的序列紧凑存储,避免填充,减少不必要的计算和存储,提升效率。
动机
sft进行微调,因为gpu是并行计算的,所以如果一个batch里面的数据,每条数据长度不相等,就需要对数据进行truncation(截断)和padding(pad数据到相同的seq_length)。显然,如果使用了padding,那么一个batch里面,就会有很多的pad_token,这些pad_token输入进入到了模型,但是却没有样本训练,造成了计算量的浪费。
即 packing,将不同长度的序列紧凑存储,避免填充,减少不必要的计算和存储,提升效率。
sft进行微调,因为gpu是并行计算的,所以如果一个batch里面的数据,每条数据长度不相等,就需要对数据进行truncation(截断)和padding(pad数据到相同的seq_length)。显然,如果使用了padding,那么一个batch里面,就会有很多的pad_token,这些pad_token输入进入到了模型,但是却没有样本训练,造成了计算量的浪费。
一句话:在sequence维度上进行切分
在verl中,一般与remove_padding一起使用,即
UloRL的核心创新 动态掩码熟练掌握正向词元(Dynamic Masking of well-Mastered Positive Tokens, DMMPTs)。论文作者敏锐地指出,熵坍塌的根源并非“训练正样本”,而是“过度训练已经熟练掌握的正向词元(MPTs)”。MPTs指的是那些在正确答案中,且模型已经能以极高概率(如>99%)预测出来的词元。DMMPTs为此设计了一个“熵值恒温器”: 1. 设定一个理想的“目标熵值”。 2. 在训练时,如果模型的当前熵低于这个目标值,说明模型开始变得“僵化”了。此时,系统会自动“屏蔽”(mask)掉那些MPTs,不再对它们进行训练,迫使模型关注那些还未掌握好的部分。 3. 如果模型熵值高于或等于目标值,则正常进行训练。
进入大模型时代,基本上所有大模型都使用 decoder 部分,因此本文只分析 decoder 部分的参数量。 Transformer 的 decoder 每一层由 attention 和 mlp 组成,一般有 l 层。
Self-attention 层由 \(W_{Q}\) 、\(W_{K}\)、\(W_{V}\) 和输出矩阵 \(W_{O}\) 和它们的偏置组成,权重矩阵的形状为 \([h,h]\),偏置形状为 \([h]\),则 self-attention 部分的参数量为 \(4h^2+4h\)
图示: 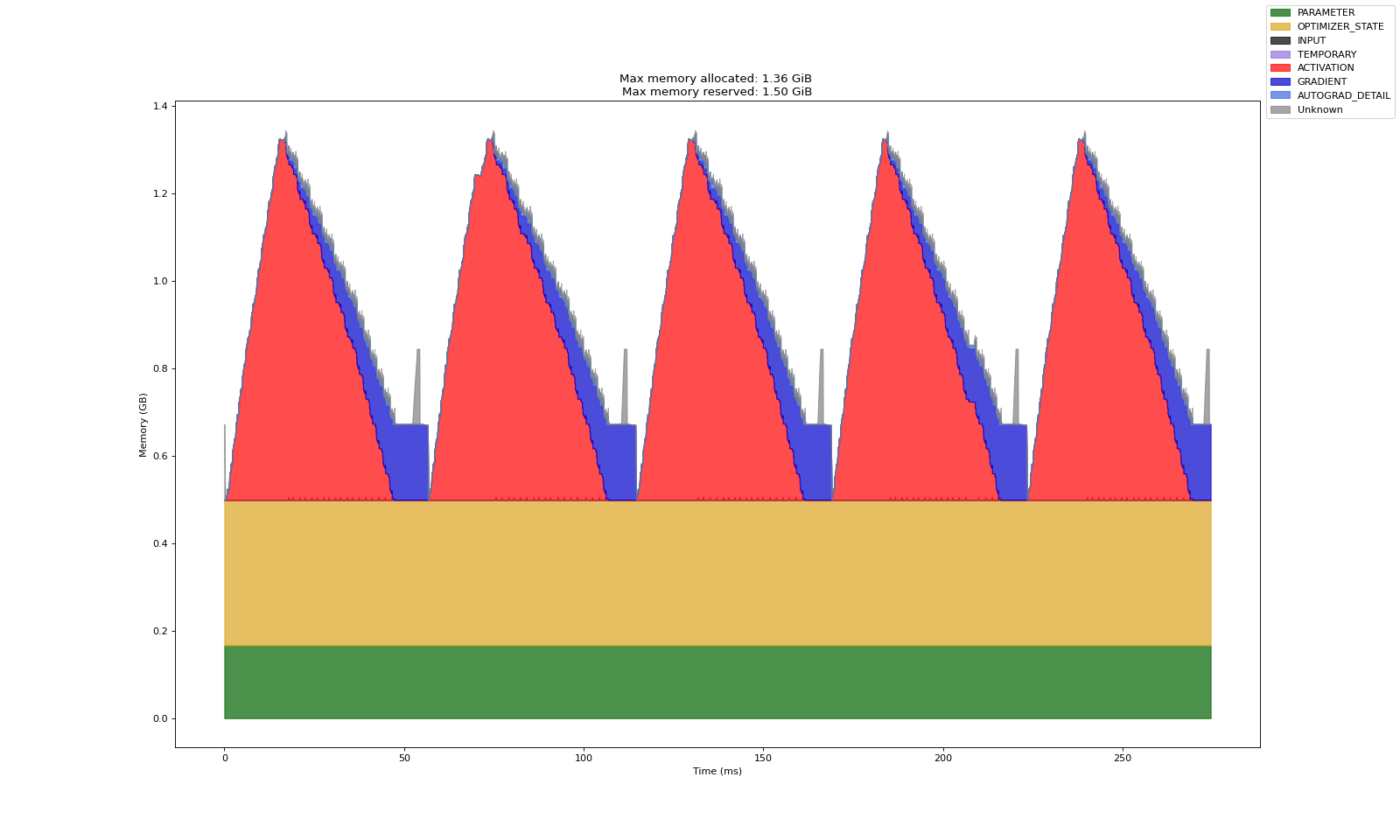 具体数值: 对于一个 transformer
来说,参数量可以由以下公式给出(详见 transformer参数量分析):
具体数值: 对于一个 transformer
来说,参数量可以由以下公式给出(详见 transformer参数量分析):
[大模型微调样本构造 trick](https://zhuanlan.zhihu.com/p/641562439)
多轮对话的传统组织方式:将多轮对话拆分为多条独立的训练样本,如 Q1A1/Q2A2/Q3A3 可拆分为 Q1—>A1, Q1A1Q2->A2, Q1A1Q2A2Q3->A3 三条样本。
我理解的agent中的world model即可以预测采取某个action之后state的变化,这样做的好处是可以降低试错带来的时间成本或者是其它潜在的成本、风险。