BERT
Bert
BERT 的模型架构非常简单,你已经知道它是如何工作的:它只是 Transformer 的编码器。新的是训练目标和 BERT 用于下游任务的方式。
我们如何使用纯文本训练(双向)编码器?我们只知道从左到右的语言建模目标,但它仅适用于每个标记只能使用以前的标记(并且看不到未来)的解码器。BERT 的作者提出了其他未标记数据的训练目标。在讨论它们之前,让我们先看看 BERT 作为 Transformer 编码器的输入。
BERT 的模型架构非常简单,你已经知道它是如何工作的:它只是 Transformer 的编码器。新的是训练目标和 BERT 用于下游任务的方式。
我们如何使用纯文本训练(双向)编码器?我们只知道从左到右的语言建模目标,但它仅适用于每个标记只能使用以前的标记(并且看不到未来)的解码器。BERT 的作者提出了其他未标记数据的训练目标。在讨论它们之前,让我们先看看 BERT 作为 Transformer 编码器的输入。
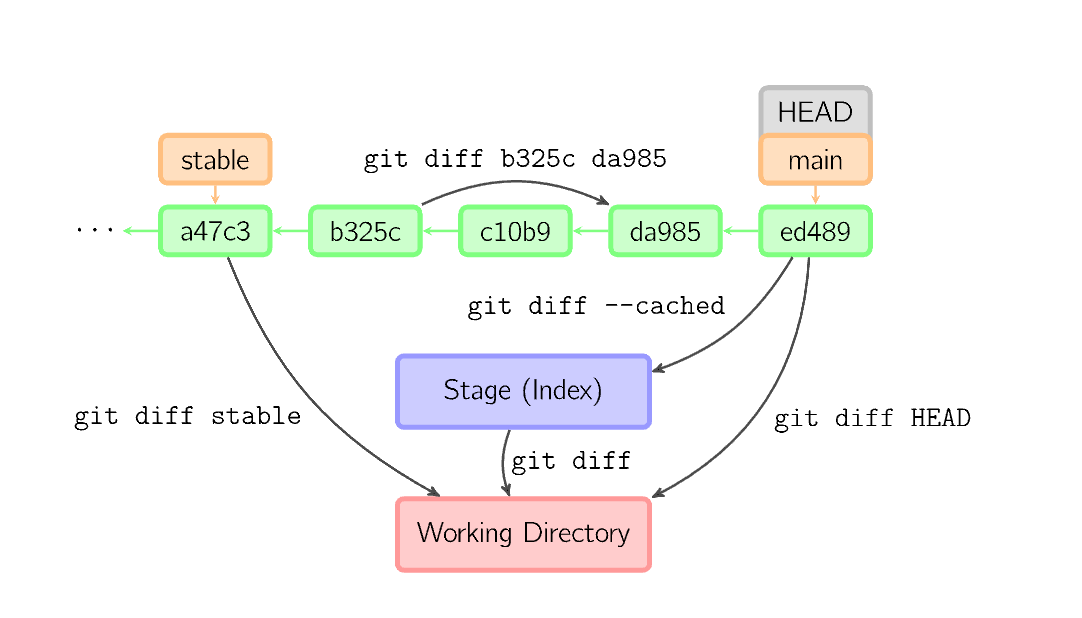
git diff:当工作区有改动,临时区为空,diff的对比是“工作区”与最后一次commit提交的仓库的共同文件”;当工作区有改动,临时区不为空,diff对比的是“工作区”与“暂存区”的共同文件”。
git diff --cached:显示暂存区与最后一次commit的改动。
git diff <分支1> <分支2>
显示两个分支最后一次commit的改动。
编辑距离(Edit Distance)是针对两个字符串S1和S2的差异程度进行量化,计算方式是看至少需要多少次的处理才能将S1变成S2(和S2变成S1是等价的),用 EditDis(S1,S2)表示。
import numpy as np
import matplotlib.pyplot as plt
from sklearn import metrics
from sklearn.datasets import make_blobs
from sklearn.cluster import KMeans
from sklearn.datasets import load_iris
%matplotlib inline
X,y = make_blobs(n_samples=100,n_features=2,centers=[[-1,-1],[0,0],[1,1],[2,2]],cluster_std=[0.4,0.2,0.2,0.2])#使用make_blobs生成训练数据,生成100个样本,每个样本2个特征,共4个聚类,聚类中心分别为[-1,-1],[0,0],[1,1],[2,2],聚类方差分别为0.4,0.2,0.2,0.2
plt.scatter(X[:,0],X[:,1])#画出训练样本的散点图,散点图的横坐标为样本的第一维特征,纵坐标为样本的第二维特征
plt.show()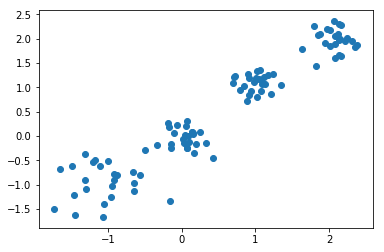
kmeans = KMeans(n_clusters=3)#生成kmeans分类器,聚类数量为3,其余参数使用默认值。
y_pred = kmeans.fit_predict(X)#使用fit_predict方法计算聚类中心并且预测每个样本的聚类索引。
plt.scatter(X[:,0],X[:,1],c=y_pred)#画出训练样本的散点图,散点图的横坐标为样本的第一维特征,纵坐标为样本的第二维特征,将各聚类结果显示为不同的颜色
plt.show()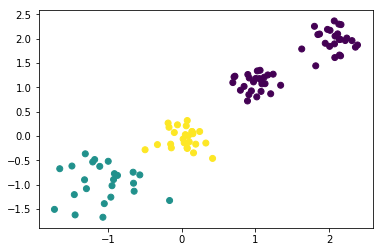
kmeans = KMeans(n_clusters=4)#生成kmeans分类器,聚类数量为4,其余参数使用默认值。
y_pred = kmeans.fit_predict(X)#使用fit_predict方法计算聚类中心并且预测每个样本的聚类索引。
plt.scatter(X[:,0],X[:,1],c=y_pred)#画出训练样本的散点图,散点图的横坐标为样本的第一维特征,纵坐标为样本的第二维特征,将各聚类结果显示为不同的颜色
plt.show()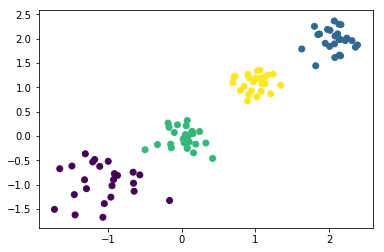
iris = load_iris() #导入iris数据集,iris数据集包含了150个样本,分别属于3类,每个样本包含4个特征
data_train=iris.data #iris样本集的样本特征
label_train=iris.target #iris样本集的样本标签kmeans = KMeans(n_clusters=3)#生成kmeans分类器,聚类数量为3,其余参数使用默认值。
y_predict = kmeans.fit_predict(data_train)#使用fit_predict方法计算聚类中心并且预测每个样本的聚类索引。
plt.scatter(data_train[:,0],data_train[:,2],c=y_predict)#画出训练样本的散点图,散点图的横坐标为样本的第一维特征,纵坐标为样本的第三维特征,将各聚类结果显示为不同的颜色
plt.show()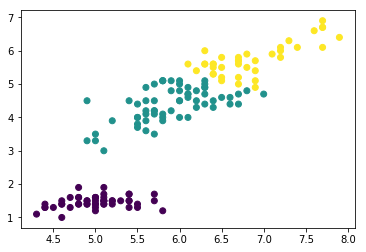
开始学习二叉树了
先来个简单题
https://leetcode-cn.com/problems/invert-binary-tree/
很简单
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, x):
# self.val = x
# self.left = None
# self.right = None
class Solution:
def invertTree(self, root: TreeNode) -> TreeNode:
if root == None:
return None
temp = root.left
root.left = root.right
root.right = temp
self.invertTree(root.left)
self.invertTree(root.right)
return roothttps://leetcode-cn.com/problems/symmetric-tree/
利用双向队列,每次把对称的两个对应的节点放入队列中,然后取出来比较,如果值不相等则返回false,如果一边为空 一边不为空也返回false 符合条件的话就继续搜索
https://leetcode-cn.com/problems/merge-two-sorted-lists/
利用递归的思想,比较两个当前值,因为是有序链表
# Definition for singly-linked list.
# class ListNode:
# def __init__(self, val=0, next=None):
# self.val = val
# self.next = next
class Solution:
def mergeTwoLists(self, l1: ListNode, l2: ListNode) -> ListNode:
if l1 == None:
return l2
if l2 == None:
return l1
if l1.val <= l2.val:
l1.next = self.mergeTwoLists(l1.next,l2)
return l1
else:
l2.next = self.mergeTwoLists(l1,l2.next)
return l2https://leetcode-cn.com/problems/maximum-points-you-can-obtain-from-cards/
滑动窗口题目,限定窗口大小然后滑动即可
class Solution:
def maxScore(self, cardPoints: List[int], k: int) -> int:
n = len(cardPoints)
# 滑动窗口大小为 n-k
windowSize = n - k
# 选前 n-k 个作为初始值
s = sum(cardPoints[:windowSize])
minSum = s
for i in range(windowSize, n):
# 滑动窗口每向右移动一格,增加从右侧进入窗口的元素值,并减少从左侧离开窗口的元素值
s += cardPoints[i] - cardPoints[i - windowSize]
minSum = min(minSum, s)
return sum(cardPoints) - minSumhttps://leetcode-cn.com/problems/sliding-window-median/
很明显的滑动窗口,首先定义一个求中位数的匿名函数,然后一点一点求出来
class Solution:
def medianSlidingWindow(self, nums: List[int], k: int) -> List[float]:
median = lambda a: (a[(len(a)-1)//2] + a[len(a)//2]) / 2
res = []
for i in range(len(nums)-k+1):
res.append(median(sorted(nums[i:i+k])))
return res在seq2seq这篇文章中详细介绍了seq2seq模型的细节,但是仅仅用一个语义编码c是完全不能够表示编码器的输入的,源的可能含义的数量是无限的。当编码器被迫将所有信息放入单个向量中时,它很可能会忘记一些东西。