pyplot
matplotlib.pyplot学习
绘图标记
import matplotlib.pyplot as plt
import numpy as np
ypoints = np.array([1,3,4,5,8,9,6,1,3,4,5,2,4])
plt.plot(ypoints, marker = 'o') # "o"代表实心圆
plt.show()maker可用的符号如下:
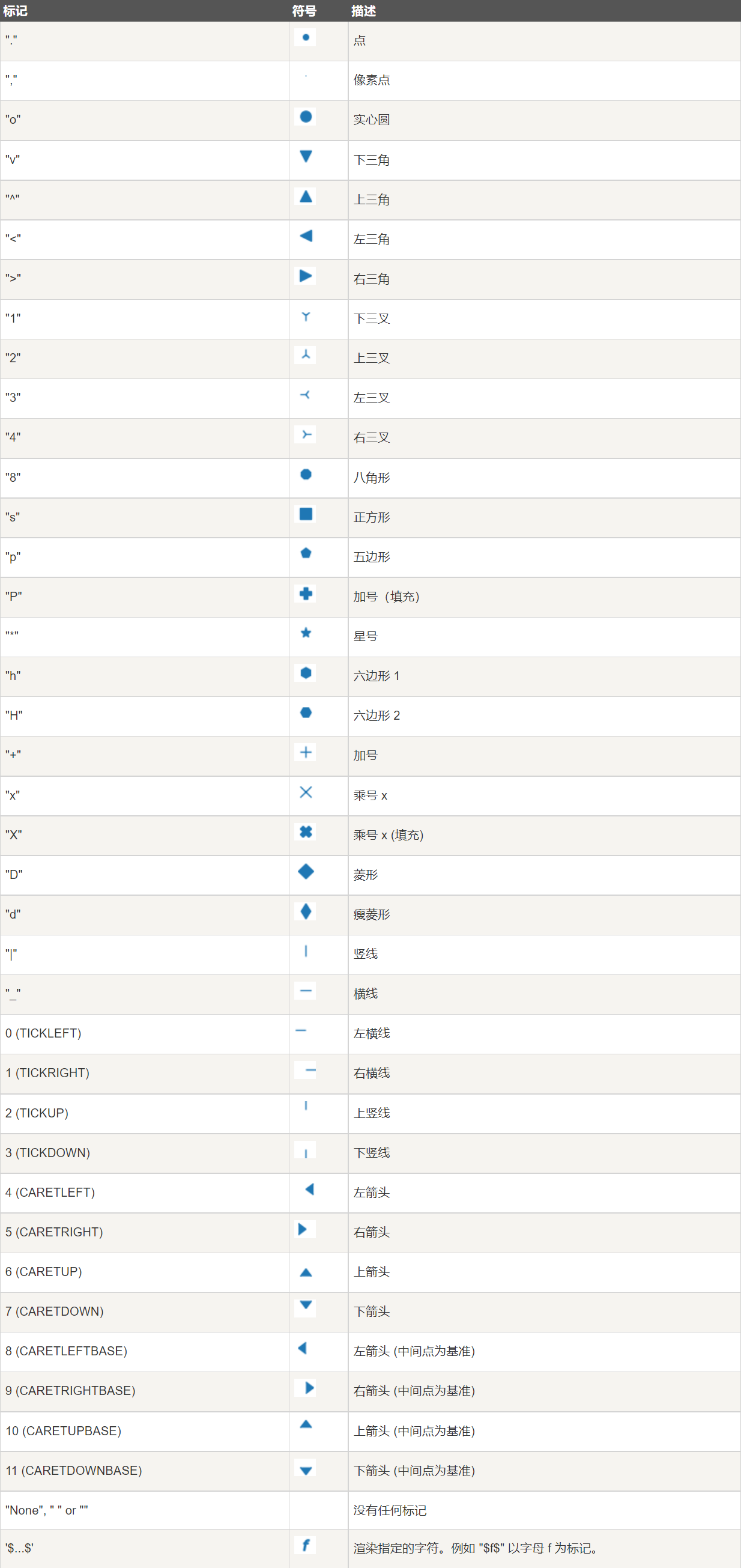
fmt参数
fmt = '[marker][line][color]'例如 o:r,o 表示实心圆标记,: 表示虚线,r 表示颜色为红色。