data_parallel
如果想将模型训练扩展到大的批次,则很快就会达到在单个 GPU
上可以做的极限。具体来说,会发生
RuntimeError: CUDA out of memory。 梯度累计、Activation checkpointing 和 CPU offloading
都可以一定程度上减少显存的占用,为了_有效地_扩展到更大的模型大小和不断增长的数据集,同时仍然在合理的时间内训练模型,我们需要将计算分布在一组机器上。
如果想将模型训练扩展到大的批次,则很快就会达到在单个 GPU
上可以做的极限。具体来说,会发生
RuntimeError: CUDA out of memory。 梯度累计、Activation checkpointing 和 CPU offloading
都可以一定程度上减少显存的占用,为了_有效地_扩展到更大的模型大小和不断增长的数据集,同时仍然在合理的时间内训练模型,我们需要将计算分布在一组机器上。
分为zero1、zero2、zero3,虽然zero3对模型进行了分割,但是本质上还是属于数据并行,因为在前向传播和反向传播需要all-gather模型参数,需要完整的模型权重。
FLOPs, floating point operations, 表示浮点数运算次数,衡量了计算量的大小。 如何计算矩阵乘法的 FLOPs 呢? 对于 \(A\in R^{1\times n},B\in R^{n\times1}\) ,计算 \(AB\) 需要进行 \(n\) 次乘法运算和 \(n\) 次加法运算,共计 \(2n\) 次浮点数运算,需要 \(2n\) 的 FLOPs。对于 \(A\in R^{m\times n},B\in R^{n\times p}\) ,计算 \(AB\) 需要的浮点数运算次数为 \(2mnp\) 。
All-reduced=all-gather+reduce-scatter
核心功能:将每个节点的部分数据汇总到所有节点,最终所有节点拥有完整数据副本。
适用场景:模型并行中的参数同步、全局统计信息聚合。
batch_size的复杂性来自于tp、dp、sp,引用一下浅入理解verl中的batch_size的解释:
vllm + fsdp 训推时,如果每张卡都是一个 DP,事情会简单很多。但 verl 中有两个功能不满足这一条件,一是 rollout 时让 vllm 开启 TP,二是在 fsdp 中使用 ulysses(SP)。verl 中数据分发使用的是 dispatch mode 这一机制,比如 fsdp workers 主要使用
Dispatch.DP_COMPUTE_PROTO这个 mode,它是在 worker group 的层次上进行数据分发以及结果收集的。由于这个层次是没有 TP/SP 概念的,所以它仅在 one GPU one DP 时才是正确的。那么为了正确支持 TP/SP,就需要对数据做一些前后处理。
首先介绍一下最主要的 self-attention,可以说是 self-attention 实现了上述的 token 之间交互的功能。
自注意力是模型的关键组成部分之一。注意和自注意之间的区别在于,自注意在相同性质的表示之间运行:例如,某个层中的所有编码器状态。
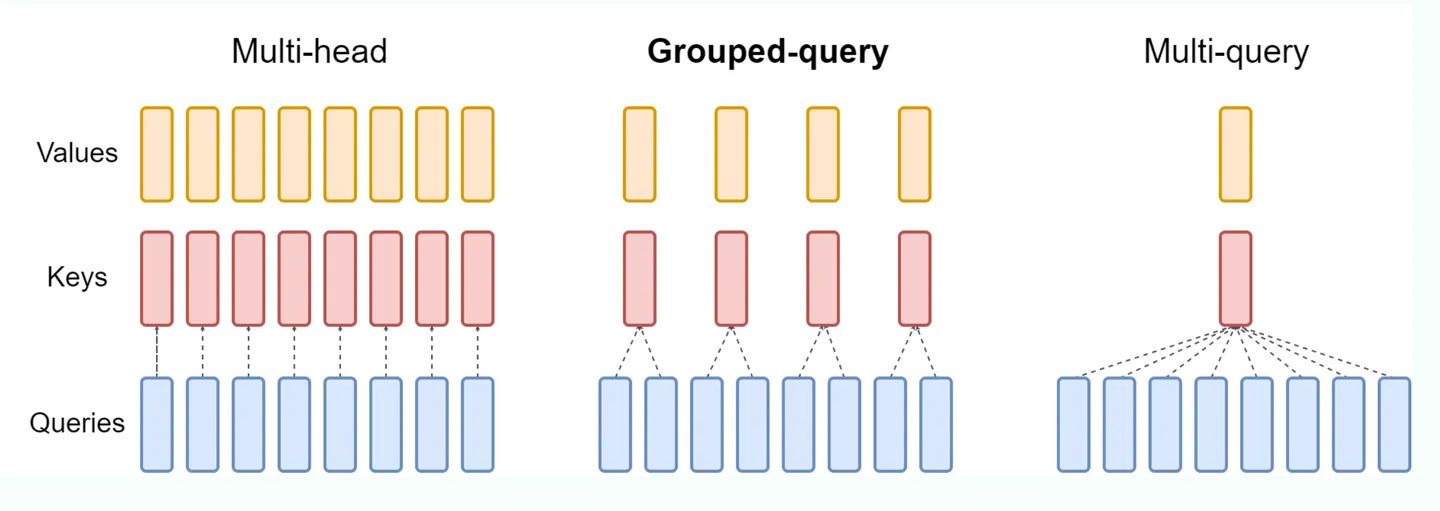
标准的 mha 中,KV heads 的数量和 Query heads 的数量相同,每一个 q head 对应一个独立的 kv head,但这样的开销比较大。 MQA (Multi Queries Attention): MQA 比较极端,只保留一个 KV Head,多个 Query Heads 共享相同的 KV Head。这相当于不同 Head 的 Attention 差异,全部都放在了 Query 上,需要模型仅从不同的 Query Heads 上就能够关注到输入 hidden states 不同方面的信息。这样做的好处是,极大地降低了 KV Cache 的需求,但是会导致模型效果有所下降。(层内共享)
DAPO 是对 GRPO 的改进。DAPO(Decoupled Clip and Dynamic sAmpling Policy Optimization,即解耦裁剪和动态采样策略优化)的优化点有四个(其中前 2 个是主要亮点,是命名的来源)