两个数的交换
# a = 1
# b = 2
# temp = b
# b = a
# a = temp
# print(a,b)
a = 1
b = 2
a,b = b,a
print(a,b)
2 1
格式化字符串
a = 17
name = "wlb"
# print('%s is %d years old' % (name,a))
# print('{} is {} years old'.format(name,a))
print(f'{name} is {a} years old') #明显这个方法更简单
wlb is 17 years old
yield与yield from
def fib(n):
a = 0
b = 1
for _ in range(n):
yield a
a,b = b,a+b
for i in fib(10):
print(i)
#注释的内容与yield a效果相同,yield相当于使其成为一个迭代器 yield一个数后会立马传递出去,而return 要等列表都生成完毕后才会传出去
#他的优势在于一些耗时的操作
# 通过yield来进行dfs,由于没有实现__next__因此是个可迭代对象而不是一个迭代器
class Node:
def __init__(self,value) -> None:
self._value = value
self._node = []
def __repr__(self) -> str:
return f'Node({self._value})'
def add_children(self,node:'Node') -> 'Node':
self._node.append(node)
def __iter__(self):
return iter(self._node)
def dfs(self):
yield self
for i in self:
yield from i.dfs()
root = Node(0)
children1 = Node(1)
children2 = Node(2)
root.add_children(children1)
root.add_children(children2)
children1.add_children(Node(3))
children1.add_children(Node(4))
children11 = Node(5)
children2.add_children(children11)
children11.add_children(Node(6))
for c in root.dfs():
print(c)
from typing import Iterable
def test_format(datas: Iterable[str], max_len: int):
for data in datas:
if len(data) > max_len:
yield data[:max_len] + '...'
else:
yield data
print(list(test_format(['vllbc', 'test_for_this_function', 'good'],5)))
# 把长度大于5的部分变成省略号
#子生成器
def average_gen():
total = 0
count = 0
average = 0
while True:
new_num = yield average
if new_num is None:
break
count += 1
total += new_num
average = total/count
return total,count,average
# 委托生成器
def proxy_gen():
while True:
total,count,average = yield from average_gen() # yield from后面是一个可迭代对象,此文后面的将多维数组转化为一维数组中flatten函数就用到了yield from,原理就是如果列表中一个元素是列表就yield from这个列表,否则就直接yield这个元素,也利用了递归的方法。如果子生成器退出while循环了,就执行return以获取返回值。
print(total,count,average)
def main():
t = proxy_gen()
next(t)
print(t.send(10))
print(t.send(15))
print(t.send(20))
t.send(None)
main()
列表解析式
lists = [f"http://www.baidu.com/page{n}" for n in range(21)]
lists#此方法在爬虫构造urls中非常常用
# lists = [f"http://www.baidu.com/page{n}" for n in range(21) if n%2==0] page偶数
# alp = "abcdefghigklmnopqrstuvwxyz"
# ALP = [n.upper() for n in alp] 将小写转换为大写
enumerate
lists = ['apple','banana','cat','dog']
for index,name in enumerate(lists):
print(index,name)
# 手动实现一下enumerate
from typing import Iterable
def enumerate_(Iterable:Iterable,start=0):
yield from zip(range(start,start+len(Iterable)),Iterable)
for i,item in enumerate_([1,2,3,4,5,6],9):
print(i,item)
字典的合并
dic1 = {'qq':1683070754,
'phone':123456789
}
dic2 = {
'height':180,
'handsome':True
}
dic3 = {**dic1,**dic2}
#合并两个字典 **叫做解包
#或者用dic1.update(dic2) 将dic2合并到dic1 相同键则dic2替代dic1
dic3
{'handsome': True, 'height': 180, 'phone': 123456789, 'qq': 1683070754}
序列解包
name = "wang lingbo"
xing,ming = name.split(" ") #split返回一个序列,分别赋给xing 和ming
print(xing,ming)
#x,*y,z = [1,2,3,4,5]
#x:1 z:5 y:[2,3,4]
wang lingbo
匿名函数lambda
lists = [1,2,3,4,5,6]
maps = map(lambda x:x*x,lists)
print(maps)
print(list(maps))
<map object at 0x000001911C8E03C8>
[1, 4, 9, 16, 25, 36]
装饰器
def logging(level):
def wapper(func):
def inner_wapper(*args, **wbargs):
print(f'{level} enter in {func.__name__}()')
return func(*args, **wbargs) #不写return 也可以
return inner_wapper
return wapper
@logging('inner')
def say(a):
print('hello! {}'.format(a))
say('wlb')
inner enter in say()
hello! wlb
import time
def print_time(func):
def wapper(*args,**wbargs):
print(f'{func.__name__}()调用于{time.asctime(time.localtime(time.time()))}')
return func(*args,**wbargs) #不写return 也可以
return wapper
@print_time
def my_name(name):
print(f'look!{name}')
my_name("wlb")
my_name()调用于Wed Dec 9 21:21:00 2020
look!wlb
map、reduce、filter
# map
print(list(map(abs,[-1,-2,-3,-4,-5]))) #也可以自己定义函数或者用匿名函数
# reduce
from functools import reduce #python3中需要从内置库导入
print(reduce(lambda x,y:x+y,list(map(int,str(131351412)))))
# filter
a = [1,2,3,4,5,6,7,8,9]
new_a = filter(lambda x:x%2!=0,a) #filter就是筛选
list(new_a)
# 这三个都是函数式编程中常用的函数
join()
# lists = ['1','2','3','4','5']
# ''.join(lists)
lists = [1,2,3,4,5]
''.join(list(map(str,lists))) #join只能是字符串列表,所以要map转换一下
'12345'
将多维数组转换为一维
ab = [[1, 2, 3], [5, 8], [7, 8, 9]]
print([i for item in ab for i in item]) #利用列表解析式
print(sum(ab, [])) # 利用sum函数
from functools import reduce
print(reduce(lambda x,y:x+y,ab)) # 利用reduce
from itertools import chain
print(list(chain(*ab))) # 利用chain
def flatten(items,ignore=(str,bytes)):
for x in items:
if isinstance(x,Iterable) and not isinstance(x,ignore):
yield from flatten(x)
else:
yield x
print(list(flatten(ab))) # 利用自己定义的函数
[1, 2, 3, 5, 8, 7, 8, 9]
将一个列表倒序
lists = [2,4,3,2,5,4]
lists[::-1]
# list(reversed(lists))
随机生成密码
import random
b = 8
t = 'abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890'
print(''.join(random.sample(t,b))) # 主要就是用sample这个方法来取多个随机值
0KmtEZSU
断言
assert(True is True) #成功
print('yes')
assert(True is False) #报错
print('no')
yes
合并列表
list1 = [1,2,31,13]
list2 = [5,2,12,32]
# list1.append(list2)
# print(list1) #错误方法
list1.extend(list2)
print(list1) #正确方法
[1, 2, 31, 13, 5, 2, 12, 32]
a = [1,2,3,4,5]
b = ['a','b','c','d','e']
fin = dict()
for k,i in zip(a,b):
fin[k] = i
print(fin) # {1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e'}
# 或者
d = {}
for i,d[i] in zip(a,b):
pass
print(d) # {1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e'} 为什么?在WTFpython中有讲
# 或者
fin = dict(zip(a,b))
print(fin) # {1: 'a', 2: 'b', 3: 'c', 4: 'd', 5: 'e'}
对list进行解包
lists = ['dog','cat','you']
print(*lists)
#想对一个列表进行zip操作时,可以这样
print(list(zip(*lists)))
def test(*args):
print("args:",args)
test(*lists)
dog cat you
[('d', 'c', 'y'), ('o', 'a', 'o'), ('g', 't', 'u')]
args:('dog','cat','you')
对类的一些操作
class Test:
x = 1
y = 2
print(Test.x,Test.y) #==>print(Test().x,Test().y)
class Test:
def __init__(self,x,y):
self.x = x
self.y = y
test = Test(1,2)
print(test.x,test.y)
1 2
1 2
class Test:
def __init__(self,maxlen):
self.maxlen = maxlen
self.lists = []
def put(self,*args):
for i in args:
if len(self.lists) <= self.maxlen:
self.lists.append(i)
else:
break
def get(self):
return self.lists.pop()
def empty(self):
if len(self.lists) != 0:
return False
else:
return True
def __len__(self):
return len(self.lists)
def __del__(self):
print("del this class")
def printfs(self):
return self.lists
test = Test(10)
test.put(1,2,3,4,5,6)
print(test.empty())
print(len(test))
print(test.printfs())
test.__del__() #直接调用test还存在,__del__是析构函数,垃圾回收时就会调用a
print(test)
#del test
#print(test) 这时候就会报错,因为del将test这个对象直接删除了
False
6
[1, 2, 3, 4, 5, 6]
del this class
<__main__.Test object at 0x0000021B7DF33EB0>
del this class
一些内置函数
all([True,True,False]) #False
all([True,True,True]) #True
any([True,True,False]) #True
any([True,False,False])#True
any([False,False]) #False
import random
for i in iter(lambda:random.randint(1,10),5):
print(i)
#相当于
while True:
x = random.randint(1,10)
print(x)
if x == 5:
break
iter(object[, sentinel])
sentinel为可选参数,若不传入,则object必须为可迭代对象,传入则必须为可调用对象,当可调用对象的返回值为sentinel抛出异常,但for循环会处理这个异常,这常常用于IO操作
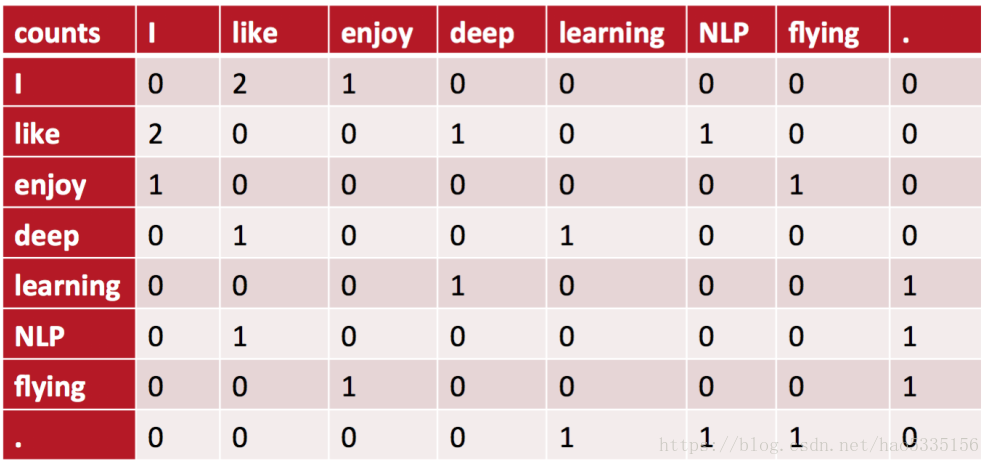 例如:“I like”出现在第1,2句话中,一共出现2次,所以=2。
例如:“I like”出现在第1,2句话中,一共出现2次,所以=2。