melt
pd.melt
用法
直观的看就是将宽数据转化为长数据。转化为variable-value这样的形式。
pandas.melt(frame, id_vars=None, value_vars=None, var_name=None, value_name='value', col_level=None)参数解释:
- frame:要处理的数据集。
- id_vars:不需要被转换的列名。
- value_vars:需要转换的列名,如果剩下的列全部都要转换,就不用写了。
- var_name和value_name是自定义设置对应的列名。
- col_level :如果列是MultiIndex,则使用此级别。 ## 实例
import pandas as pd
df = pd.DataFrame({'A': {0: 'a', 1: 'b', 2: 'c'},
'B': {0: 1, 1: 3, 2: 5},
'C': {0: 2, 1: 4, 2: 6}
})
df
'''
A B C
0 a 1 2
1 b 3 4
2 c 5 6
'''pd.melt(df, id_vars=['A'], value_vars=['B'])
'''
A variable value
0 a B 1
1 b B 3
2 c B 5
'''
pd.melt(df, id_vars=['A'], value_vars=['B', 'C'])
'''
A variable value
0 a B 1
1 b B 3
2 c B 5
3 a C 2
4 b C 4
5 c C 6
'''pd.melt(df, id_vars=['A'], value_vars=['B'],
var_name='myVarName', value_name='myValueName')
'''
A myVarName myValueName
0 a B 1
1 b B 3
2 c B 5
'''pd.melt(df, id_vars=['A'], value_vars=['B', 'C'],
ignore_index=False)
'''
A variable value
0 a B 1
1 b B 3
2 c B 5
0 a C 2
1 b C 4
2 c C 6
'''# 多重索引
df.columns = [list('ABC'), list('DEF')]
df
'''
A B C
D E F
0 a 1 2
1 b 3 4
2 c 5 6
'''
# 选择最外层索引
pd.melt(df, col_level=0, id_vars=['A'], value_vars=['B'])
'''
A variable value
0 a B 1
1 b B 3
2 c B 5
'''
# 选择内层索引
pd.melt(df, col_level=1, id_vars=['D'], value_vars=['E'])
# 选择复合索引
pd.melt(df, id_vars=[('A', 'D')], value_vars=[('B', 'E')])
'''
(A, D) variable_0 variable_1 value
0 a B E 1
1 b B E 3
2 c B E 5
''' 变成了:
变成了: 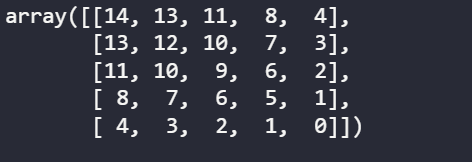
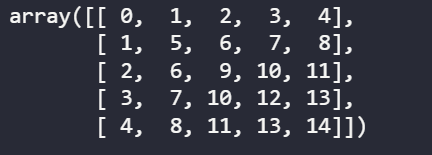
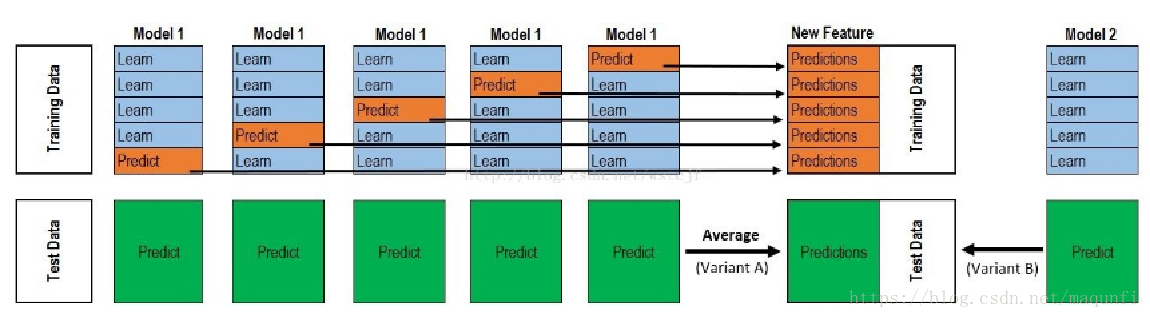 以这个5折stacking为例:
以这个5折stacking为例: