GAN
简介
生成对抗网络(Generative Adversarial Network,简称GAN)是无监督学习的一种方法,通过让两个神经网络相互博弈的方式进行学习。
大白话: 说就是生成对抗网络有一个生成网络和一个判别网络,假设有一个真实数据和一个生成网络生成的假数据,那么判别网络就是识别出这两种数据,判别网络努力分类成功,生成网络努力生成和真实数据相似的数据使判别网络分类不出来。这就是所说的相互博弈的方式。
LDA
线性判别分析LDA(Linear Discriminant Analysis)
线性判别分析,也就是LDA(与主题模型中的LDA区分开),现在常常用于数据的降维中,但从它的名字中可以看出来它也是一个分类的算法,而且属于硬分类,也就是结果不是概率,是具体的类别,一起学习一下吧。
GRU
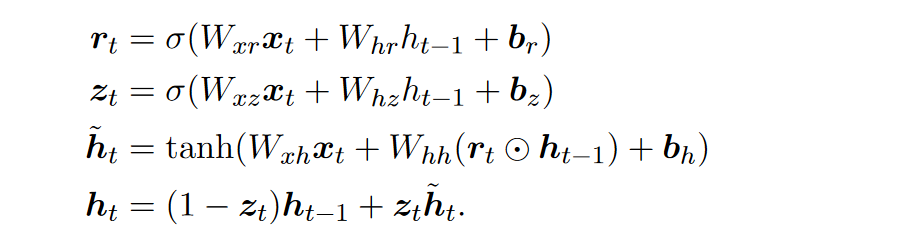
其中\(r_{t}\)为reset门,用于重置上一step的状态。\(z_{t}\)为update门,用于得到当前step的状态。
bincount

很简单,就是统计x中的数出现次数,返回结果的最大长度就是x中的最大值+1,idx为对应的数,值为出现的次数,没有出现的为0。
x = np.array([7, 6, 2, 1, 4])
# 索引0出现了0次,索引1出现了1次......索引5出现了0次......
np.bincount(x)
#输出结果为:array([0, 1, 1, 0, 1, 0, 1, 1])weight这个参数也很好理解,x会被它加权,也就是说,如果值n发现在位置i,那么out[n] += weight[i]而不是out[n] += 1。所以weight必须和x等长。
把数字翻译成字符串
把数字翻译成字符串
题目:
https://leetcode-cn.com/problems/ba-shu-zi-fan-yi-cheng-zi-fu-chuan-lcof/
思路:
dp思想,不用管是什么字符,定义dp[i]为长度为i时 有多少个方法
代码:
class Solution:
def translateNum(self, num: int) -> int:
s = str(num)
if len(s) < 2:
return 1
dp = [0] * len(s)
dp[0] = 1
dp[1] = 2 if int(s[0] + s[1]) < 26 else 1
for i in range(2,len(s)):
dp[i] = dp[i-1] + dp[i-2] if int(s[i-1] + s[i]) < 26 and s[i-1] != '0' else dp[i-1]
return dp[-1]注意如果长度小于等于1 则直接返回1
seq2seq
Seq2Seq
(本文只介绍最原始的seq2seq,带有注意力在attention文章中)
RNN
有关RNN
Seq2Seq是典型的Encoder-decoder框架的模型,其中编码器和解码器都采用的RNN模型或者RNN模型的变体:GRU、LSTM等。
DBSCAN
DBSCAN属于密度聚类的一种。通常情形下,密度聚类算法从样 本密度的角度来考察样本之间的可连接性,并基于可连接样本不断扩展聚类簇 以获得最终的聚类结果。
关联规则概念
参考:https://www.cnblogs.com/bill-h/p/14863262.html
大家可能听说过用于宣传数据挖掘的一个案例:啤酒和尿布;据说是沃尔玛超市在分析顾客的购买记录时,发现许多客户购买啤酒的同时也会购买婴儿尿布,于是超市调整了啤酒和尿布的货架摆放,让这两个品类摆放在一起;结果这两个品类的销量都有明显的增长;分析原因是很多刚生小孩的男士在购买的啤酒时,会顺手带一些婴幼儿用品。
字符串转换整数 (atoi)
字符串转换整数 (atoi)
https://leetcode-cn.com/problems/string-to-integer-atoi/
#重点是正则表达式
class Solution:
def myAtoi(s: str):
import re
ss = re.findall("^[\+\-]?\d+",s.strip())
res = int(*ss)
if res > (231-1):
res = (231-1)
if res < -231:
res = -231
return resWA了四次才整出来,太菜了,以为很简单,没有认真读题,要吸取教训。