KMP
KMP是字符串匹配问题的算法。“字符串A是否为字符串B的子串?如果是的话出现在B的哪些位置?”该问题就是字符串匹配问题,字符串A称为模式串,字符串B称为主串。
KMP是字符串匹配问题的算法。“字符串A是否为字符串B的子串?如果是的话出现在B的哪些位置?”该问题就是字符串匹配问题,字符串A称为模式串,字符串B称为主串。
特征选择是特征工程里的一个重要问题,其目标是寻找最优特征子集。特征选择能剔除不相关(irrelevant)或冗余(redundant
)的特征,从而达到减少特征个数,提高模型精确度,减少运行时间的目的。另一方面,选取出真正相关的特征简化模型,协助理解数据产生的过程。并且常能听到“数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已”,由此可见其重要性。但是它几乎很少出现于机器学习书本里面的某一章。然而在机器学习方面的成功很大程度上在于如果使用特征工程。
早停止(Early Stopping)是 当达到某种或某些条件时,认为模型已经收敛,结束模型训练,保存现有模型的一种手段。
如何判断已经收敛?主要看以下几点: - 验证集上的Loss在模型多次迭代后,没有下降 - 验证集上的Loss开始上升。 这时就可以认为模型没有必要训练了,可以停止了,因为训练下去可能就会发生过拟合,所以早停法是一种防止模型过拟合的方法。
Focal Loss主要是为了解决类别不平衡的问题,Focal Loss可以运用于二分类,也可以运用于多分类。下面以二分类为例:
原始的二分类: 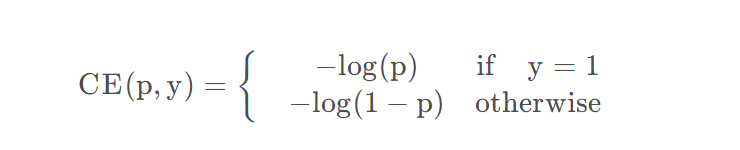
其中 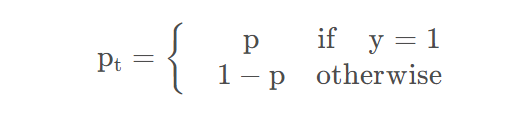
在训练开始的时候,如果学习率太高的话,可能会导致loss来回跳动,会导致无法收敛,因此在训练开始的时候就可以设置一个很小的learning rate,然后随着训练的批次增加,逐渐增大学习率,直到达到原本想要设置的学习率。
神经网络会促使自身往正确标签和错误标签差值最大的方向学习,在训练数据较少,不足以表征所有的样本特征的情况下,会导致网络过拟合。因为onehot本身就是一个稀疏的向量,如果所有无关类别都为0的话,就可能会疏忽某些类别之间的联系。 具体的缺点有: - 真是标签与其它标签之间的关系被忽略了,很多有用的知识学不到了。 - 倾向于让模型更加武断,导致泛化性能差 - 面对有噪声的数据更容易收到影响。
大的batchsize收敛到sharp minimum,而小的batchsize收敛到flat minimum,后者具有更好的泛化能力。两者的区别就在于变化的趋势,一个快一个慢,如下图,造成这个现象的主要原因是小的batchsize带来的噪声有助于逃离sharp minimum。
$$ {} {(x,y) }U[{r{adv}}L(,x+r_{adv},y)]
$$
$$ {} -P(y |x+r{adv};)
所谓的不平衡指的是不同类别的样本量差异非常大,或者少数样本代表了业务的关键数据(少量样本更重要),需要对少量样本的模式有很好的学习。样本类别分布不平衡主要出现在分类相关的建模问题上。样本类别分布不平衡从数据规模上可以分为大数据分布不平衡和小数据分布不平衡两种。