MQA
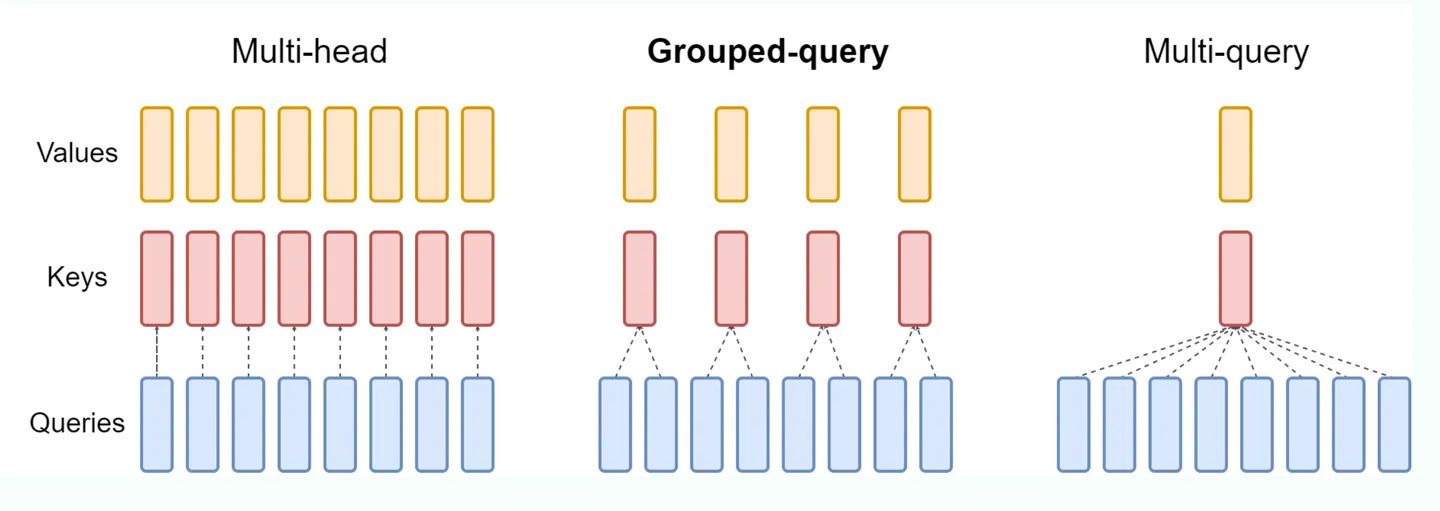
标准的 mha 中,KV heads 的数量和 Query heads 的数量相同,每一个 q head 对应一个独立的 kv head,但这样的开销比较大。 MQA (Multi Queries Attention): MQA 比较极端,只保留一个 KV Head,多个 Query Heads 共享相同的 KV Head。这相当于不同 Head 的 Attention 差异,全部都放在了 Query 上,需要模型仅从不同的 Query Heads 上就能够关注到输入 hidden states 不同方面的信息。这样做的好处是,极大地降低了 KV Cache 的需求,但是会导致模型效果有所下降。(层内共享)