MoE
MoE 的思想类似于集成学习中的 Ensemble Learning。MoE 作用于原本 transformer 模型的 MLP 层,即:
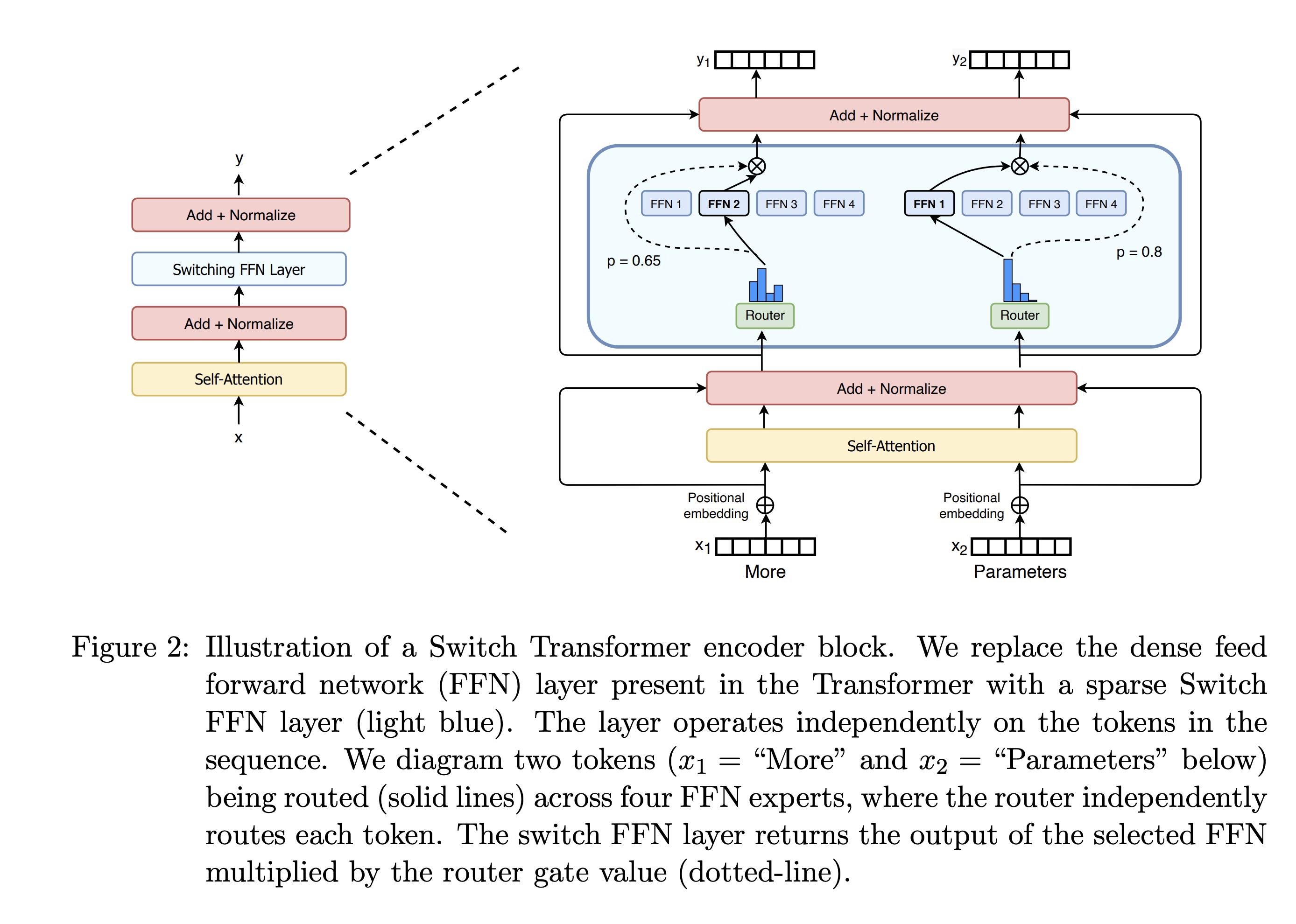 图片来自于Switch Transformers: Scaling to Trillion
Parameter Models with Simple and Efficient Sparsity 论文。
图片来自于Switch Transformers: Scaling to Trillion
Parameter Models with Simple and Efficient Sparsity 论文。
总结来说,在混合专家模型 (MoE) 中,我们将传统 Transformer 模型中的每个前馈网络 (FFN) 层替换为 MoE 层,其中 MoE 层由两个核心部分组成: 一个路由器(或者叫门控网络)和若干数量的专家。
用多个 FeedForward 块替换单个 FeedForward 块 (如在 MoE 设置中所做的那样)会大大增加模型的总参数数。然而,关键的诀窍是,我们不会对每个token使用(“激活”)所有专家。相反,路由器仅为每个token选择一小部分专家。
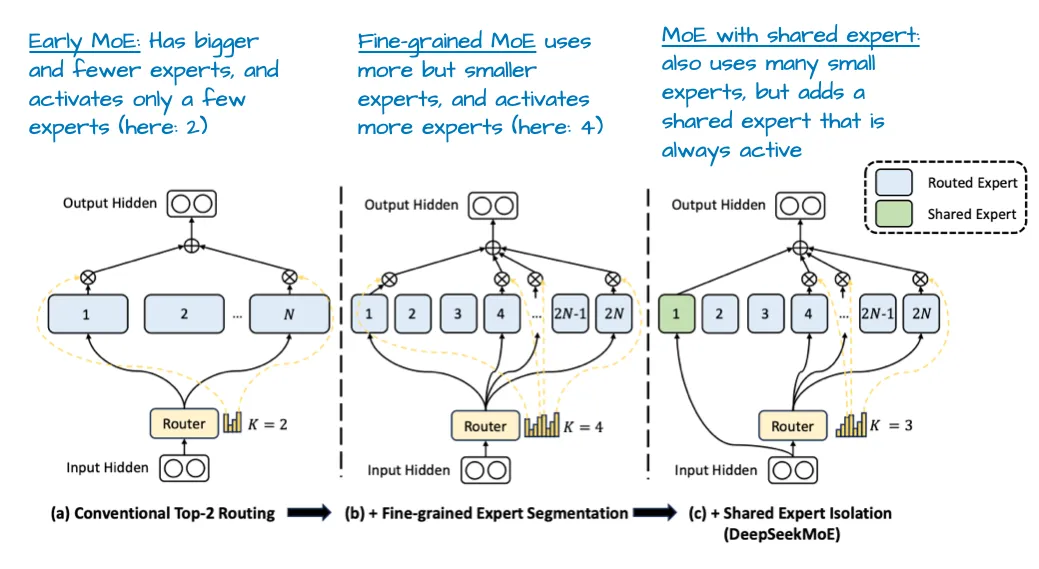
技术选择
- Expert Choice 路由(容量为 2,即每个专家选两个 token)在 NLP 模型效果好,Top-K 路由则在视觉模型效果好。
- 在 NLP 任务中,专家越多越好,而视觉任务中存在饱和点。
- 增加 MoE 层数也可以增加模型容量,但视觉任务中同样存在饱和点。
- 恢复优化器状态(一些统计量)和路由权重归一化可以提高视觉 MoE 模型的性能,对 NLP 任务无效。
八股
