MLA
在标准的 Transformer中,多头注意力(Multi-Head Attention, MHA)机制通过并行计算多个注意力头来捕捉输入序列中的不同特征。每个注意力头都有自己的查询(Query, Q)、键(Key, K)和值(Value, V)矩阵,计算过程如下:
- 查询矩阵 Q:用于计算输入序列中每个位置的注意力权重。
- 键矩阵 K:用于与查询矩阵 Q 计算注意力分数。
- 值矩阵 V:用于根据注意力分数加权求和,得到最终的输出。
MLA 的核心思想是通过低秩联合压缩技术,减少训练时的激活占用和推理时的 kv cache 的占用,从而节省显存。
核心思想
当前我要存的K cache是4个k_head,但如果我能从这4个k_head中抽取出1份共有的信息,然后在做attn计算时,每个head都用这1份共有的信息做计算,那么我也只需存这1份共有信息作为K cache了。这样我就把K cache从原来num_heads = 4变成num_heads = 1,这不就能节省K cache了吗? 但是等等,现在共有的k_head信息是抽取出来了,那么相异的k_head信息呢?(简单来说,就是由 \(W_{K}\) 不同head部分学习到的相异信息)。我们当然是希望k_head间相异的信息也能保留下来,那么该把它们保留至哪里呢?当你回顾attn_weights的计算公式时,一个想法在你脑中闪现:q部分不是也有heads吗!我可以把每个k_head独有的信息转移到对应的q_head上吗!写成公式解释就是: 原来 \(attention\_weights=(W_{Q}h_{i})^T * (W_{k}h_{j})\) ,括号表示运算顺序,即先各自算2个括号内的,再做 * 计算 现在 \(attention\_weights=(h_{i}^TW_{Q}W_{k})^T * h_{j}\),同理括号表示运算顺序。也就是说,这里我们通过矩阵乘法的交换律,巧妙地把1个token上k_heads独有的信息转移到了对应的q_head上来,这样1个token上k_heads间共享的相同信息就能被我们当作K cache存储下来。
(在这里,你可以抽象地把 \(h_{j}\) 理解成是4个k_heads共享的信息,但最终K cache的形式还会在这基础上有所变化。我知道此时你脑海中一定有很多疑惑。但我们先不要纠结细节的问题,因为在后文会展示全部细节,这里我们要做的是从宏观上理解MLA设计的核心思想。)
上述叙述来自再读MLA,还有多少细节是你不知道的
因此 MLA 的核心思想就是找到一个压缩的 \(h_{j}\) 来表示所有 head 的共有信息,而将 head 之间相异信息让 q 来吸收,这样就大大压缩了 k 的 head_num,v 也是同理,不同是 \(W_{V}\) 和 \(W_{O}\) 吸收。因此 MLA 并没有损失信息,而是将信息转移到了 q_head 上。总维度并没有减少。
苏神思路
我认为先看苏神的博客再去看猛猿大佬的博客是比较容易理解的。
苏神认为 MLA 是在 GQA 的基础上将简单的线性变换(分割、复制)换成一般的线性变换来增强模型的能力。GQA 也可以看作是一种低秩投影。原因见原文:

其中 g 是组数。这里的 c 只是简单的拼接,MLA
的初始想法就是使用一种线性转换代替拼接。这个线性转换也是一个可以学习的矩阵
\(W\)。因此一个自然的想法就出来了:

然而这种方法在推理阶段并不会减少 kv cache
的显存占用,我们还是需要存储 k 和 v 而不是 c,并且 kv cache 大小反而和
MHA 一样大了。这时引入一个恒等变换就可以解决问题: 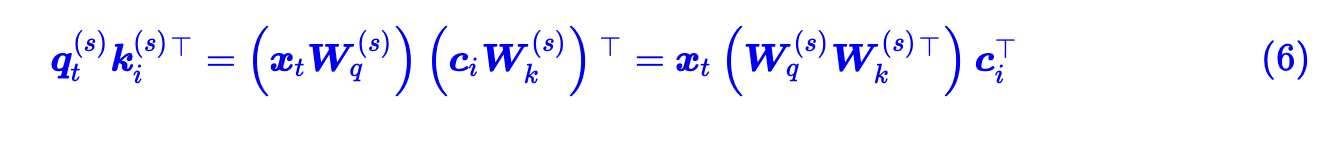
这样就可以把 c 取代原来的 k,而把两个 W 当作新的 Q,同理后面可以把 Wv 和 Wo 合并,v 也可以用 c 取代。这个 c 就是上面说的所有 head 的共享信息。而相异信息放入了新的 Q 中来学习。这样在推理阶段就可以只保存 c 来作为 kv cache 了。所以可以降低 c 的维度来进一步降低显存占用。
现在成功降低了显存占用,但有了一个新问题,如何在这里引入 rope 呢,众所周知 rope 是在计算注意力分数时加入了位置信息。如果强行加入则会产生下面的问题:
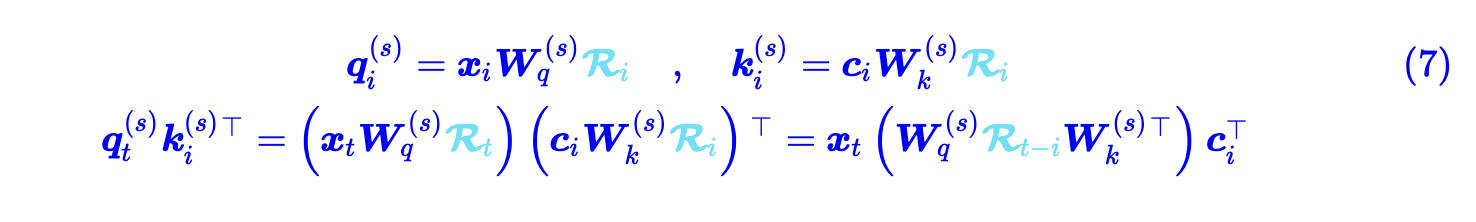
也就是新的 Q 矩阵与 i 有关,而不是固定的一个矩阵了。
解决的办法也简单粗暴,就是在 q 和 k 的维度上增加 rope 的维度。也就是:

其中前半部分是 nope,后半部分是
rope,这个在后面猛猿大佬讲解的源码中会有体现。 最后为了降低激活值,又对
q 进行了低秩投影,最后变成了: 
至于为什么 q 的 rope 项是 c,而 k 的 rope 项是 x,这个我也不清楚。在训练阶段,MLA 只是在 MHA 的基础上加了低秩投影,以及为了 rope 的计算在原本 dk 的维度上增加了 dr 维度。
区别在于解码阶段,MLA 可以像 MQA 一样简单: 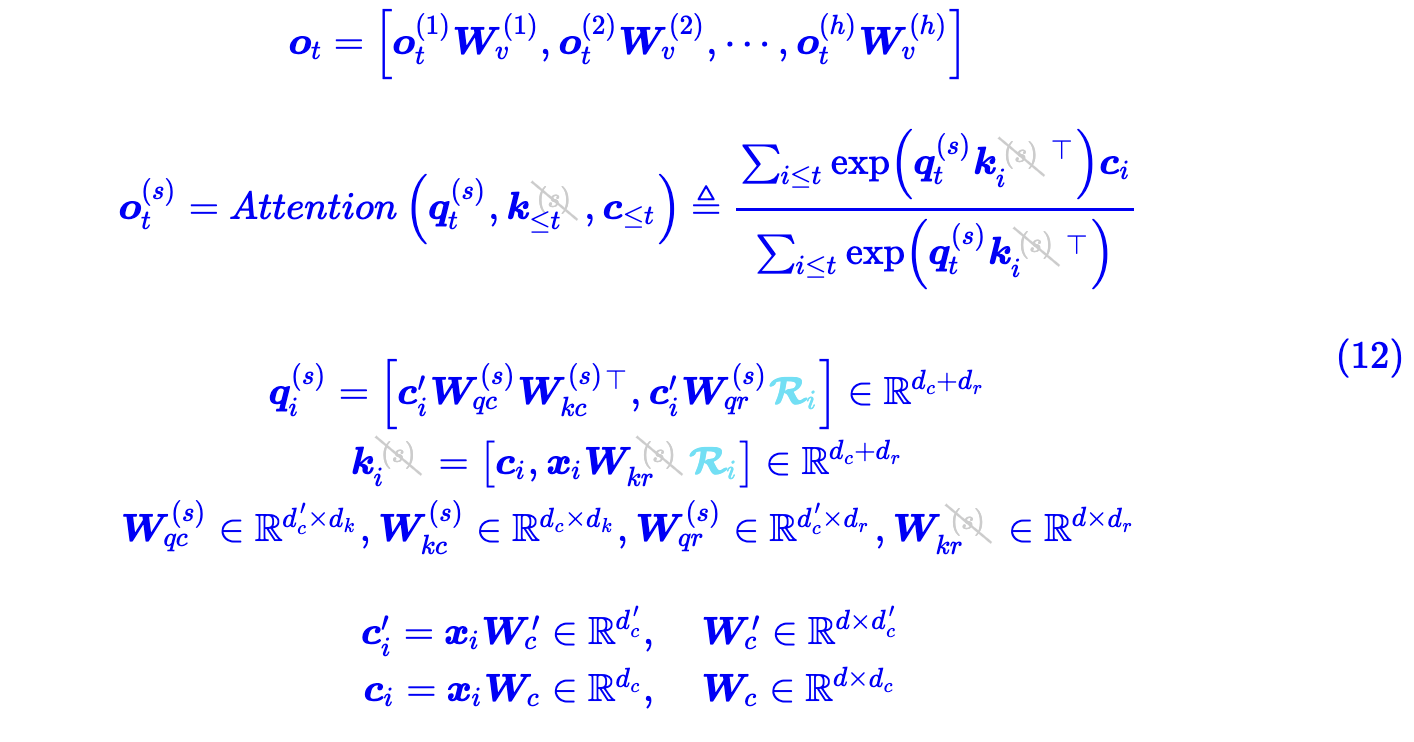
在解码阶段,只需要保存 c(注意 c 是 k 和 v 的集合体),这大大降低了显存占用。苏神博客写 prefill 阶段使用 (10),generation 阶段使用 (12),因为 prefill 是 compute-bound,需要降低计算量,而 generation 阶段是 memory-bound,需要降低显存占用,这样结合完美符合我们的需求。
猛猿大佬思路
一切从下面这张图说起,这是对源码实现逻辑的抽离: 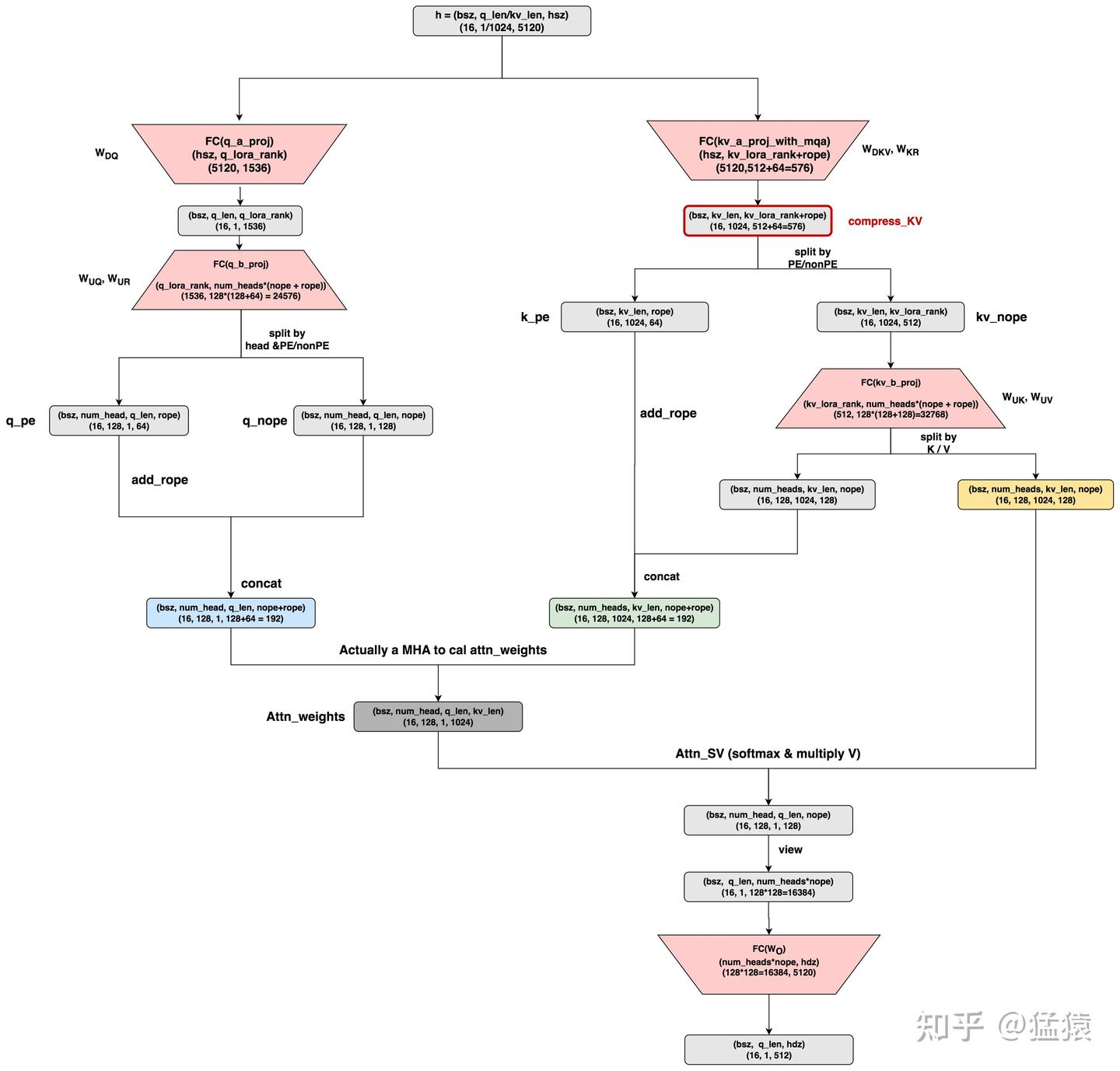
(图中的 kv_b_proj 维度标注错误,应该为(nope+v_head_dim),这里的 v_head_dim=nope)
从图中可以看到,此时 q_len 为 1,kv_len 为 1024,q_lora_rank 大小为 1536,而 kv_lora_rank 大小为 512,我们可以观察到左路和右路的计算流程不太一样,这是因为上面公式 (10) 中 q 和 k 的 rope 部分使用的不一样,q 使用的是压缩后的 c,而 k 使用的是原始 x, 因此在 x 为输入的时候 kv 部分就可以将 rope 部分算出来,而 q 部分需要将压缩后的 q 得到后才可以计算。q 是将 PE 和 NoPE split 开,而 kv 是将 NoPE 的 k 和 v split 开。
需要注意的是,在 nope 中,head_dim 为 128,而这大于 hsz // num_heads,猛猿大佬猜测这是为了提高模型的复杂度,因为推理的时候通过只保存压缩后的 kv 来减少了 kv cache 占用,那么训练的时候就可以稍微提高复杂度。
下面的代码是上图中的一些定义。结合苏神的推导过程相信可以理解 MLA。
class DeepseekV2Attention(nn.Module):
"""Multi-headed attention from 'Attention Is All You Need' paper"""
def __init__(self, config: DeepseekV2Config, layer_idx: Optional[int] = None):
super().__init__()
self.config = config
self.layer_idx = layer_idx
self.attention_dropout = config.attention_dropout
self.hidden_size = config.hidden_size
self.num_heads = config.num_attention_heads
self.head_dim = config.head_dim
self.max_position_embeddings = config.max_position_embeddings
self.rope_theta = config.rope_theta
self.q_lora_rank = config.q_lora_rank
self.qk_rope_head_dim = config.qk_rope_head_dim
self.kv_lora_rank = config.kv_lora_rank
self.v_head_dim = config.v_head_dim
self.qk_nope_head_dim = config.qk_nope_head_dim
self.qk_head_dim = config.qk_nope_head_dim + config.qk_rope_head_dim
self.num_key_value_groups = config.num_attention_heads // config.num_key_value_heads
self.is_causal = True
if self.q_lora_rank is None:
self.q_proj = nn.Linear(self.hidden_size, self.num_heads * self.qk_head_dim, bias=False)
else:
self.q_a_proj = nn.Linear(self.hidden_size, config.q_lora_rank, bias=config.attention_bias)
self.q_a_layernorm = DeepseekV2RMSNorm(config.q_lora_rank)
self.q_b_proj = nn.Linear(config.q_lora_rank, self.num_heads * self.qk_head_dim, bias=False)
self.kv_a_proj_with_mqa = nn.Linear(
self.hidden_size,
config.kv_lora_rank + config.qk_rope_head_dim,
bias=config.attention_bias,
)
self.kv_a_layernorm = DeepseekV2RMSNorm(config.kv_lora_rank)
self.kv_b_proj = nn.Linear(
config.kv_lora_rank,
self.num_heads * (self.qk_head_dim - self.qk_rope_head_dim + self.v_head_dim),
bias=False,
)
self.o_proj = nn.Linear(
self.num_heads * self.v_head_dim,
self.hidden_size,
bias=config.attention_bias,
)
self.scaling = self.qk_head_dim ** (-0.5)参考
缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA - 科学空间|Scientific Spaces