Lora微调
Low-Rank Adaption (LoRA),即“低秩适配”,实现了预训练模型的参数高效微调,且不会增加模型的推理延迟。 ## 内在维度 2020年,A. Aghajanyan等人研究了这一现象,发现预训练模型存在一个较低的”内在维度”,使用少量样本微调时,实际上是在更新低维空间中的参数。把预训练模型的全部参数看成一个D维参数向量,记为\(\Theta^\mathrm{(D)}\),模型的原始参数为\(\Theta_0^\mathrm{(D)}\),设\(\Theta^{(d)}\)是d维子空间中的一个向量,d<D,利用一个固定的D*d映射矩阵P 把d维空间中的向量映射到D维空间,\(\Theta^{(\mathrm{D})}\)可写为:
\[\mathrm{\theta^{(D)}=\theta_0^{(D)}+P\theta^{(d)}}\]
下图中,以D=3,d=2为例: 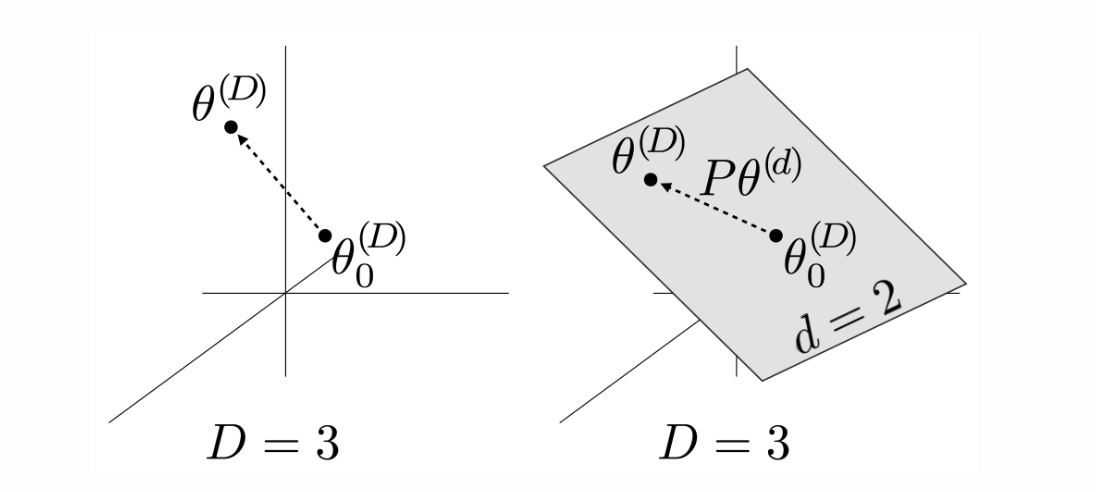
左图直接在3维空间中训练模型,直接优化原始模型参数\(\Theta_{0}^{(\mathrm{D})}\),把它更新为\(\Theta^{(\mathrm{D})}\)。右图冻结\(\Theta_{0}^{(\mathrm{D})}\),转而在2维空间中寻找一个\(\Theta^{(\mathrm{d})}\),再用矩阵P把\(\Theta^{(\mathrm{d})}\)映射到3维空间。如果用右图的方式可以把模型优化到良好的效果,例如,达到了全量参数微调效果的90%,则该模型的内在维度\(\mathrm{d}_{90}=2\)。
实验表明,仅训练200个参数,就可以使RoBERTa-large在MRPC数据集上的效果达到全量参数微调效果的90%。
## 低秩适配
预训练模型的权重矩阵通常具有满秩,这意味着权重矩阵的各个列向量之间线性无关,这样的矩阵没有冗余信息,是无法被压缩的。但是,“内在维度”现象表明,微调模型时只需更新少量参数,这启发我们微调时产生的权重增量矩阵\(\Delta\)W可能包含大量冗余参数,\(\Delta\)W很可能不是满秩的。对低秩矩阵做分解,可以利用较少的参数重建或近似原矩阵。这就是LoRA的核心思想。
设输入为x,微调时得到增量\(\Delta
W\),与原始权重\(\mathcal{W}_{0}\)相加得到更新后的权重,输出h=
( \(W_0\)+ \(\Delta\)W) x。根据矩阵的乘法分配律,有h=
\(W_0\)x+ \(\Delta\)Wx,这意味着微调时可以保持\(W_0\)不变,分别将\(W_0\)、\(\Delta\)W与x相乘,最后把两个乘积相加即可得到输出h。
设\(\mathcal{W}_0\in\mathbb{R}^{\mathrm{dxk}}\),\(\Delta \mathcal{W}
_{\mathrm{f} }\)的秩为r。\(\Delta
\mathcal{W}= \mathcal{B} \mathcal{A}\)是\(\Delta\mathcal{W}\)的一个满秩分解,其中
\(\mathcal{B} \in \mathbb{R} ^{\mathrm{dxr}},
\mathcal{A} \in \mathbb{R} ^{\mathrm{rxk}}, \mathcal{r} \ll \min (
\mathcal{d} , \mathcal{k}
)\)。训练时,分别用随机高斯和零矩阵初始化A和B,确保初始化时
BA是零矩阵,对模型效果没有影响。训练过程中冻结\(\mathcal{W}_0\),只更新矩阵B和A,共r(d+k)个参数,从而实
现“参数高效”微调。推理时,分别计算\(\mathbf{W_{\mathrm{n} }x}\)和
BAx并相加,得到输出h,如下图所示: 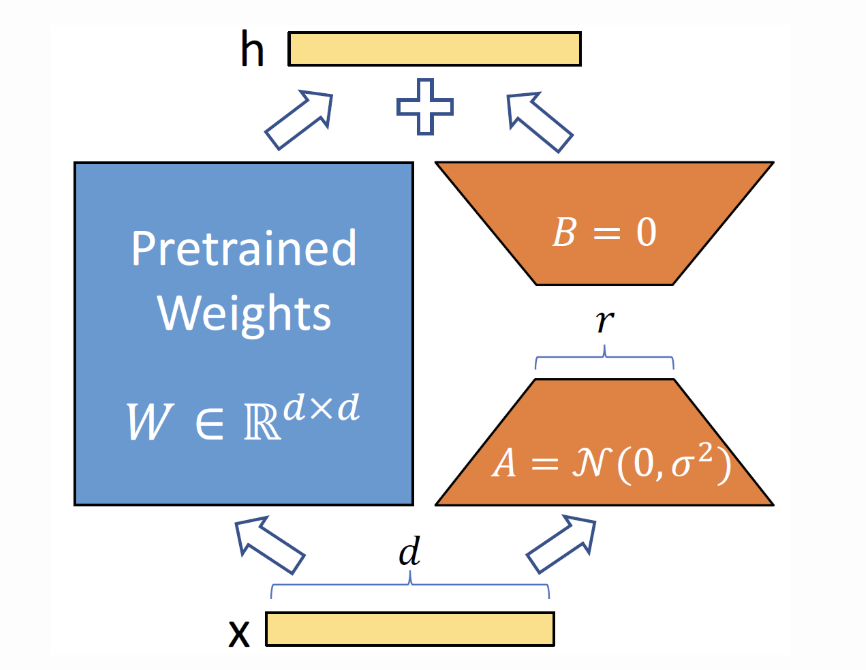
实际上,r是一个超参,训练时可任意设定,\(\Delta\)W真正的秩未必等于r。如果r恰好等于\(\Delta\)W的秩,甚至大于\(\Delta\)的秩(例如等于预训练权重矩阵\(W_{0}\)的秩),利用学到的B和A可以完全重建\(\Delta\)W,这时,LoRA的效果近似于全量微调。如果r小于\(\Delta\)W的秩,BA就是\(\Delta\)W的一个低秩近似,利用矩阵B和A可以恢复矩阵\(\Delta W\)中的部分信息。
还有一个超参数为lora_alpha:

降低了哪部分显存需求


代码
class LoraModel(torch.nn.Module):
"""
Creates Low Rank Adapter (Lora) model from a pretrained transformers model.
Args:
model ([`transformers.PreTrainedModel`]): The model to be adapted.
config ([`LoraConfig`]): The configuration of the Lora model.
Returns:
`torch.nn.Module`: The Lora model.
Example::
>>> from transformers import AutoModelForSeq2SeqLM, LoraConfig >>> from peft import LoraModel, LoraConfig >>>
config = LoraConfig(
peft_type="LORA", task_type="SEQ_2_SEQ_LM", r=8, lora_alpha=32, target_modules=["q", "v"],
lora_dropout=0.01, )
>>> model = AutoModelForSeq2SeqLM.from_pretrained("t5-base") >>> lora_model = LoraModel(config, model)
**Attributes**:
- **model** ([`transformers.PreTrainedModel`]) -- The model to be adapted.
- **peft_config** ([`LoraConfig`]): The configuration of the Lora model.
"""
def __init__(self, config, model):
super().__init__()
self.peft_config = config
self.model = model
self._find_and_replace()
mark_only_lora_as_trainable(self.model, self.peft_config.bias)
def _find_and_replace(self):
kwargs = {
"r": self.peft_config.r,
"lora_alpha": self.peft_config.lora_alpha,
"lora_dropout": self.peft_config.lora_dropout,
"fan_in_fan_out": self.peft_config.fan_in_fan_out,
"merge_weights": self.peft_config.merge_weights,
}
key_list = [key for key, _ in self.model.named_modules()]
for key in key_list:
if any(key.endswith(target_key) for target_key in self.peft_config.target_modules): # 对特定的层插入lora层
parent, target, target_name = self._get_submodules(key)
bias = target.bias is not None
if isinstance(target, torch.nn.Linear) and self.peft_config.enable_lora is None:
new_module = Linear(target.in_features, target.out_features, bias=bias, **kwargs)
elif self.peft_config.enable_lora is not None:
kwargs.update({"enable_lora": self.peft_config.enable_lora})
if isinstance(target, Conv1D):
in_features, out_features = target.weight.shape
else:
in_features, out_features = target.in_features, target.out_features
if kwargs["fan_in_fan_out"]:
warnings.warn(
"fan_in_fan_out is set to True but the target module is not a Conv1D. "
"Setting fan_in_fan_out to False."
)
kwargs["fan_in_fan_out"] = False
new_module = MergedLinear(in_features, out_features, bias=bias, **kwargs)
self._replace_module(parent, target_name, new_module, target)
def _get_submodules(self, key):
parent = self.model.get_submodule(".".join(key.split(".")[:-1]))
target_name = key.split(".")[-1]
target = self.model.get_submodule(key)
return parent, target, target_name
def _replace_module(self, parent_module, child_name, new_module, old_module):
setattr(parent_module, child_name, new_module)
new_module.weight = old_module.weight
if old_module.bias is not None:
new_module.bias = old_module.bias
def forward(self, *args, **kwargs):
return self.model(*args, **kwargs)
def __getattr__(self, name: str):
"""Forward missing attributes to the wrapped module."""
try:
return super().__getattr__(name) # defer to nn.Module's logic
except AttributeError:
return getattr(self.model, name)
@property
def modules_to_save(self):
return None
def get_peft_config_as_dict(self, inference: bool = False):
config = {k: v.value if isinstance(v, Enum) else v for k, v in asdict(self.peft_config).items()}
if inference:
config["inference_mode"] = True
return config插入lora层的核心代码如下:
class LoraLayer:
def __init__(
self,
r: int,
lora_alpha: int,
lora_dropout: float,
merge_weights: bool,
):
self.r = r
self.lora_alpha = lora_alpha
# Optional dropout
if lora_dropout > 0.0:
self.lora_dropout = nn.Dropout(p=lora_dropout)
else:
self.lora_dropout = lambda x: x
# Mark the weight as unmerged
self.merged = False
self.merge_weights = merge_weights
class Linear(nn.Linear, LoraLayer):
# Lora implemented in a dense layer
def __init__(
self,
in_features: int,
out_features: int,
r: int = 0,
lora_alpha: int = 1,
lora_dropout: float = 0.0,
fan_in_fan_out: bool = False, # Set this to True if the layer to replace stores weight like (fan_in, fan_out)
merge_weights: bool = True,
**kwargs,
):
nn.Linear.__init__(self, in_features, out_features, **kwargs)
LoraLayer.__init__(self, r=r, lora_alpha=lora_alpha, lora_dropout=lora_dropout, merge_weights=merge_weights)
self.fan_in_fan_out = fan_in_fan_out
# Actual trainable parameters
if r > 0:
self.lora_A = nn.Linear(in_features, r, bias=False)
self.lora_B = nn.Linear(r, out_features, bias=False)
self.scaling = self.lora_alpha / self.r
# Freezing the pre-trained weight matrix
self.weight.requires_grad = False
self.reset_parameters()
if fan_in_fan_out:
self.weight.data = self.weight.data.T
def reset_parameters(self):
nn.Linear.reset_parameters(self)
if hasattr(self, "lora_A"):
# initialize A the same way as the default for nn.Linear and B to zero
nn.init.kaiming_uniform_(self.lora_A.weight, a=math.sqrt(5))
nn.init.zeros_(self.lora_B.weight)
def train(self, mode: bool = True):
nn.Linear.train(self, mode)
self.lora_A.train(mode)
self.lora_B.train(mode)
if self.merge_weights and self.merged:
# Make sure that the weights are not merged
if self.r > 0:
self.weight.data -= (
transpose(self.lora_B.weight @ self.lora_A.weight, self.fan_in_fan_out) * self.scaling
)
self.merged = False
def eval(self):
nn.Linear.eval(self)
self.lora_A.eval()
self.lora_B.eval()
if self.merge_weights and not self.merged:
# Merge the weights and mark it
if self.r > 0:
self.weight.data += (
transpose(self.lora_B.weight @ self.lora_A.weight, self.fan_in_fan_out) * self.scaling
)
self.merged = True
def forward(self, x: torch.Tensor):
if self.r > 0 and not self.merged:
result = F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)
if self.r > 0:
result += self.lora_B(self.lora_A(self.lora_dropout(x))) * self.scaling
return result
else:
return F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)参考
https://snailcoder.github.io/2023/08/06/parameter-efficient-llm-fine-tuning-lora.html