Layer Norm
pre-norm
Pre-norm:\(X_t+1=X_{t}+F_{t}(Norm(X_{t}))\)
\(先来看Pre-norm^{+},递归展开:\) \[X_{t+1}=X_t+F_t(Norm(X_t))\] \(=X_{0}+F_{1}(Norm(X_{1}))+\ldots+F_{t-1}(Norm(X_{t-1}))+F_{t}(Norm(X_{t}))\) 其中,展开\(^{+}\)后的每一项( \(F_{1}( Norm( X_{1}) ) , \ldots\), \(F_{t- 1}( Norm( X_{t- 1}) )\), \(F_{t}( Norm( X_{t}) )\))之间都是同一量级的, 所以\(F_1(Norm(X_1))+\ldots F_{t-1}(Norm(X_{t-1}))+F_t(Norm(X_t))\)和 \(F_1(Norm(X_1))+\ldots F_{t-1}(Norm(X_{t-1}))\)之间的区别就像t和t-1的区别一样,我们可以将 其记为\(X_t+ 1= \mathscr{O} ( t+ 1)\) . 这种特性就导致当t足够大的时候,\(X_{t+1}\)和\(X_t\)之间区别可以忽略不计(直觉上),那么就有:
\[F_t(X_t)+F_{t+1}(X_{t+1})\approx F_t(X_t)+F_{t+1}(X_t)=(F_t\bigoplus F_{t+1})(X_t)\] 这就是所谓的增加宽度,而没有增加深度。从而导致pre-norm的精度不高。 ## post-norm
Post-norm:\(X_{t+1}=Norm(X_{t}+F_{t}(x_{t}))\) 本来layernorm是为了缓解梯度消失,但是在post-norm这里却成为了梯度消失的罪魁祸首。也导致了收敛较难、需要大量调参。
\[X_{t+1}=Norm(X_t+F_t(X_t))=\frac{X_t+F_t(X_t)}{\sqrt{2}}\] \[=\frac{X_0}{\sqrt{2}^{t+1}}+\frac{F_0(X_0)}{\sqrt{2}^{t+1}}+\ldots+\frac{F_{t-1}(X_{t-1})}{\sqrt{2}^2}+\frac{F_t(X_t)}{\sqrt{2}}\:(\] 这个结构跟pre-norm比起来充分考虑了所有分支 (残差\(^{+})\) 的输出,做到了真正增加深度,自然精度会相对好一些。
不过它也有它很显然的问题,当t足够大、也就是叠加的attention层足够多以后,底层那些分支(残差)的影响力被衰减掉了,残差有利于解决梯度消失,但是在Post Norm中,残差这条通道被严重削弱了,越靠近输入,削弱得越严重,残差“名存实亡”,那么势必会有梯度消失的问题,这也就是文章开头所说的postnorm难收敛、参数难调的原因。本来我们做Norm也是为了处理梯度消失,但从分析看来,transformer结构中的layernorm\(^{+}\)并没有完全实现它的作用。那这就意味着transformer原始结构的失败吗?并不是的,因为这种梯度消失的问题在整个结构上来看(配合上adam系优化器和学习率warmup,warmup对于post-norm极为重要) 是并不明显的。
离输入层的残差影响力弱这一特性,也有它的用武之地,比如在finetune的时候,我们就希望不要过多调整靠近输入层的参数、以免破坏预训练的效果。
warmup的重要性
Post-LN Transformer在训练的初始阶段,输出层附近的期望梯度非常大,所以,如果没有warm-up,模型优化过程就会炸裂,非常不稳定。
模型对越靠后的层越敏感,也就是越靠后的层学习得越快,然后后面的层是以前面的层的输出为输入的,前面的层根本就没学好,所以后面的层虽然学得快,但却是建立在糟糕的输入基础上的。
很快地,后面的层以糟糕的输入为基础到达了一个糟糕的局部最优点,此时它的学习开始放缓(因为已经到达了它认为的最优点附近),同时反向传播给前面层的梯度信号进一步变弱,这就导致了前面的层的梯度变得不准。但
Adam
的更新量是常数量级的,梯度不准,但更新量依然是常数量级,意味着可能就是一个常数量级的随机噪声了,于是学习方向开始不合理,前面的输出开始崩盘,导致后面的层也一并崩盘。
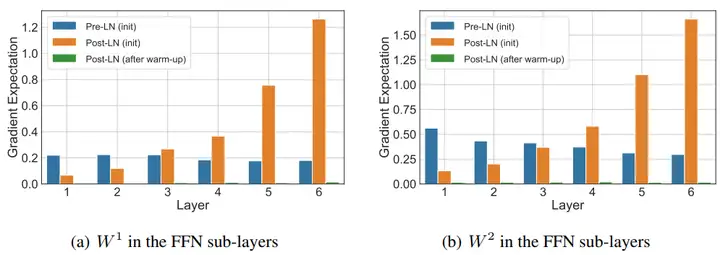
从上图中就可以看出来,post-ln在开始阶段层数越高梯度越大,此时需要小学习率,而当warmup完后,梯度变得很小(绿色部分)。此时可以使用大学习率。
很好的总结回答
为什么 layer norm 会使方差累积和训练不稳定
让我们来追踪一下 Pre-Norm 结构中数据 x 的方差变化:
假设我们有一个输入 \(x_l\),它进入第 l 个残差块。
在 Sublayer 分支中,我们首先对 \(x_l\) 进行 LayerNorm。\(LayerNorm(x_l)\) 的输出具有严格的均值为0,方差为1 的特性。
这个归一化后的结果被送入 Sublayer(例如一个全连接网络或注意力层)。经过计算后,输出 \(Sublayer(LayerNorm(x_l))\) 的方差通常不再是1,我们假设它的方差是 Var(S)。
最后,这个 Sublayer 的输出被加回到原始的、未归一化的输入 \(x_l\) 上,得到该层的最终输出 \(x_{l+1}\):
\(x_{l+1} = x_l + Sublayer(LayerNorm(x_l))\)
- 现在我们来计算 x_{l+1} 的方差。在统计学中,如果两个变量(这里是 x_l 和 Sublayer(…))大致不相关,那么它们和的方差约等于它们各自方差的和:
\(Var(x_{l+1}) ≈ Var(x_l) + Var(Sublayer(LayerNorm(x_l)))\)
\(Var(x_{l+1}) ≈ Var(x_l) + Var(S)\)
这个公式清晰地揭示了问题所在:每一层的输出方差 \(Var(x_{l+1})\) 都是在前一层方差 \(Var(x_l)\) 的基础上,又增加了一个正数 \(Var(S)\)。
因此,随着网络层数的加深(l 变大),\(x_l\) 的方差会像滚雪球一样不断累加,导致主干分支上的数值越来越大。这可能会在训练后期导致数值不稳定。
对比 Post-Norm:
在 Post-Norm 中,\(x_{l+1} = LayerNorm(...)\)。无论括号里的值 \((x_l + Sublayer(x_l))\) 方差多大,经过最后的 LayerNorm 后,输出 \(x_{l+1}\) 的方差都会被强制重置为 1。因此,Post-Norm 不存在方差累积增大的问题,但它也因此带来了训练初期不稳定、需要特殊学习率热身(warm-up)等其他问题。
Prenorm公式还意味着,流经网络主干道(即 x_0, x_1, x_2, …)的信号,其“能量”(方差)在一层层地单调递增。经过几十上百层网络后,x_l 的数值大小(即激活值)就会变得非常巨大。这就是“巨量激活值”(massive activations)的直接来源。
现在我们有了“巨量激活值”,为什么这会导致训练不稳定呢?这与反向传播和参数更新的机制有关。
产生巨量梯度 (Massive Gradients):在反向传播计算梯度时,很多层的梯度都与其前向传播时的激活值成正比。举一个简化的例子,对于一个权重 W,它的梯度 ∂L/∂W 通常会包含一个与输入激活值 x 相乘的项。如果 x 是一个“巨量激活值”,那么计算出的梯度 ∂L/∂W 也会是一个“巨量梯度”。
破坏优化器状态 (Corrupting Optimizer State):像 Adam 这样的现代优化器,会维护梯度的历史信息(如一阶矩和二阶矩的移动平均)。一个突然出现的巨量梯度会严重“污染”这些历史平均值,使得优化器对学习率的自适应调整产生剧烈摆动。
灾难性的参数更新 (Catastrophic Weight Updates):优化器使用这个被污染的巨量梯度来更新模型权重:W_new = W_old - lr * massive_gradient。这个更新步长会异常巨大,相当于在复杂的损失地形上进行了一次“盲目的、大跨步的跳跃”。
损失尖峰 (Loss Spikes):这次“大跳跃”很可能会让模型参数跳到一个非常糟糕的位置,导致模型的预测性能急剧下降,训练损失(Loss)瞬间飙升,在训练曲线上就形成了一个“尖峰”。
训练发散 (Training Divergence):如果这个“尖峰”过于极端,参数更新可能会导致数值溢出(inf)或非法操作(NaN),整个训练过程就此崩溃,即“训练发散”。
Adam如何缓解梯度消失
其实。最关键的原因是,在当前的各种自适应优化技术“下,我们已经不大担心梯度消失问题了。这是因为,当前 NLP 中主流的优化器是 Adam 及其变种。对于 Adam 来说,由于包含了动量和二阶矩校正,所以近似来看,它的更新量大致上为 \[\Delta\theta=-\eta\frac{\mathbb{E}_{t}[g_{t}]}{\sqrt{\mathbb{E}_{t}[g_{t}^{2}]}}\] 可以看到,分子分母是都是同量纲的,因此分式结果其实就是 (1)的量级,而更新量就是 (n)量级。也就是说,理论上只要梯度的绝对值大于随机误差,那么对应的参数都会有常数量级的更新量(意思就是参数的更新量与梯度的关系不是很大,因此受梯度消失影响较小);这跟 SGD 不一样,SGD 的更新量是正比于梯度的,只要梯度小,更新量也会很小,如果梯度 过小,那么参数几乎会没被更新。 所以,Post Norm 的残差虽然被严重削弱,但是在 base、large 级别的模型中,它还不至于削弱到小于随机误差的地步,因此配合 Adam 等优化器,它还是可以得到有效更新的,也就有可能成功训练了。当然,只是有可能,事实上越深的 Post Norm 模型确实越难训练,比如要仔细调节学习率和 Warmup 等
Deep-norm
\(最后再提一下DeepNet中结合Post-LN^+的良好性能以及Pre-LN的训练稳定性做出的改良\)。 \[X_{t+1}=Norm(\alpha X_t+F_t(X_t))\text{(6)}\] \(它在add norm之前给输入乘了一个up-scale^+的常数系数 α>1\)。
现在 (5) 的展开为: \[X_{t+1}=\frac{\alpha^{t+1}X_{0}}{\sqrt{2}^{t+1}}+\frac{\alpha^{t}F_{0}(X_{0})}{\sqrt{2}^{t+1}}+\ldots+\frac{\alpha F_{t-1}(X_{t-1})}{\sqrt{2}^{2}}+\frac{F_{t}(X_{t})}{\sqrt{2}}\] 因为\(\alpha>1\) ,所以它能够在保留post-norm真正增加了深度这优点的同时,一定程度避免了梯度消失。(本质还是post-norm)
参考
Transformer梳理(一):Post-Norm VS Pre-Norm - 知乎 (zhihu.com) 模型优化漫谈:BERT的初始标准差为什么是0.02? - 科学空间|Scientific Spaces (kexue.fm) 为什么Pre Norm的效果不如Post Norm? - 科学空间|Scientific Spaces (kexue.fm) 香侬读 | Transformer中warm-up和LayerNorm的重要性探究 - 知乎 (zhihu.com) Bert/Transformer 被忽视的细节(或许可以用来做面试题) - 知乎 (zhihu.com)