KV cache
KV cache
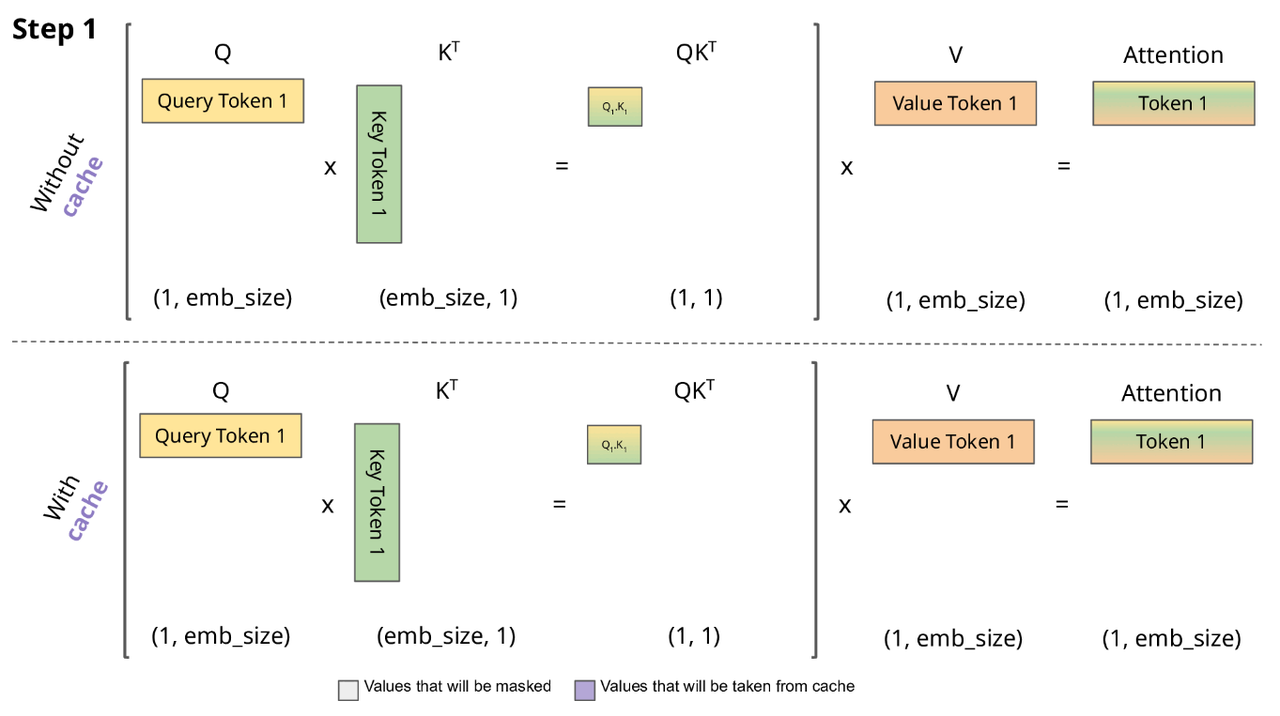
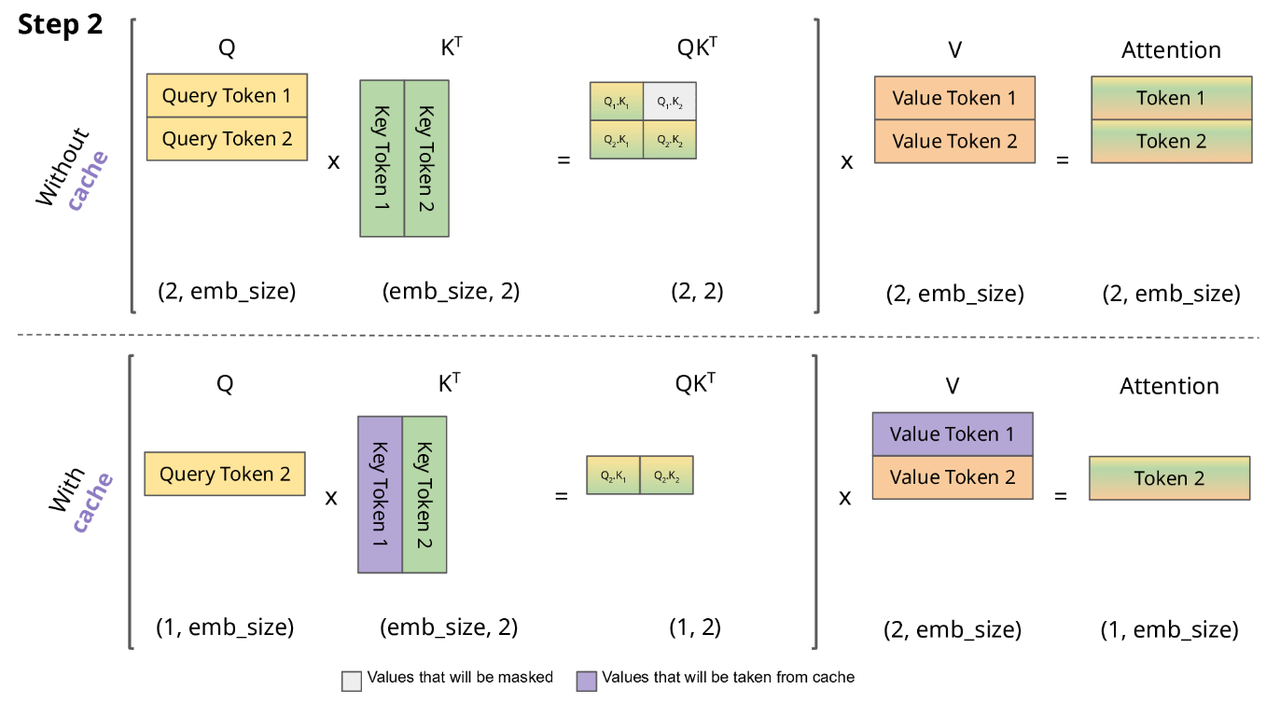
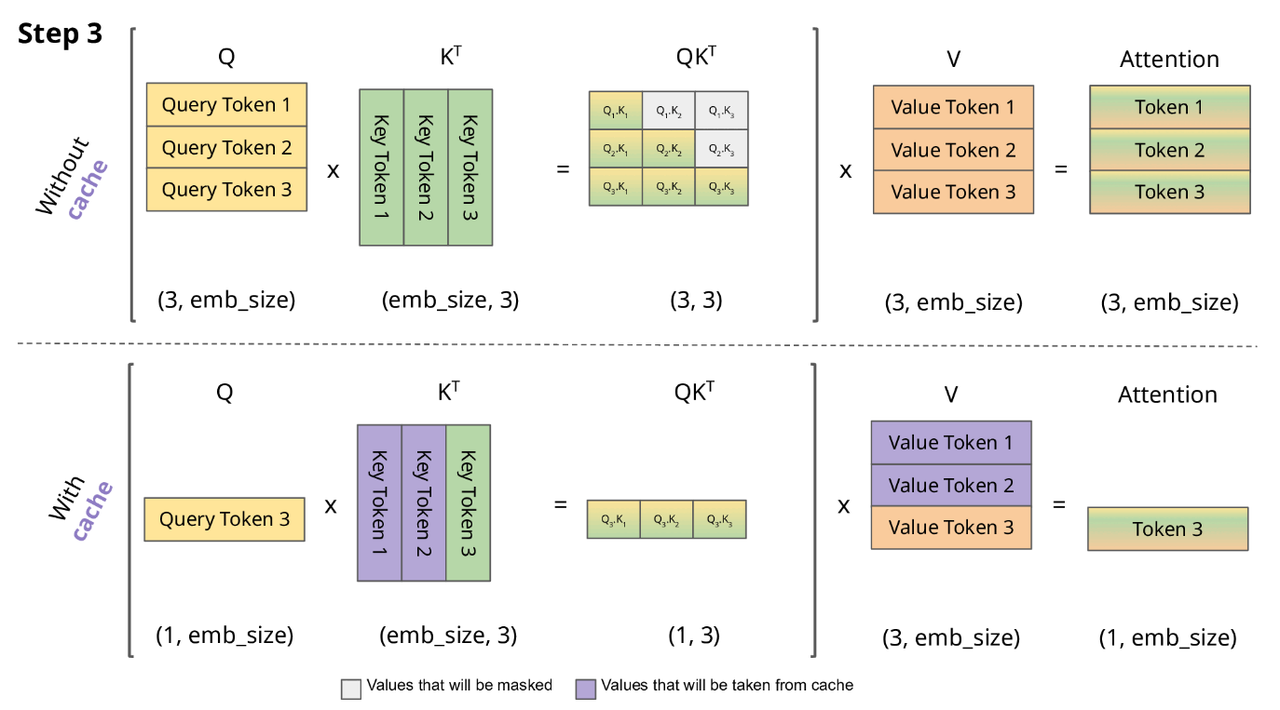
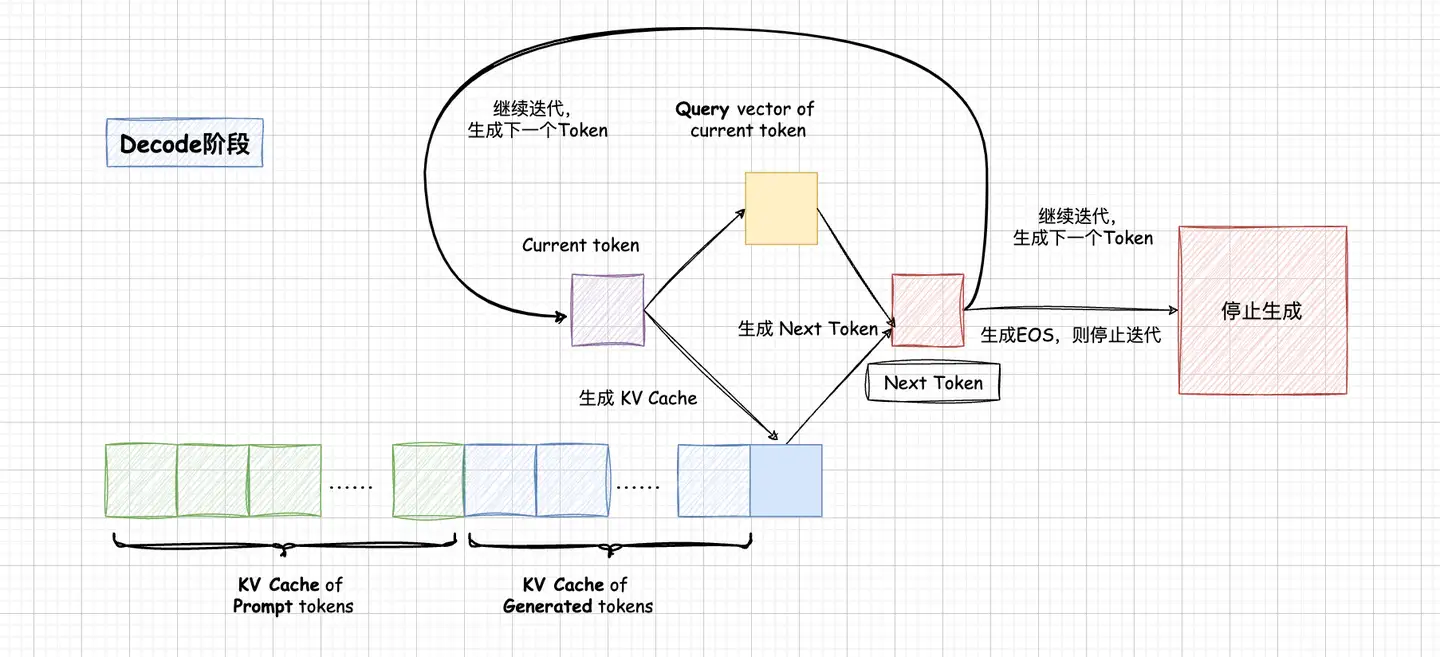
LLM推理过程分为Prefill和Decode两个阶段,其中Prefill阶段会对Prompt中所有的token做并行计算,得到Prompt中所有Tokens的KV Cache以及计算得到首Token。Prompt阶段Token计算得到的KV Cache会保存下来,留给Decode阶段复用,Decode阶段是一个自回归过程,每decode一个新的Token,都需要用到所有之前计算得到的KV Cache来计算当前query token的Attention。因此,当输出长度越来越大或者context很长时,KV Cache将会占用大量的显存。如何优化KV Cache的显存占用,一直都是LLM推理的核心主题之一。
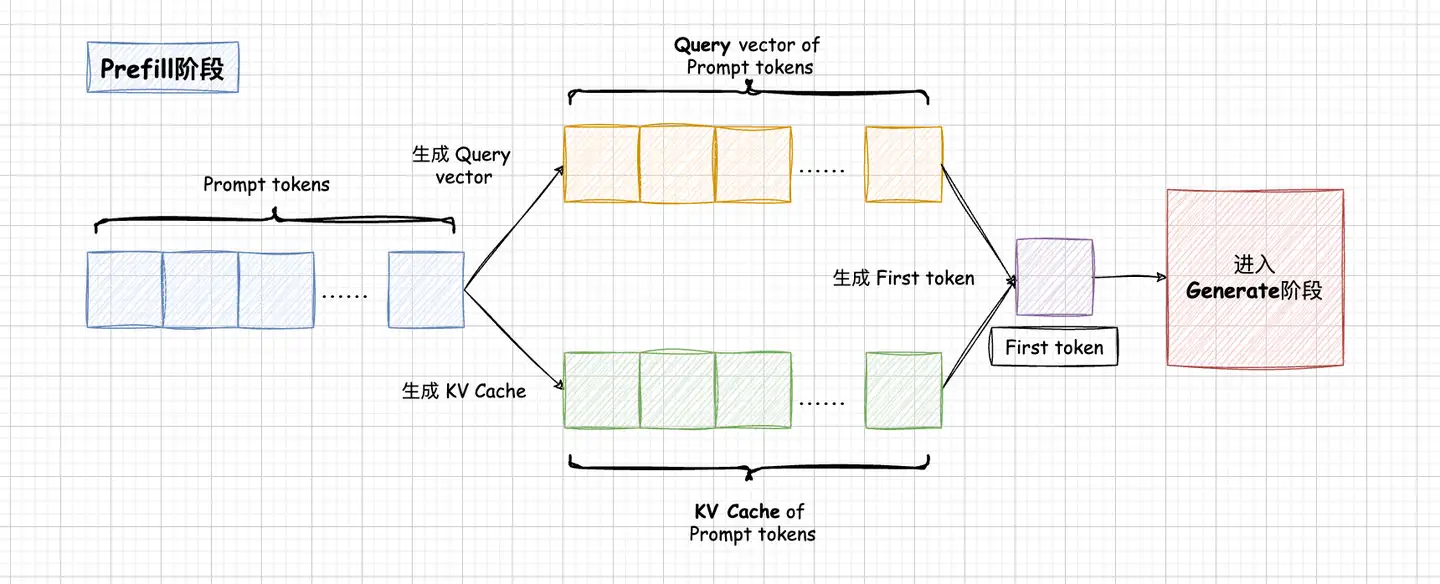
之前一直疑惑kv cache既然每次只输入生成token就可以,那么位置信息该怎么注入呢?翻了翻llama的源码,找到了答案:
def forward(self, tokens: torch.Tensor, start_pos: int):
"""
Perform a forward pass through the Transformer model.
Args:
tokens (torch.Tensor): Input token indices.
start_pos (int): Starting position for attention caching.
Returns:
torch.Tensor: Output logits after applying the Transformer model.
"""
_bsz, seqlen = tokens.shape
h = self.tok_embeddings(tokens)
self.freqs_cis = self.freqs_cis.to(h.device)
freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]
mask = None
if seqlen > 1:
mask = torch.full(
(seqlen, seqlen), float("-inf"), device=tokens.device
)
mask = torch.triu(mask, diagonal=1)
# When performing key-value caching, we compute the attention scores
# only for the new sequence. Thus, the matrix of scores is of size
# (seqlen, cache_len + seqlen), and the only masked entries are (i, j) for
# j > cache_len + i, since row i corresponds to token cache_len + i.
mask = torch.hstack([
torch.zeros((seqlen, start_pos), device=tokens.device),
mask
]).type_as(h)
for layer in self.layers:
h = layer(h, start_pos, freqs_cis, mask)
h = self.norm(h)
output = self.output(h).float()
return output注意freqs_cis = self.freqs_cis[start_pos : start_pos + seqlen]这一行,即是实现了rope相对位置编码的kv
cache的核心。
kv cache代码
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:
"""torch.repeat_interleave(x, dim=2, repeats=n_rep)"""
bs, slen, n_kv_heads, head_dim = x.shape
if n_rep == 1:
return x
return (
x[:, :, :, None, :]
.expand(bs, slen, n_kv_heads, n_rep, head_dim)
.reshape(bs, slen, n_kv_heads * n_rep, head_dim)
)
class Attention(nn.Module):
"""Multi-head attention module."""
def __init__(self, args: ModelArgs):
"""
Initialize the Attention module.
Args:
args (ModelArgs): Model configuration parameters.
Attributes:
n_kv_heads (int): Number of key and value heads.
n_local_heads (int): Number of local query heads.
n_local_kv_heads (int): Number of local key and value heads.
n_rep (int): Number of repetitions for local heads.
head_dim (int): Dimension size of each attention head.
wq (ColumnParallelLinear): Linear transformation for queries.
wk (ColumnParallelLinear): Linear transformation for keys.
wv (ColumnParallelLinear): Linear transformation for values.
wo (RowParallelLinear): Linear transformation for output.
cache_k (torch.Tensor): Cached keys for attention.
cache_v (torch.Tensor): Cached values for attention.
"""
super().__init__()
self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads
model_parallel_size = fs_init.get_model_parallel_world_size()
self.n_local_heads = args.n_heads // model_parallel_size
self.n_local_kv_heads = self.n_kv_heads // model_parallel_size
self.n_rep = self.n_local_heads // self.n_local_kv_heads
self.head_dim = args.dim // args.n_heads
self.wq = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wk = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wv = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wo = RowParallelLinear(
args.n_heads * self.head_dim,
args.dim,
bias=False,
input_is_parallel=True,
init_method=lambda x: x,
)
# kv_cache是缓存键值对,在训练过程中,我们只保存最近n个键值对
self.cache_k = torch.zeros(
(
args.max_batch_size,
args.max_seq_len,
self.n_local_kv_heads,
self.head_dim,
)
).cuda()
self.cache_v = torch.zeros(
(
args.max_batch_size,
args.max_seq_len,
self.n_local_kv_heads,
self.head_dim,
)
).cuda()
def forward(
self,
x: torch.Tensor,
start_pos: int,
freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
):
"""
Forward pass of the attention module.
Args:
x (torch.Tensor): Input tensor.
start_pos (int): Starting position for caching.
freqs_cis (torch.Tensor): Precomputed frequency tensor.
mask (torch.Tensor, optional): Attention mask tensor.
Returns:
torch.Tensor: Output tensor after attention.
"""
# 假设当前x为(1, 1, dim),也就是上一个预测的token
# self-attention的输入,标准的(bs, seqlen, hidden_dim)
bsz, seqlen, _ = x.shape
# 计算当前token的qkv
# q k v分别进行映射,注意这里key, value也需要先由输入进行映射再和kv_cache里面的key, value进行拼接
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
# 对当前输入的query和key进行RoPE,注意kv_cache里面的key已经做过了RoPE
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
# 缓存当前token的kv
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
self.cache_k[:bsz, start_pos: start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos: start_pos + seqlen] = xv
# 取出前seqlen个token的kv缓存
# 取出全部缓存的key和value(包括之前在cache里面的和本次输入的),作为最终的key和value
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
# 将kv重复填充,使kv和q的头数个数相同
# repeat k/v heads if n_kv_heads < n_heads,对齐头的数量
keys = repeat_kv(keys, self.n_rep) # (bs, cache_len + seqlen, n_local_heads, head_dim)
values = repeat_kv(values, self.n_rep) # (bs, cache_len + seqlen, n_local_heads, head_dim)
# 计算当前token的attention score,,注意mask需要加上,另外维度要对应上
xq = xq.transpose(1, 2) # (bs, n_local_heads, seqlen, head_dim)
keys = keys.transpose(1, 2) # (bs, n_local_heads, cache_len + seqlen, head_dim)
values = values.transpose(1, 2) # (bs, n_local_heads, cache_len + seqlen, head_dim)
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
scores = scores + mask # (bs, n_local_heads, seqlen, cache_len + seqlen)
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values) # (bs, n_local_heads, seqlen, head_dim)
output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)
return self.wo(output)prefill和decode分离
在传统的 LLM 推理框架中,Prefill 和 Decode 阶段通常由同一块 GPU 执行。推理引擎的调度器会根据显存使用情况及请求队列状态,在 Prefill 和 Decode 之间切换,完成整个推理过程。
而在 Prefill-Decode 分离式架构(以下简称 PD
分离式架构)中,这两个阶段被拆分到不同的 GPU
实例上独立运行。如下图所示,这是 DistServe 提供的一张架构图: 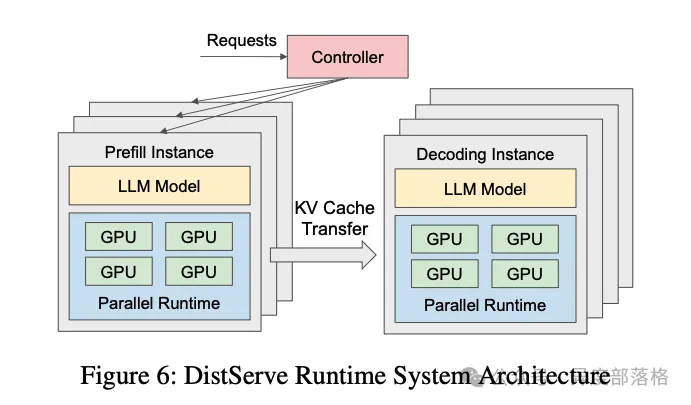 在大模型推理中,常用以下两项指标评估性能:
在大模型推理中,常用以下两项指标评估性能:
- TTFT(Time-To-First-Token):首 token 的生成时间,主要衡量 Prefill 阶段性能。
- TPOT(Time-Per-Output-Token):生成每个 token 的时间,主要衡量 Decode 阶段性能。
当 Prefill 和 Decode 在同一块 GPU 上运行时,由于两阶段的计算特性差异(Prefill 是计算密集型,而 Decode 是存储密集型),资源争抢会导致 TTFT 和 TPOT 之间的权衡。例如:
- 若优先处理 Prefill 阶段以降低 TTFT,Decode 阶段的性能(TPOT)可能下降。
- 若尽量提升 TPOT,则会增加 Prefill 请求的等待时间,导致 TTFT 上升。
PD 分离式架构的提出正是为了打破这一矛盾。通过将 Prefill 和 Decode 分离运行,可以针对不同阶段的特性独立优化资源分配,从而在降低首 token 延迟的同时提高整体吞吐量。
在 PD 分离架构中,Prefill 和 Decode 阶段的资源需求不同,分别体现为:
- Prefill 阶段:计算密集型(compute-bound)。在流量较大或用户提示长度较长时,Prefill 的计算压力更大。完成 KV Cache 的生成后,Prefill 阶段本身无需继续保留这些缓存。
- Decode 阶段:存储密集型(memory-bound)。由于逐 token 生成的特性,Decode 阶段需频繁访问 KV Cache,因此需要尽可能多地保留缓存数据以保障推理效率。
Batching 策略对两阶段的性能影响显著,但趋势相反:
- Prefill 阶段:吞吐量随 batch size 增加逐渐趋于平稳。这是因为 Prefill 的计算受限特性(compute-bound),当 batch 中的总 token 数超过某个阈值时,计算资源成为瓶颈。
- Decode 阶段:吞吐量随 batch size 增加显著提升。由于 Decode 阶段的存储受限特性(memory-bound),增大 batch size 可提高计算效率,从而显著增加吞吐量。
Chunked prefills
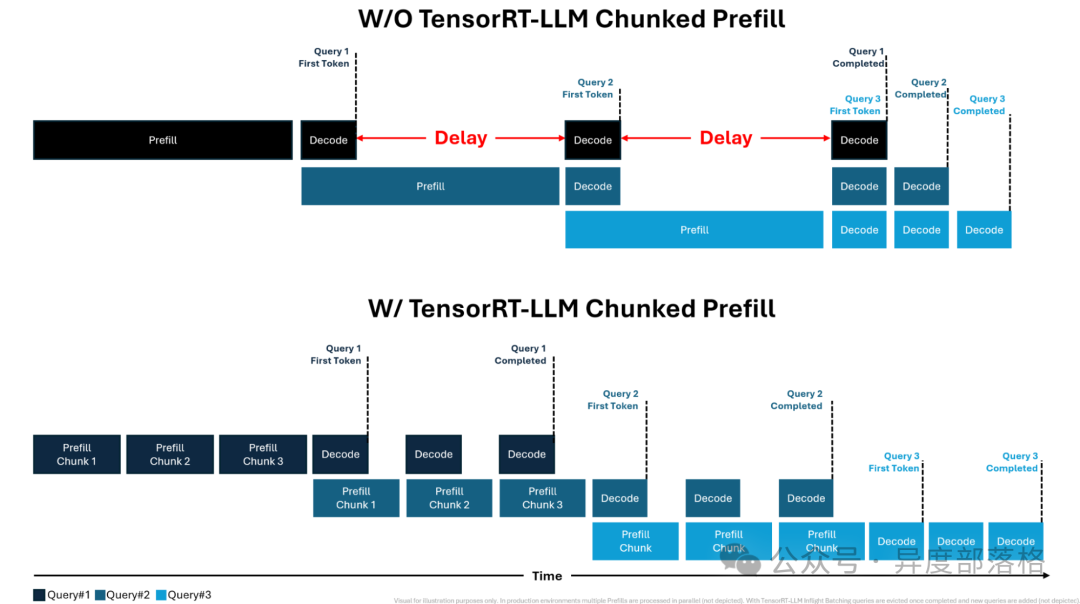
常见问题
128k token输入需要多少显存存kv cache?

超参数如上,如果我们采用int8精度,也就是每个参数占据一个字节,每个token占据的kv cache大小就是
2 * K * H * L = 2 (k 和 v) * 8 (n kv heads) * 128 (d_qkv) * 80 (n layers) * 1 (byte)= 160kB
(这里的 2 是因为每个 token 需要存储k和v)
那么128k的kv cache就是:
162e3 * 128 * 1024 = 21.2GB 需要注意的是 llama 3 使用的是 gqa,所以 N 为 64,K 为 8.
套公式就是 (使用 bf 16 即 2 bytes):
\[ b(s+n)h*l*2*2 \]
其中 b 为 batch_size,s 为输入序列长度,n 为输出序列长度,h 为 k 或者 v 的总维度,不同的 attention 改变的是这个东西来降低显存。
参考
LLM—llama2结构和源码解读 - 知乎 (zhihu.com) # LLM推理优化 - Chunked prefills # 图解大模型计算加速系列:分离式推理架构1,从DistServe谈起