K2
预训练
Muon-clip
详见Muon
通过裁剪权重解决Max-Logit问题,实现稳定训练。
数据增强
通过改写句子来提高token效率,避免重复使用token造成的过拟合,改写方法如下:
- 多样化风格和视角的提示词:为在保持事实完整性的同时增强语言多样性,研究团队应用了一系列精心构建的提示词。这些提示词引导大语言模型从不同风格和视角生成原始文本的忠实改写版本。
- 分块式自回归生成:为保持全局连贯性并避免长文档信息丢失,研究团队采用了基于分块的自回归重写策略。文本被划分为若干段落,分别进行改写,然后重新组合形成完整文章。这种方法缓解了大语言模型通常存在的隐式输出长度限制问题,如图4所示。
- 保真度验证:为确保原始内容与改写内容的一致性,研究团队执行保真度检查,比较每个改写段落与原文的语义对齐程度。这作为训练前的初步质量控制环节。
模型架构
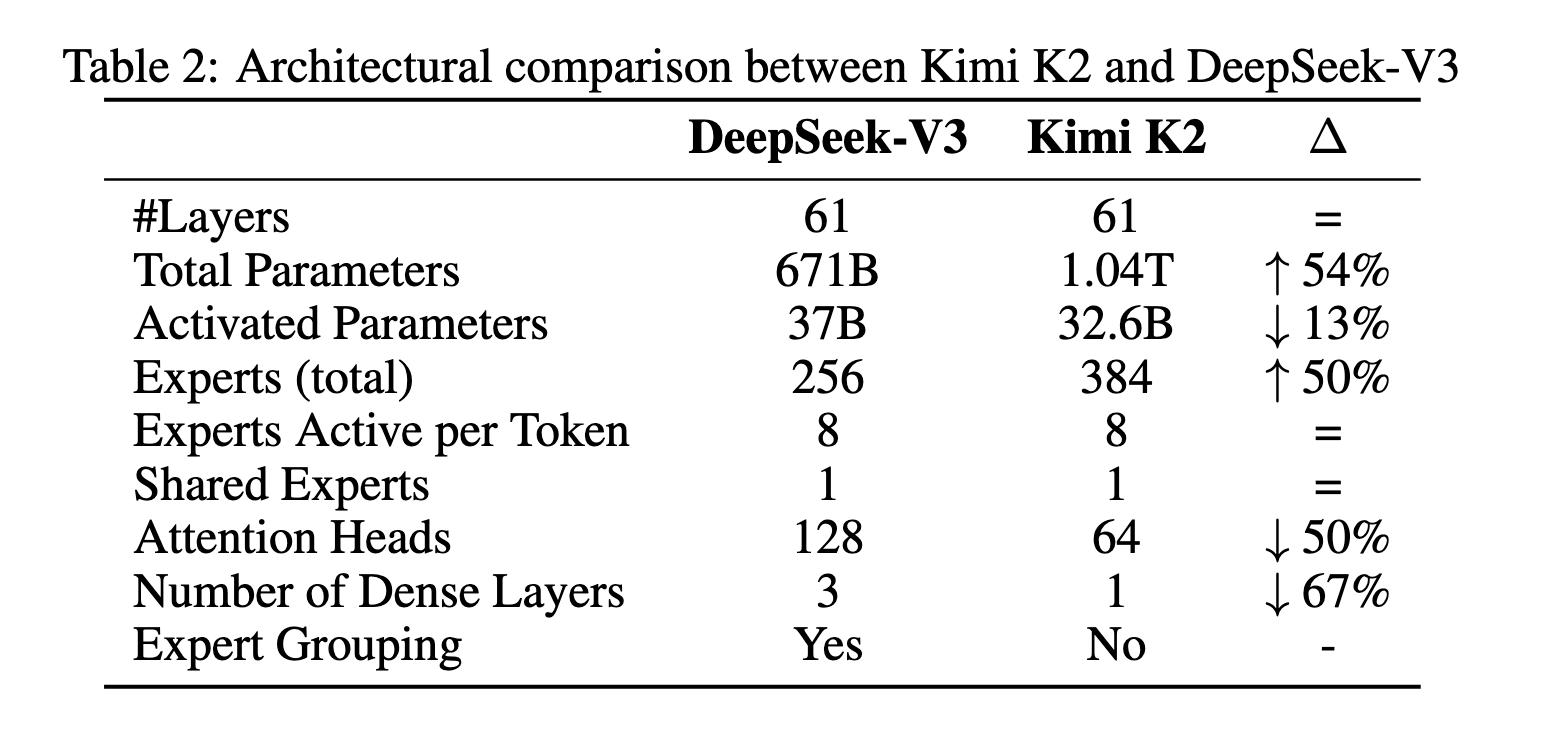
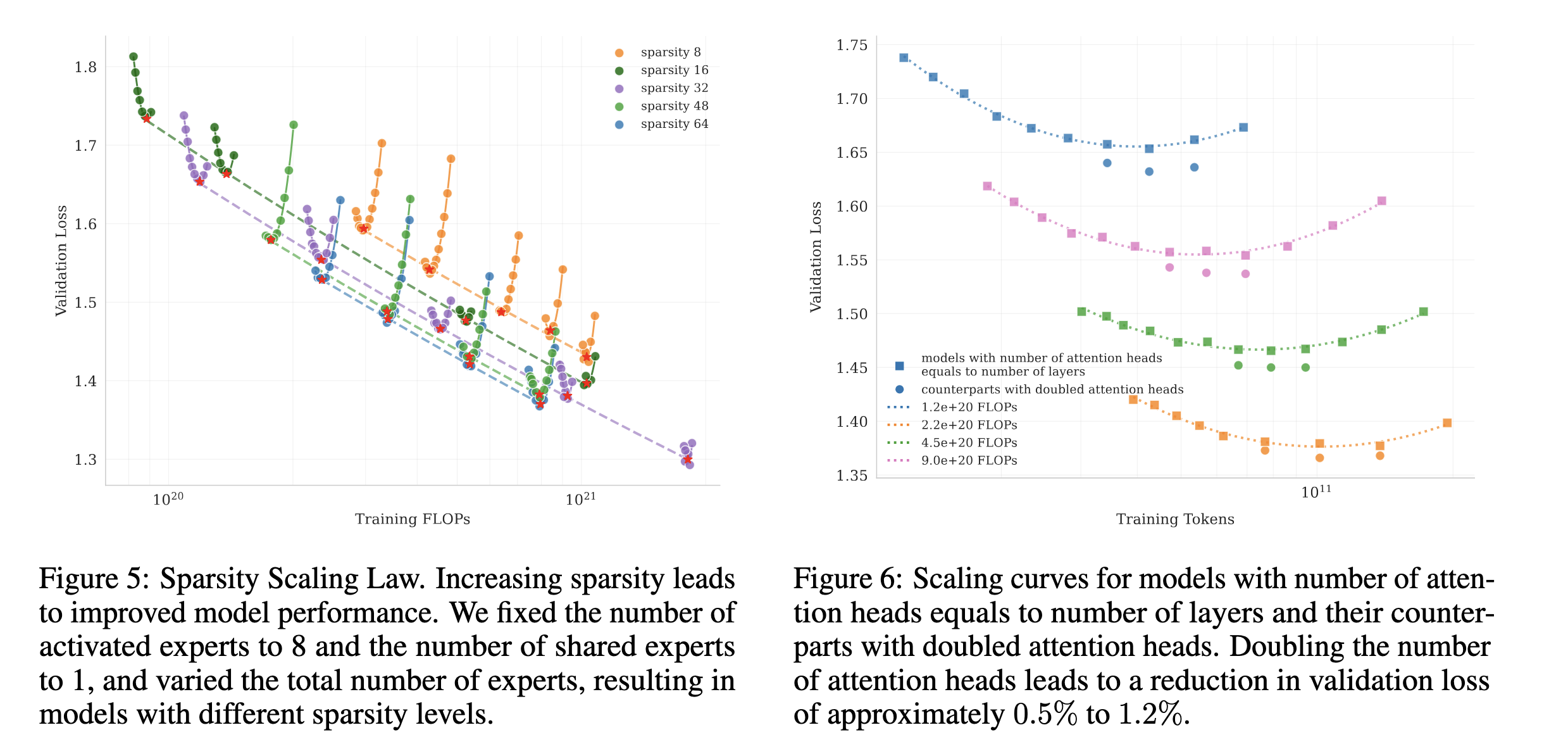
k2通过实验发现了稀疏性扩展法则(稀疏性定义为专家总数与激活专家数量的比值)。 以及注意力头的数量多只能提升少量性能,但带来了大量的计算量。
infra
分为并行化策略和激活值压缩
并行化策略:EP通信与交错1F1B的重叠与更小的EP规模
激活值压缩:
选择性重计算 对计算成本低但内存占用高的操作进行重计算,包括LayerNorm、SwiGLU和MLA上投影。此外,训练过程中还对MoE下投影进行重计算以进一步降低激活值内存需求。虽然这种重计算是可选的,但它能够维持充足的GPU内存,防止早期训练阶段因专家负载不均衡导致的系统崩溃。
不敏感激活值的FP8存储 将MoE上投影和SwiGLU的输入压缩为1×128数据块中的FP8-E4M3格式,配合FP32缩放因子。小规模实验表明这种压缩不会导致可测量的损失增加。由于初步研究中观察到潜在的性能下降风险,研究团队未在计算过程中采用FP8格式。
激活值CPU卸载 将所有剩余激活值卸载至CPU内存。数据传输引擎负责流式卸载和加载,与计算和通信核心实现重叠处理。在1F1B阶段,系统在预取下一个微批次的反向激活值的同时卸载前一个微批次的前向激活值。
Post-training
工具能力增强
合成了大量工具来进行微调。 - 工具规范生成:首先从现实世界工具和LLM合成工具中构建大型工具规范库 - 智能体和任务生成:针对从工具库中采样的每个工具集,生成使用该工具集的智能体和相应任务 - 轨迹生成:为每个智能体和任务生成智能体通过工具调用完成任务的轨迹
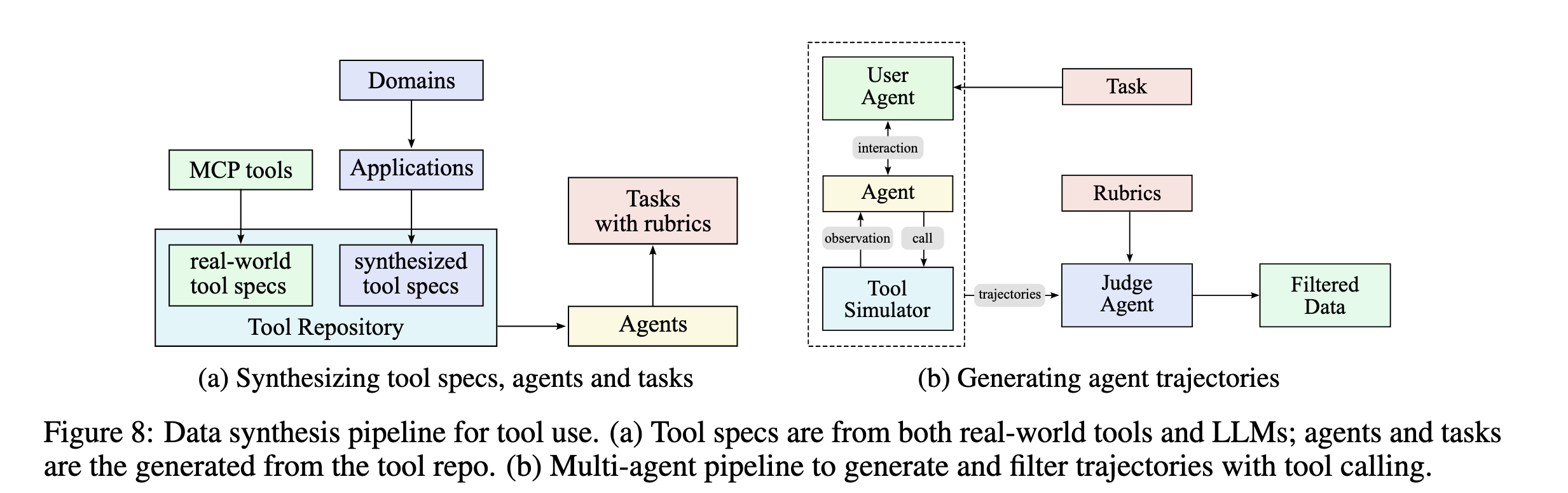
智能体的多样化 团队通过合成各种系统提示词并为其配备来自资源库的不同工具组合,生成了数千个不同的智能体。这创建了具有不同能力、专业领域和行为模式的多样化智能体群体,确保了潜在用例的广泛覆盖。
基于评价标准的任务生成 针对每个智能体配置,团队生成从简单到复杂的各种操作任务。每个任务都配备明确的评价标准,规定成功标准、期望的工具使用模式和评估检查点。这种基于评价标准的方法确保了智能体性能评估的一致性和客观性。
多轮轨迹生成 团队通过以下组件模拟真实的工具使用场景:
- 用户模拟:LLM生成具有不同沟通风格和偏好的用户角色,与智能体进行多轮对话,创建自然的交互模式。
- 工具执行环境:复杂的工具模拟器(功能等同于世界模型)执行工具调用并提供真实反馈。模拟器在每次工具执行后维护和更新状态,支持具有持续效果的复杂多步交互。它引入受控随机性,产生包括成功、部分失败和边缘情况在内的各种结果。
质量评估和筛选 基于LLM的评判者根据任务评价标准评估每个轨迹。只有满足成功标准的轨迹被保留用于训练,确保数据质量的同时允许任务完成策略的自然变化。
与真实执行环境的混合方法 虽然模拟提供了可扩展性,但团队认识到模拟保真度的固有局限性。为解决这一问题,团队在真实性至关重要的场景(特别是编程和软件工程任务)中,使用真实执行沙盒来补充模拟环境。这些真实沙盒执行实际代码,与真正的开发环境交互,并通过测试套件通过率等客观指标提供真实反馈。这种组合确保模型能够从模拟场景的多样性和真实执行的准确性中学习,显著增强实际智能体能力。
参考
[2507.20534] Kimi K2: Open Agentic Intelligence
https://zhuanlan.zhihu.com/p/1933619657589384402