GQA
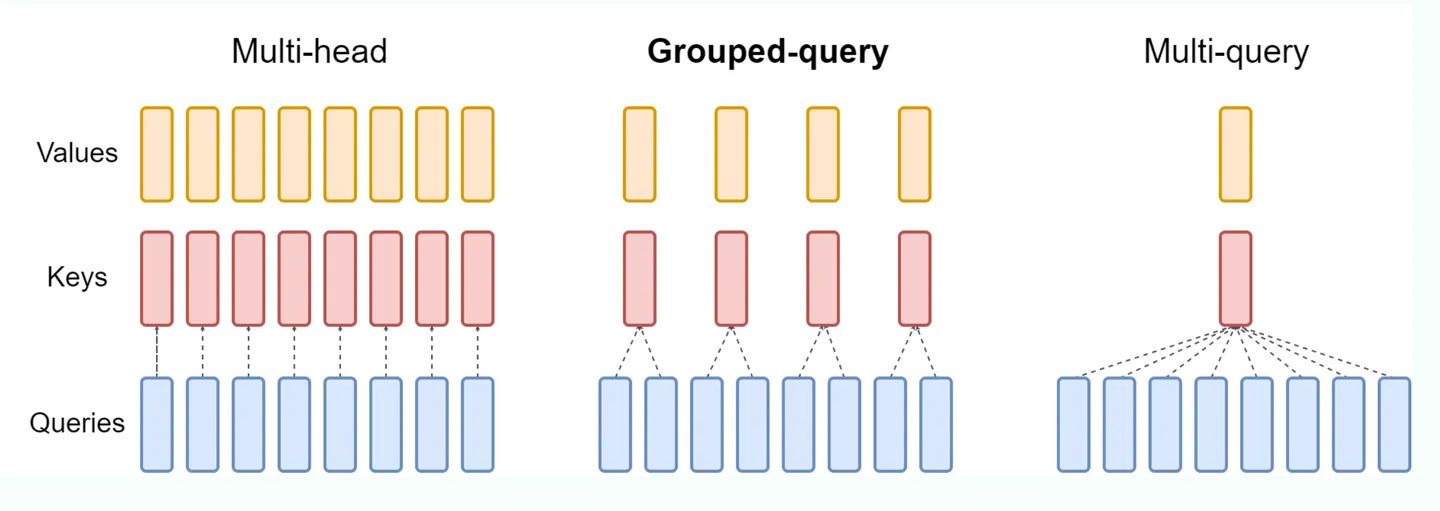
如上图所示,GQA 就是在 MHA 和 MQA 之间做了一个平衡。对 query heads 进行分组,分成几组就对应多少个 kv heads,然后每一组内的 query Heads 共享相同的 KV head。 GQA 可以在减少计算量和 KV Cache 同时确保模型效果不受到大的影响。
现在基本都使用 GQA,代码如下(核心是 repeat_kv 函数):
```python def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor: “““torch.repeat_interleave(x, dim=2, repeats=n_rep)”“” bs, slen, n_kv_heads, head_dim = x.shape if n_rep == 1: return x return ( x[:, :, :, None, :] .expand(bs, slen, n_kv_heads, n_rep, head_dim) .reshape(bs, slen, n_kv_heads * n_rep, head_dim) )
class Attention(nn.Module): “““Multi-head attention module.”“”
def __init__(self, args: ModelArgs):
"""
Initialize the Attention module.
Args:
args (ModelArgs): Model configuration parameters.
Attributes:
n_kv_heads (int): Number of key and value heads.
n_local_heads (int): Number of local query heads.
n_local_kv_heads (int): Number of local key and value heads.
n_rep (int): Number of repetitions for local heads.
head_dim (int): Dimension size of each attention head.
wq (ColumnParallelLinear): Linear transformation for queries.
wk (ColumnParallelLinear): Linear transformation for keys.
wv (ColumnParallelLinear): Linear transformation for values.
wo (RowParallelLinear): Linear transformation for output.
cache_k (torch.Tensor): Cached keys for attention.
cache_v (torch.Tensor): Cached values for attention.
"""
super().__init__()
self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads
model_parallel_size = fs_init.get_model_parallel_world_size()
self.n_local_heads = args.n_heads // model_parallel_size
self.n_local_kv_heads = self.n_kv_heads // model_parallel_size
self.n_rep = self.n_local_heads // self.n_local_kv_heads
self.head_dim = args.dim // args.n_heads
self.wq = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wk = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wv = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wo = RowParallelLinear(
args.n_heads * self.head_dim,
args.dim,
bias=False,
input_is_parallel=True,
init_method=lambda x: x,
)
# kv_cache是缓存键值对,在训练过程中,我们只保存最近n个键值对
self.cache_k = torch.zeros(
(
args.max_batch_size,
args.max_seq_len,
self.n_local_kv_heads,
self.head_dim,
)
).cuda()
self.cache_v = torch.zeros(
(
args.max_batch_size,
args.max_seq_len,
self.n_local_kv_heads,
self.head_dim,
)
).cuda()
def forward(
self,
x: torch.Tensor,
start_pos: int,
freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
):
"""
Forward pass of the attention module.
Args:
x (torch.Tensor): Input tensor.
start_pos (int): Starting position for caching.
freqs_cis (torch.Tensor): Precomputed frequency tensor.
mask (torch.Tensor, optional): Attention mask tensor.
Returns:
torch.Tensor: Output tensor after attention.
"""
# 假设当前x为(1, 1, dim),也就是上一个预测的token
# self-attention的输入,标准的(bs, seqlen, hidden_dim)
bsz, seqlen, _ = x.shape
# 计算当前token的qkv
# q k v分别进行映射,注意这里key, value也需要先由输入进行映射再和kv_cache里面的key, value进行拼接
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
# 对当前输入的query和key进行RoPE,注意kv_cache里面的key已经做过了RoPE
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
# 缓存当前token的kv
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
self.cache_k[:bsz, start_pos: start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos: start_pos + seqlen] = xv
# 取出前seqlen个token的kv缓存
# 取出全部缓存的key和value(包括之前在cache里面的和本次输入的),作为最终的key和value
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
# 将kv重复填充,使kv和q的头数个数相同
# repeat k/v heads if n_kv_heads < n_heads,对齐头的数量
keys = repeat_kv(keys, self.n_rep) # (bs, cache_len + seqlen, n_local_heads, head_dim)
values = repeat_kv(values, self.n_rep) # (bs, cache_len + seqlen, n_local_heads, head_dim)
# 计算当前token的attention score,,注意mask需要加上,另外维度要对应上
xq = xq.transpose(1, 2) # (bs, n_local_heads, seqlen, head_dim)
keys = keys.transpose(1, 2) # (bs, n_local_heads, cache_len + seqlen, head_dim)
values = values.transpose(1, 2) # (bs, n_local_heads, cache_len + seqlen, head_dim)
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
scores = scores + mask # (bs, n_local_heads, seqlen, cache_len + seqlen)
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values) # (bs, n_local_heads, seqlen, head_dim)
output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)
return self.wo(output)