GPT
GPT
预训练(从左到右的 Transformer 语言模型)
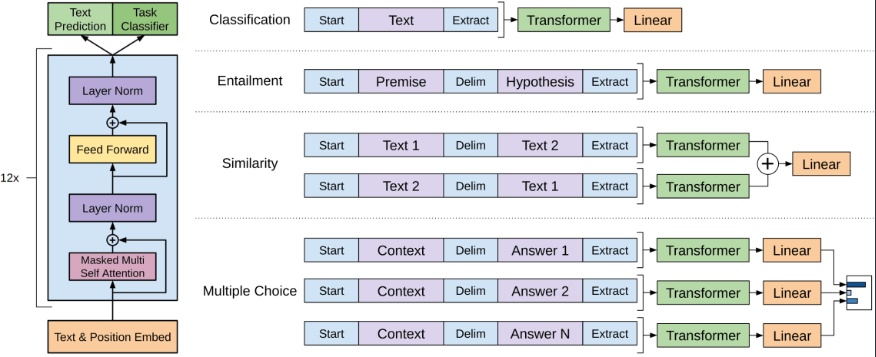
GPT 是一种基于 Transformer 的从左到右的语言模型。该架构是一个 12 层的
Transformer 解码器(没有解码器-编码器)。 ## 模型架构 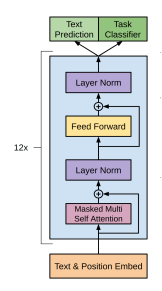
就是12层的transformer-decoder。其中只使用了transformer模型中的decoder部分,并且把decoder里面的encoder-decoder attention部分去掉了,只保留了masked self-attention,再加上feed-forward部分。再提一句,masked self-attention保证了GPT模型是一个单向的语言模型。 另外,作者在position encoding上做了调整,使用了可学习的位置编码,不同于transformer的三角函数位置编码。
微调:将 GPT 用于下游任务
微调损失包括特定于任务的损失以及语言建模损失:
\[ L = L_{xent} + \lambda \cdot L_{task}. \]