frequency_penalty&presence_penalty
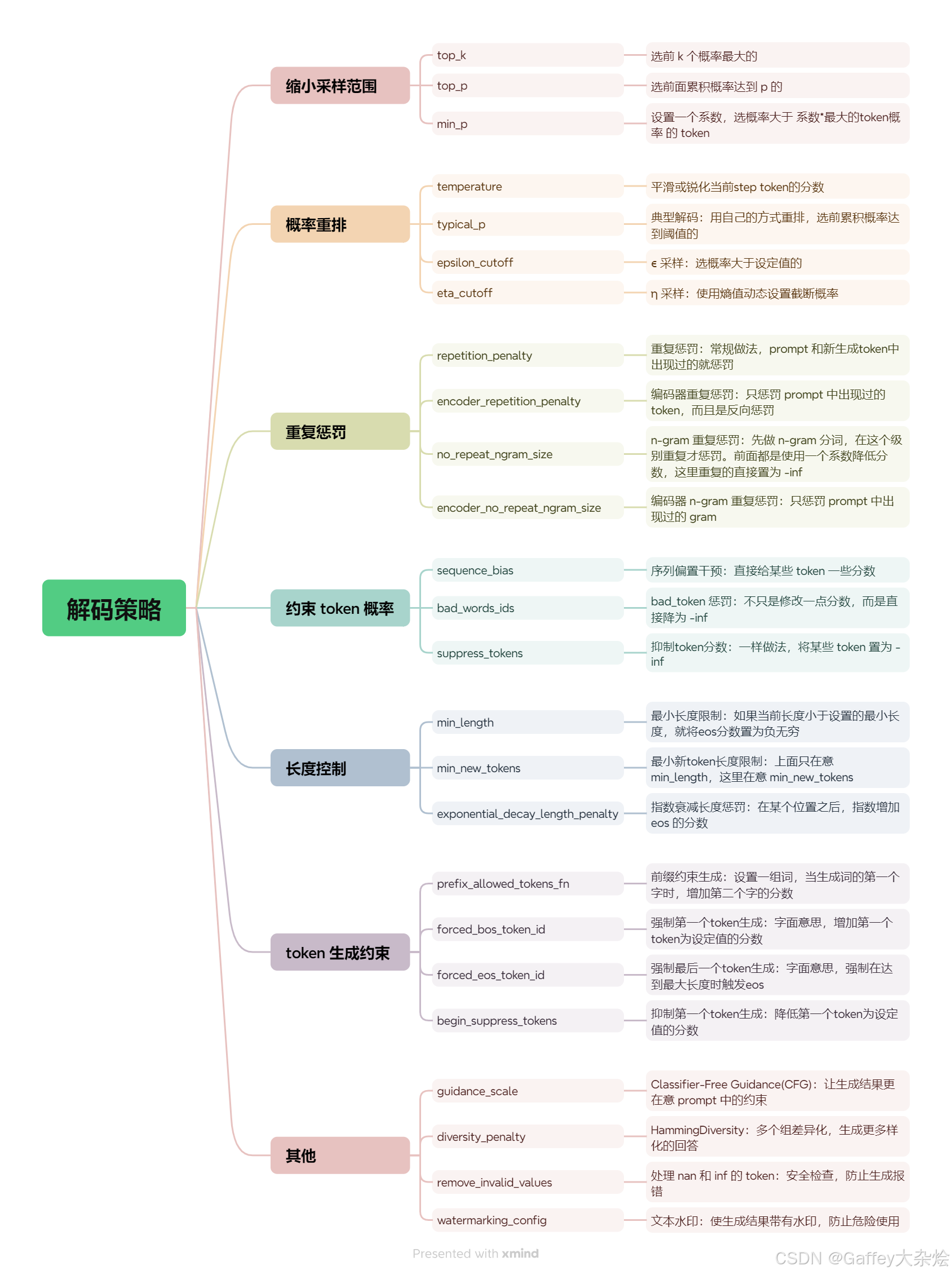
LLM解码时采用的自回归采样,其过程如下:
- 小模型使用前缀作为输入,将输出结果处理+归一化成概率分布后,采样生成下一个token。
- 将生成的token和前缀拼接成新的前缀,重复执行1,直到生成EOS或者达到最大token数目。
将模型输出logits的转换成概率,有几种常用的采样方法,包括argmax、top-k和top-n等
# 贪心搜索
直接选择概率最高的单词。这种方法简单高效,但是可能会导致生成的文本过于单调和重复
# 随机采样
按照概率分布随机选择一个单词。这种方法可以增加生成的多样性,但是可能会导致生成的文本不连贯和无意义。
# beam search 维护一个大小为 k
的候选序列集合,每一步从每个候选序列的概率分布中选择概率最高的 k
个单词,然后保留总概率最高的 k
个候选序列。这种方法可以平衡生成的质量和多样性,但是可能会导致生成的文本过于保守和不自然。
# top-k 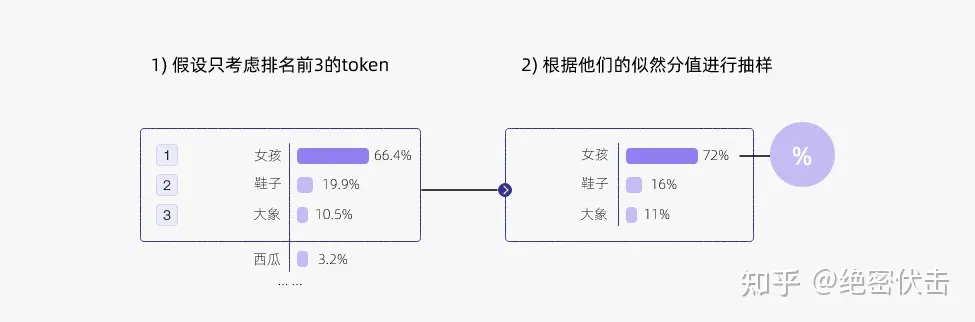
选取前k个token,然后再重新生成概率分布,再进行抽样
它可以与其他解码策略结合使用,例如温度调节(Temperature
Scaling)、重复惩罚(Repetition Penalty)、长度惩罚(Length
Penalty)等,来进一步优化生成的效果。 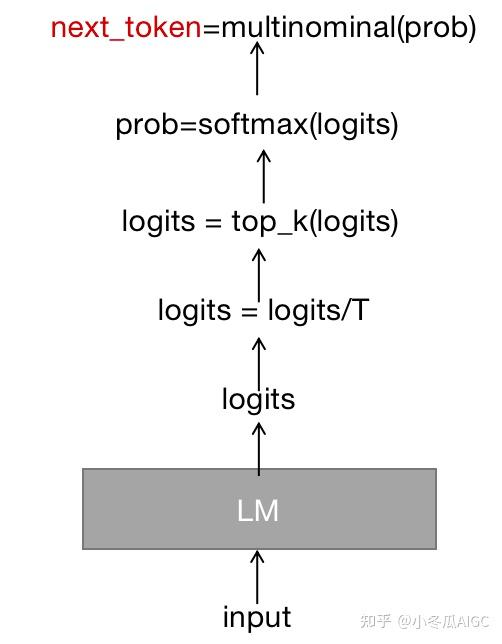
代码:
import torch
from labml_nn.sampling import Sampler
# Top-k Sampler
class TopKSampler(Sampler):
# k is the number of tokens to pick
# sampler is the sampler to use for the top-k tokens
# sampler can be any sampler that takes a logits tensor as input and returns a token tensor; e.g. `TemperatureSampler`.
def __init__(self, k: int, sampler: Sampler):
self.k = k
self.sampler = sampler
# Sample from logits
def __call__(self, logits: torch.Tensor):
# New logits filled with −∞; i.e. zero probability
zeros = logits.new_ones(logits.shape) * float('-inf')
# Pick the largest k logits and their indices
values, indices = torch.topk(logits, self.k, dim=-1)
# Set the values of the top-k selected indices to actual logits.
# Logits of other tokens remain −∞
zeros.scatter_(-1, indices, values)
# Sample from the top-k logits with the specified sampler.
return self.sampler(zeros)top-p
top-k 有一个缺陷,那就是“k
值取多少是最优的?”非常难确定。于是出现了动态设置 token
候选列表大小策略——即核采样(Nucleus Sampling)。 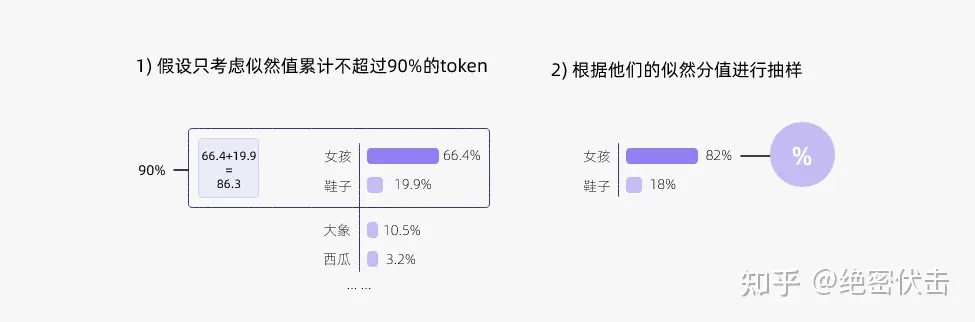
top-p 采样的思路是,在每一步,只从累积概率超过某个阈值 p 的最小单词集合中进行随机采样,而不考虑其他低概率的单词。这种方法也被称为核采样(nucleus sampling),因为它只关注概率分布的核心部分,而忽略了尾部部分。例如,如果 p=0.9,那么我们只从累积概率达到 0.9 的最小单词集合中选择一个单词,而不考虑其他累积概率小于 0.9 的单词。这样可以避免采样到一些不合适或不相关的单词,同时也可以保留一些有趣或有创意的单词。
import torch
from torch import nn
from labml_nn.sampling import Sampler
class NucleusSampler(Sampler):
"""
## Nucleus Sampler
"""
def __init__(self, p: float, sampler: Sampler):
"""
:param p: is the sum of probabilities of tokens to pick $p$
:param sampler: is the sampler to use for the selected tokens
"""
self.p = p
self.sampler = sampler
# Softmax to compute $P(x_i | x_{1:i-1})$ from the logits
self.softmax = nn.Softmax(dim=-1)
def __call__(self, logits: torch.Tensor):
"""
Sample from logits with Nucleus Sampling
"""
# Get probabilities $P(x_i | x_{1:i-1})$
probs = self.softmax(logits)
# Sort probabilities in descending order
sorted_probs, indices = torch.sort(probs, dim=-1, descending=True)
# Get the cumulative sum of probabilities in the sorted order
cum_sum_probs = torch.cumsum(sorted_probs, dim=-1)
# Find the cumulative sums less than $p$.
nucleus = cum_sum_probs < self.p
# Prepend ones so that we add one token after the minimum number
# of tokens with cumulative probability less that $p$.
nucleus = torch.cat([nucleus.new_ones(nucleus.shape[:-1] + (1,)), nucleus[..., :-1]], dim=-1)
# Get log probabilities and mask out the non-nucleus
sorted_log_probs = torch.log(sorted_probs)
sorted_log_probs[~nucleus] = float('-inf')
# Sample from the sampler
sampled_sorted_indexes = self.sampler(sorted_log_probs)
# Get the actual indexes
res = indices.gather(-1, sampled_sorted_indexes.unsqueeze(-1))
#
return res.squeeze(-1)Temperature采样
详见温度超参数
speculative decoding
大型语言模型(LLM)的推理通常需要使用自回归采样。它们的推理过程相当缓慢,需要逐个token地进行串行解码。因此,大型模型的推理过程往往受制于访存速度,生成每个标记都需要将所有参数从存储单元传输到计算单元,因此内存访问带宽成为严重的瓶颈。
为了解决推理速度慢的问题,已经进行了许多针对推理的工程优化,例如改进的计算核心实现、多卡并行计算、批处理策略等等。然而,这些方法并没有从根本上解决LLM解码过程是受制于访存带宽的问题。
投机采样是一种可以从根本上解码计算访存比的方法,保证和使用原始模型的采样分布完全相同。它使用两个模型:一个是原始目标模型,另一个是比原始模型小得多的近似模型。近似模型用于进行自回归串行采样,而大型模型则用于评估采样结果。解码过程中,某些token的解码相对容易,某些token的解码则很困难。因此,简单的token生成可以交给小型模型处理,而困难的token则交给大型模型处理。这里的小型模型可以采用与原始模型相同的结构,但参数更少,或者干脆使用n-gram模型。小型模型不仅计算量较小,更重要的是减少了内存访问的需求。 ## 采样过程 投机采样过程如下:
- 用小模型Mq做自回归采样连续生成 γ 个tokens。
- 把生成的γ个tokens和前缀拼接一起送进大模Mp执行一次forwards。
- 使用大、小模型logits结果做比对,如果发现某个token小模型生成的不好,重新采样这个token。重复步骤1。
- 如果小模型生成结果都满意,则用大模型采样下一个token。重复步骤1。
第2步,将γ个tokens和前缀拼成一起作为大模型输入,和自回归相比,尽管计算量一样,但是γ个tokens可以同时参与计算,计算访存比显著提升。
第3步,如何评价一个token生成的不好?如果q(x) >
p(x)(p,q表示在大小模型采样概率,也就是logits归一化后的概率分布)则以一定1-p(x)/q(x)为概率拒绝这个token的生成,从一个新的概率分布p’(x)
= norm(max(0, p(x) − q(x)))中重新采样一个token。 ## 例子  例如,在第一行中,近似模型生成了5个token,目标模型使用这5个token和前缀拼接后的句子”[START]
japan’s bechmark
bond”作为输入,通过一次推理执行来验证小模型的生成效果。这里,最后一个token
”bond“被目标模型拒绝,重新采样生成”n“。这样中间的四个tokens,”japan”
“’s”
“benchmark”都是小模型生成的。以此类推,由于用大模型对输入序列并行地执行,大模型只forward了9次,就生成了37个tokens。尽管总的大模型的计算量不变,但是大模型推理一个1个token和5个token延迟类似,这还是比大模型一个一个蹦词的速度要快很多。
# 惩罚参数
频率惩罚参数修改概率分布,以生成模型在训练过程中不常见的词。这鼓励模型生成新颖或不太常见的词。它的工作原理是缩放模型在训练过程中常见词的对数概率,从而降低模型生成这些常见词的可能性。
例如,在第一行中,近似模型生成了5个token,目标模型使用这5个token和前缀拼接后的句子”[START]
japan’s bechmark
bond”作为输入,通过一次推理执行来验证小模型的生成效果。这里,最后一个token
”bond“被目标模型拒绝,重新采样生成”n“。这样中间的四个tokens,”japan”
“’s”
“benchmark”都是小模型生成的。以此类推,由于用大模型对输入序列并行地执行,大模型只forward了9次,就生成了37个tokens。尽管总的大模型的计算量不变,但是大模型推理一个1个token和5个token延迟类似,这还是比大模型一个一个蹦词的速度要快很多。
# 惩罚参数
频率惩罚参数修改概率分布,以生成模型在训练过程中不常见的词。这鼓励模型生成新颖或不太常见的词。它的工作原理是缩放模型在训练过程中常见词的对数概率,从而降低模型生成这些常见词的可能性。
而存在惩罚参数修改概率分布,以使输入提示中出现的词不太可能出现在输出中。这鼓励模型生成输入中没有的词。它的工作原理是缩放输入中存在词的对数概率,使模型不太可能生成输入中已经存在的单词。
简单地说,频率惩罚控制模型输出用词的新颖性,而存在惩罚控制模型谈论新主题的可能性。 # 参考 ChatGPT模型中的惩罚机制_frequency penalty-CSDN博客
大模型推理妙招—投机采样(Speculative Decoding) - 知乎 (zhihu.com)
大模型文本生成——解码策略(Top-k & Top-p & Temperature) (zhihu.com)
https://zhuanlan.zhihu.com/p/667025336