focal loss
Focal Loss
Focal Loss主要是为了解决类别不平衡的问题,Focal Loss可以运用于二分类,也可以运用于多分类。下面以二分类为例:
原始Loss
原始的二分类: 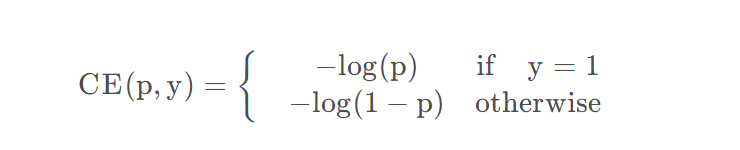
其中 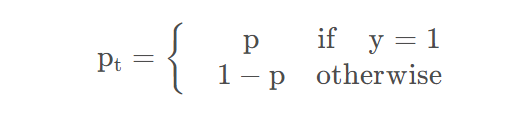
所以: 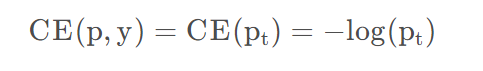
很容易理解,因为CE就是softmax在二分类的形式,实际运算中只关注对应标签的概率,对于二分类,如果是负样本的话,预测概率小于0.5则说明预测正确,则对应的实际的概率应该为1-p。最大化概率,就是最大化Log概率,也就是最小化-log概率。
什么是易分类样本
- 对于正样本,如果预测的结果总是在0.5以上,就是易分类样本,如果总是在0.5以下,则说明是难分类样本。
- 对于负样本,如果预测的结果总是在0.5以下,就是易分类样本,如果总是在0.5以上,则说明是难分类样本。
对应\(p_t\)来说,就是\(p_t>0.5\)为易分类,\(p_t<0.5\)为难分类。
gamma参数
在模型训练的时候,我们更希望关注难分类的样本,因此focal
loss在原始loss上增加了一项,对整体进行了衰减: 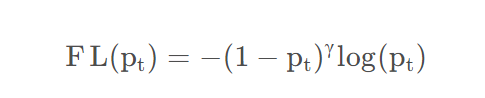
对于公式中的参数\(\gamma\),一般会选择2,对于易分类的样本,即\(p_t>0.5\)的样本,\(1-p_t\)则会小于0.5,则loss会衰减的更多,最终的损失就变的很小。而对于难分类的样本,loss会衰减的比较小,通过这种衰减的对比,则变相增加了模型对于难分类样本的权重。
alpha参数
对于二分类任务,负样本的数量远远多于正样本,导致模型更多关注在负样本上,忽略正样本。因此在使用交叉熵损失的时候通常会增加一个平衡参数用来调节正负样本的比重。
所以会增加一个平衡参数来调节正负样本的比重。 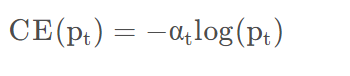
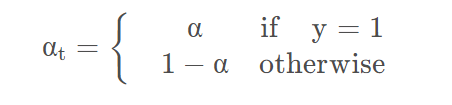
其实这就是balanced cross entropy,可以将它引入focal loss
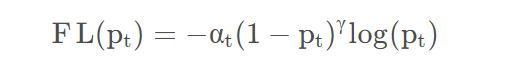
在式子中,\(\gamma\)占据了主导地位,因此其实不用太在意\(\alpha\)的数值。
对于多分类
对于多分类任务,其实是一样的,因为如果一个类别的样本预测结果总是大于0.5,也说明它是易分类的,对于平衡因子,在实现的时候,可以提前设置好各类别的平衡因子,对于每一个类别都有一个对应的。
为什么有效
focal loss从样本难易分类角度出发,解决样本非平衡带来的模型训练问题。
直觉上来讲样本非平衡造成的问题就是样本数少的类别分类难度较高。因此从样本难易分类角度出发,使得loss聚焦于难分样本,解决了样本少的类别分类准确率不高的问题,当然难分样本不限于样本少的类别,也就是focal loss不仅仅解决了样本非平衡的问题,同样有助于模型的整体性能提高。
思考
难分类样本与易分类样本其实是一个动态概念,也就是说 p 会随着训练过程而变化。原先易分类样本即 p大的样本,可能随着训练过程变化为难训练样本即p小的样本。
上面讲到,由于Loss梯度中,难训练样本起主导作用,即参数的变化主要是朝着优化难训练样本的方向改变。当参数变化后,可能会使原先易训练的样本 p 发生变化,即可能变为难训练样本。当这种情况发生时,可能会造成模型收敛速度慢,正如苏剑林在他的文章中提到的那样。
为了防止难易样本的频繁变化,应当选取小的学习率。 ## 代码 ### 二分类
class Focal_Loss():
"""
二分类Focal Loss
"""
def __init__(self,alpha=0.25,gamma=2):
super(Focal_Loss,self).__init__()
self.alpha=alpha
self.gamma=gamma
def forward(self,preds,labels):
"""
preds:sigmoid的输出结果
labels:标签
"""
eps=1e-7
loss_1=-1*self.alpha*torch.pow((1-preds),self.gamma)*torch.log(preds+eps)*labels
loss_0=-1*(1-self.alpha)*torch.pow(preds,self.gamma)*torch.log(1-preds+eps)*(1-labels)
loss=loss_0+loss_1
return torch.mean(loss)多分类
class Focal_Loss():
def __init__(self,weight,gamma=2):
super(Focal_Loss,self).__init__()
self.gamma=gamma
self.weight=weight
def forward(self,preds,labels):
"""
preds:softmax输出结果
labels:真实值
"""
eps=1e-7
y_pred =preds.view((preds.size()[0],preds.size()[1],-1)) #B*C*H*W->B*C*(H*W)
target=labels.view(y_pred.size()) #B*C*H*W->B*C*(H*W)
ce=-1*torch.log(y_pred+eps)*target
floss=torch.pow((1-y_pred),self.gamma)*ce
floss=torch.mul(floss,self.weight)
floss=torch.sum(floss,dim=1)
return torch.mean(floss)