Ensemble Learning
集成学习
在机器学习的有监督学习算法中,我们的目标是学习出一个稳定的且在各个方面表现都较好的模型,但实际情况往往不这么理想,有时我们只能得到多个有偏好的模型(弱监督模型,在某些方面表现的比较好)。集成学习就是组合这里的多个弱监督模型以期得到一个更好更全面的强监督模型,集成学习潜在的思想是即便某一个弱分类器得到了错误的预测,其他的弱分类器也可以将错误纠正回来。 集成学习在各个规模的数据集上都有很好的策略。 数据集大:划分成多个小数据集,学习多个模型进行组合 数据集小:利用Bootstrap方法进行抽样,得到多个数据集,分别训练多个模型再进行组合
集成学习主要有两类: 1. Bagging
- Boosting
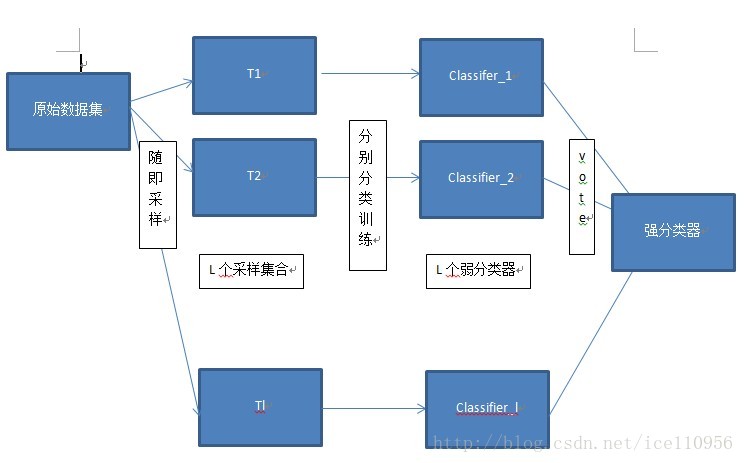
Bagging算法是这样做的:每个分类器都随机从原样本中做有放回的采样,然后分别在这些采样后的样本上训练分类器,然后再把这些分类器组合起来。简单的多数投票一般就可以。其代表算法是随机森林。
Boosting的意思是这样,他通过迭代地训练一系列的分类器,每个分类器采用的样本分布都和上一轮的学习结果有关。其代表算法是AdaBoost, GBDT。
Bagging
bagging的名称来源于 ( Bootstrap Aggregating ),意思是自助抽样集成,这种方法将训练集分成m个新的训练集,然后在每个新训练集上构建一个模型,各自不相干,最后预测时我们将这个m个模型的结果进行整合,得到最终结果。整合方式就是:分类问题用majority voting,回归用均值。
因此Bagging使用的抽样方法是Bootstrap方法,即自助法,本质上就是一个有放回的随机抽样问题。 每一个样本在每一次抽的时候有同样的概率\(\frac{1}{N}\)被抽中。没被抽中的概率为\(1-\frac{1}{N}\),一共抽了N次,即\(1-(\frac{1}{N})^N\)当N趋于无穷时,由高等数学学的极限的求解可以算出来是\(\frac{1}{e}\),大概为36.8%,这些留下来的1/3的样本可以作为验证集,这样的方式叫做包外估计(out of bag estimate)
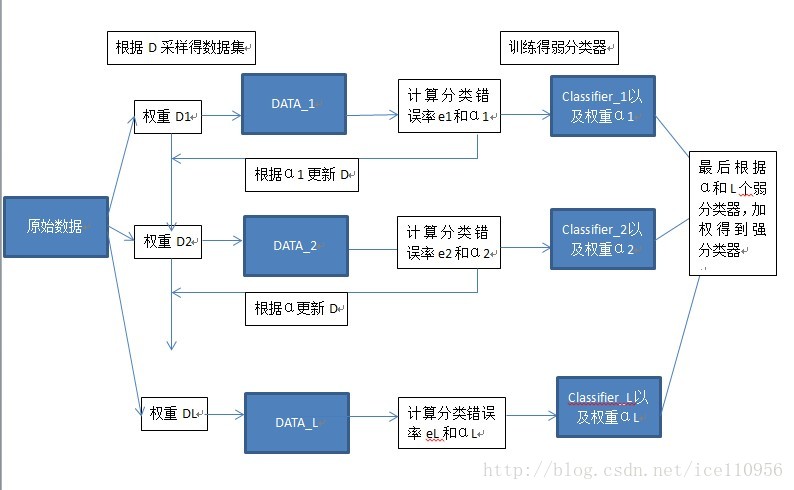
Boosting
Boosting与Bagging的区别就是取样方式不同,Bagging采用均匀取样,而Boosting根据错误率来取样,因此Boosting的分类精度要优于Bagging。。Bagging的训练集的选择是随机的,各轮训练集之间相互独立,而Boostlng的各轮训练集的选择与前面各轮的学习结果有关;Bagging的各个预测函数没有权重,而Boosting是有权重的;Bagging的各个预测函数可以并行生成,而Boosting的各个预测函数只能顺序生成。对于象神经网络这样极为耗时的学习方法。Bagging可通过并行训练节省大量时间开销。很好理解吧。
一个故事
一个故事用于理解,来源:https://www.joinquant.com/view/community/detail/adfb5ce37f0b39e348aae32e8412c68c
有一个医学专(砖)家,他看过很多很多病人,还记了小本本来归类这些病人的特征和病情来方便以后诊断。有一天来了个病人,这个专家就问病人了,“大爷您贵姓?多少岁,哪不舒服,病情怎么样?”大爷说 “我姓李,48,最近老吐痰,老咳嗽,还发烧…”。这个专家拿出他的小本本一查“”属性:“姓李”,“年龄48”,“吐痰”,“咳嗽”,“发烧”…,根据我的小本本以前这样的病例有80个,有76个是感冒,成,就诊断他是感冒了!”这个专家就是棵决策树
镜头一转,来到医院A,同样的病人来医院A治病。医院有很大的病例数据库,有100个医学专家通过学习数据库的一部分知识形成了自己的诊断方案。医院想:“我财大气粗,为了提供更好的医疗服务,我让100个专家做诊断,然后他们投票决出最后的判断”。 随机森林 完成
医院B就不爽了,你这治疗方案太受欢迎,把客户都抢走了,我要用科学的治疗方案来击败你。医院B想了想,大家投票不一定针对到用户情况,我先从我的100个专家里找一个最好的先给病人做一个诊疗方案,再根据第一个专家的不足找第二个,根据第二个再找第三个…… 最后不同专家再根据他们诊断的表现以不同权重投票。这样岂不是更针对病人痛点? Boosting 方法就被这群人建立起来了
到了医院C想搞差异化,你医院B根据上一个专家的全部不足找新专家,那我就根据上一个专家判断最偏颇的方向找专家,虽然听起来差不多,但我的差异化说不定就能更好。 Gradient Boosting 产生了
更加财大气粗的医院D来了,他觉得虽然整个市场的大格调基本确定,但我可以通过提升整个诊疗的流程大大小小的细节来取胜啊!于是医院D在C的基础上改进了很多,于是找偏颇的方向更快更准,纠结专家,诊疗的速度也大大加快,整个医院的硬件设施也前所未有的提高。这差不多就是 XGBoost 了
突然有股叫大数据的潮流吹来,本来医院D已经在医院C一分钟治疗10000人的基础上提升了10多倍速度,但新的要求是:一分钟不行,最多给你3秒,10万人也不行,我现在有全世界的数据,你得分秒内召集几百几千个专家,这些专家每一个的知识得相当于以前一个医院那没多,还得分秒内服务数10倍的病人,最后治疗的精度不能下降。 LightGBM 出场了,虽然精度提高不多,但速度大大加快了。