ELMo
ELMo
在Transformer中提到了ELMo解决了word2vec中存在的多义词问题,其使用双向的LSTM作为特征提取器,考虑了上下文的语义,所以可以解决多义词问题。这篇文章就详细介绍一下ELMo。
ElMo与CoVe很类似,不过它不是基于机器翻译模型,而是语言模型。仅仅通过用来自 LM 的嵌入替换词嵌入 (GloVe),他们就在问答、共指解析、情感分析、命名实体识别等多项任务上获得了巨大的改进。
模型训练(char-CNN 之上的前向和后向 LSTM-LMs)
该模型非常简单,它由两层 LSTM 语言模型组成:前向和后向。使用这两种模型是为了使每个标记都可以具有两个上下文:左和右。
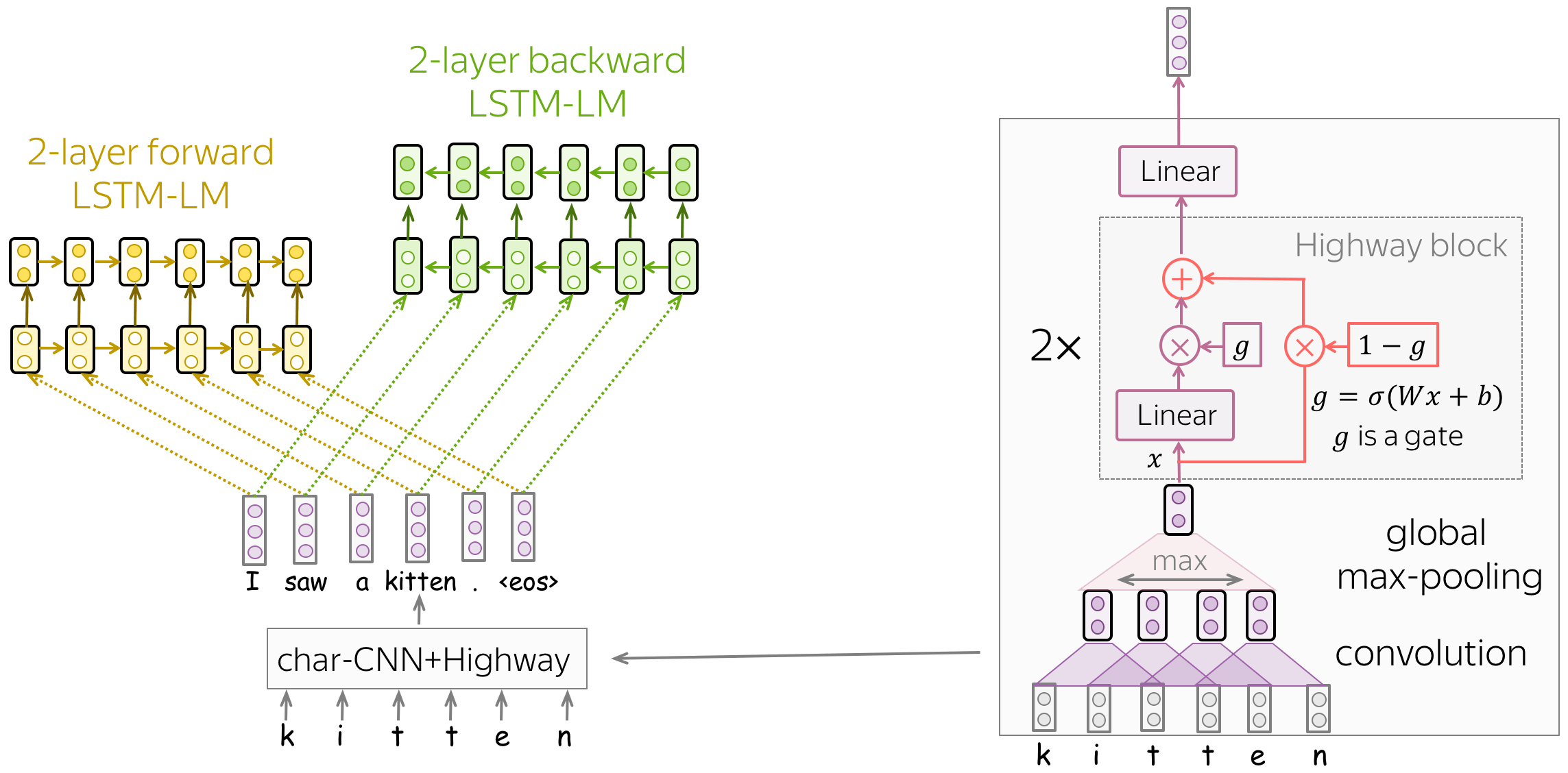
同样有趣的是作者如何获得初始单词表示(然后将其馈送到 LSTM)。让我们回想一下,在标准词嵌入层中,对于词汇表中的每个词,我们训练一个唯一的向量。在这种情况下, - 词嵌入不知道它们所包含的字符(例如,它们不知道单词represent, represents, represented, 和 representation在书面上是接近的) - OOV问题 为了解决这些问题,作者将单词表示为字符级网络的输出。正如我们从插图中看到的,这个 CNN 非常简单,由我们之前已经看到的组件组成:卷积、全局池化、highway connections和线性层。通过这种方式,单词表示通过构造知道它们的字符,我们甚至可以表示那些我们在训练中从未见过的单词。
获取表示
训练模型后,我们可以使用它来获取单词表示。为此,对于每个单词,我们结合来自前向和后向 LSTM 的相应层的表示。通过连接这些前向和后向向量,我们构建了一个“知道”左右上下文的单词表示。
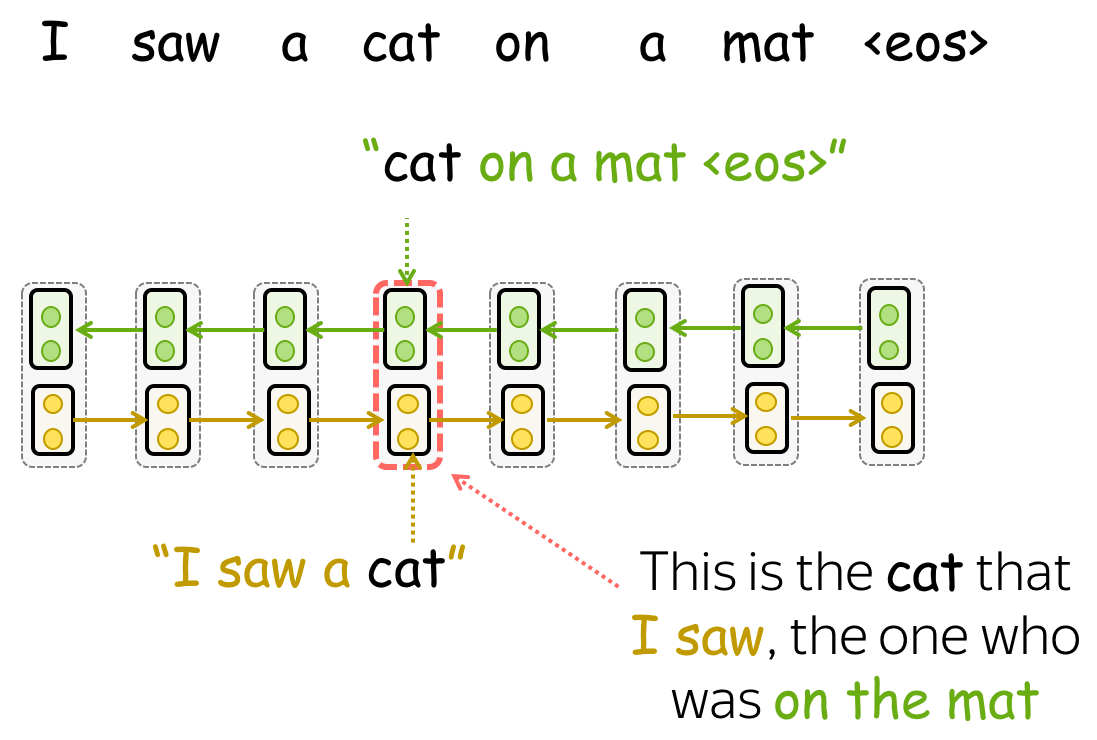
总体而言,ELMo 表示具有三层:
- 第 0 层(嵌入) - 字符级 CNN 的输出;
- 第 1 层- 来自前向和后向 LSTM 的第 1 层的连接表示;
- 第 2 层- 来自前向和后向 LSTM 的第 2 层的连接表示;
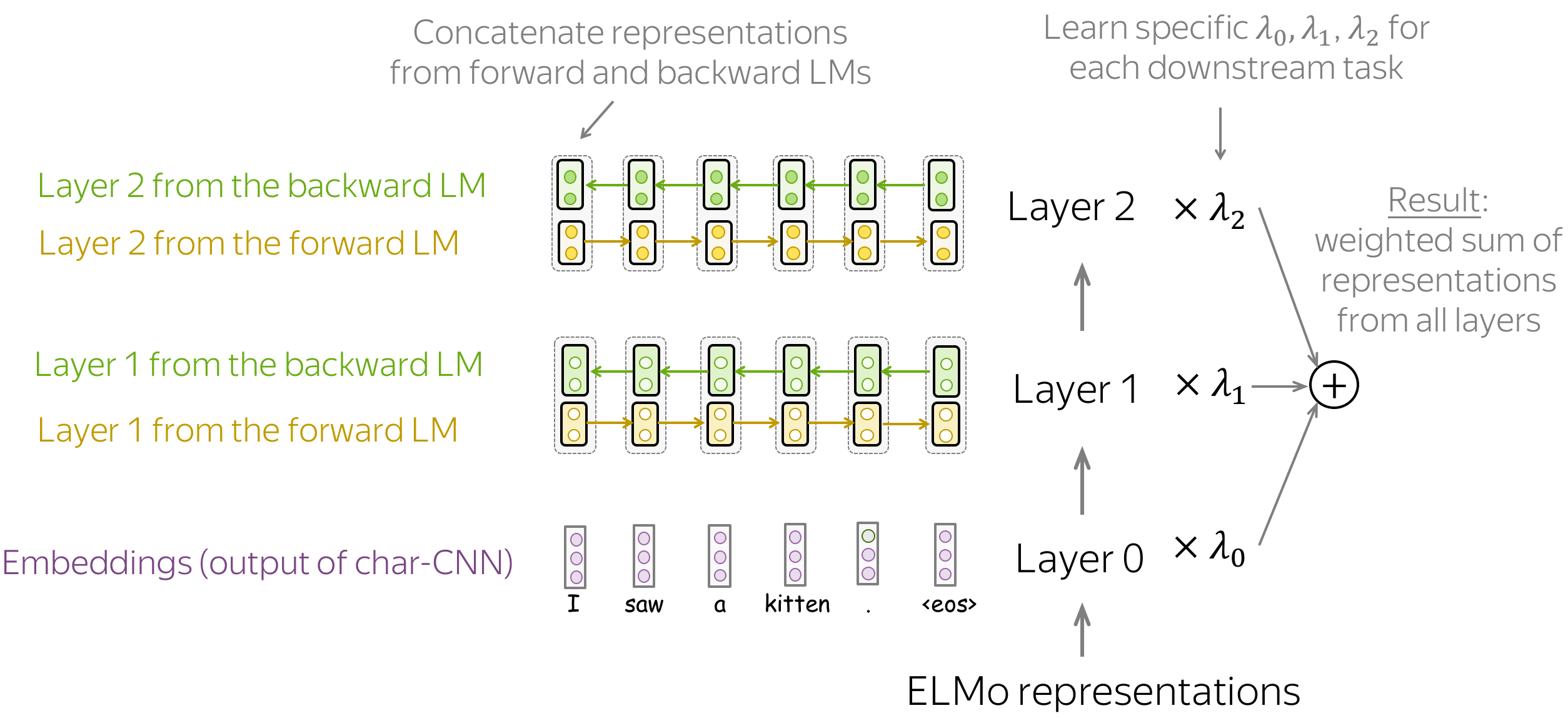
这些层中的每一层都对不同类型的信息进行编码:第 0 层 - 仅单词级别,第 1 层和第 2 层 - 上下文中的单词。比较第 1 层和第 2 层,第 2 层可能包含更多高级信息:这些表示来自相应 LM 的更高层。
由于不同的下游任务需要不同种类的信息,ELMo 使用特定于任务的权重来组合来自三层的表示。这些是为每个下游任务学习的标量。得到的向量,即所有层表示的加权和,用于表示一个单词。
总结
CoVe和ELMo都用了上下文单词,解决了word2vec中多义词的问题。但他们主要是替换嵌入层,并保持特定于任务的模型架构几乎完好无损。这意味着例如,对于共指解决,必须使用为此任务设计的特定模型,用于词性标记 - 一些其他模型,用于问答 - 另一个非常特殊的模型等。对于这些任务中的每一个,专门研究它的研究人员不断改进特定于任务的模型架构。
与以前的模型相比,GPT/BERT 不是作为词嵌入的替代品,而是作为特定任务模型的替代品。在这个新设置中,首先使用大量未标记数据(纯文本)对模型进行预训练。然后,该模型在每个下游任务上进行微调。重要的是,现在在微调期间,您必须只使用任务感知输入转换(即以某种方式提供数据), 而不是 修改模型架构。