Dataset
详细讲解一下verl中的RLHFDataset,它继承自torch的Dataset,需要实现__getitem__来返回数据。
初始化
class RLHFDataset(Dataset):
"""
Load and preprocess RLHF data from Parquet files.
- Caches files locally.
- Reads into a HuggingFace Dataset and tokenizes prompts.
- Optionally handles images/videos via a ProcessorMixin.
- Filters prompts over a max length.
- Supports resuming from checkpoints.
Args:
data_files (str or list): Path(s) to Parquet file(s).
tokenizer (PreTrainedTokenizer): For the tokenization of text to token IDs.
config (DictConfig): Options like cache_dir, prompt_key, max_prompt_length, truncation, etc.
processor (ProcessorMixin, optional): Multimodal preprocessor for images/videos.
"""
def __init__(
self,
data_files: str | list[str],
tokenizer: PreTrainedTokenizer,
config: DictConfig,
processor: Optional[ProcessorMixin] = None,
):
if not isinstance(data_files, list | ListConfig):
data_files = [data_files]
self.data_files = copy.deepcopy(data_files)
self.original_data_files = copy.deepcopy(data_files) # use for resume
self.tokenizer = tokenizer
self.processor = processor
self.config = config
self.cache_dir = os.path.expanduser(config.get("cache_dir", "~/.cache/verl/rlhf"))
self.prompt_key = config.get("prompt_key", "prompt")
self.image_key = config.get("image_key", "images")
self.video_key = config.get("video_key", "videos")
self.max_prompt_length = config.get("max_prompt_length", 1024)
self.return_raw_chat = config.get("return_raw_chat", False)
self.return_full_prompt = config.get("return_full_prompt", False)
self.truncation = config.get("truncation", "error")
self.filter_overlong_prompts = config.get("filter_overlong_prompts", True)
self.num_workers = config.get("filter_overlong_prompts_workers", max(1, os.cpu_count() // 4))
self.num_workers = min(self.num_workers, os.cpu_count())
self.use_shm = config.get("use_shm", False)
self.chat_template_func = config.get("chat_template_func", None)
self.need_tools_kwargs = config.get("need_tools_kwargs", False)
self.filter_prompts = config.get("filter_prompts", True)
self.serialize_dataset = False
self.return_multi_modal_inputs = config.get("return_multi_modal_inputs", True)
self._download()
self._read_files_and_tokenize()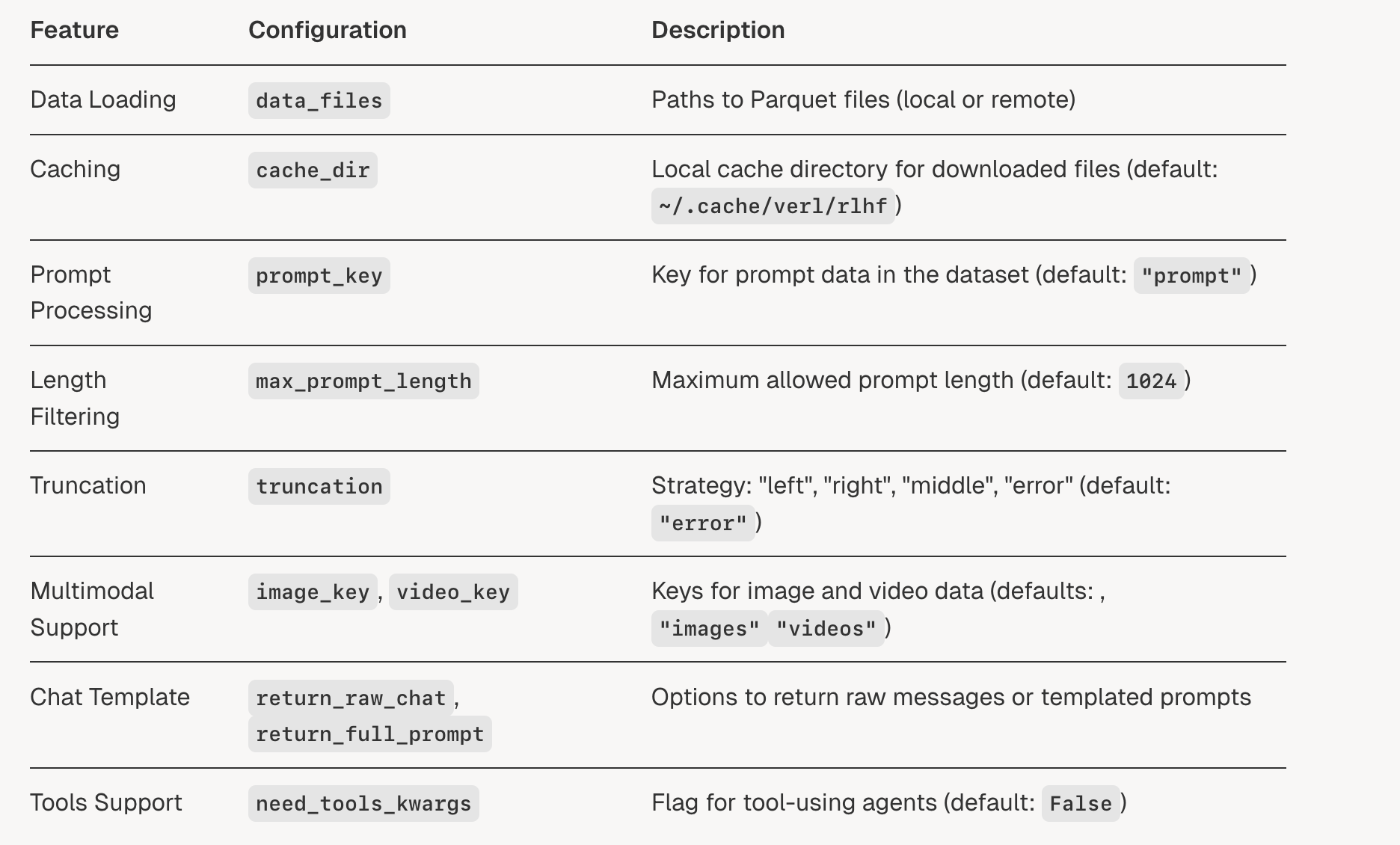 (来自deepwiki)
(来自deepwiki)
download方法就是把hdfs文件或者本地文件缓存到缓存路径下。
接下来重点看一下read_files_and_tokenize方法:
def _read_files_and_tokenize(self):
dataframes = []
for parquet_file in self.data_files:
# read parquet files and cache
dataframe = datasets.load_dataset("parquet", data_files=parquet_file)["train"]
dataframes.append(dataframe)
self.dataframe: datasets.Dataset = datasets.concatenate_datasets(dataframes)
print(f"dataset len: {len(self.dataframe)}")
self.dataframe = self.maybe_filter_out_long_prompts(self.dataframe)
def maybe_filter_out_long_prompts(self, dataframe: datasets.Dataset = None):
# filter out too long prompts
if self.filter_overlong_prompts:
tokenizer = self.tokenizer
processor = self.processor
prompt_key = self.prompt_key
image_key = self.image_key
video_key = self.video_key
if processor is not None:
from verl.utils.dataset.vision_utils import process_image, process_video
def doc2len(doc) -> int:
messages = self._build_messages(doc)
raw_prompt = self.processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=False
)
images = [process_image(image) for image in doc[image_key]] if image_key in doc else None
videos = [process_video(video) for video in doc[video_key]] if video_key in doc else None
return len(processor(text=[raw_prompt], images=images, videos=videos)["input_ids"][0])
else:
def doc2len(doc) -> int:
return len(tokenizer.apply_chat_template(doc[prompt_key], add_generation_prompt=True))
dataframe = dataframe.filter(
lambda doc: doc2len(doc) <= self.max_prompt_length,
num_proc=self.num_workers,
desc=f"Filtering prompts longer than {self.max_prompt_length} tokens",
)
print(f"filter dataset len: {len(dataframe)}")
return dataframe实现了读取parquet文件,然后再根据传入的prompt_length筛选掉prompt长度超过length的样本。返回的是dataframe。
然后就到了最重要的__getitem__方法,来构造我们需要的数据:
def __getitem__(self, item):
"""
Note that we also return the raw_input_ids so that it can be combined with other chat template
"""
row_dict: dict = self.dataframe[item]
messages = self._build_messages(row_dict)
model_inputs = {}
if self.processor is not None:
from verl.utils.dataset.vision_utils import process_image, process_video
raw_prompt = self.processor.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
multi_modal_data = {}
images = None
if self.image_key in row_dict and row_dict.get(self.image_key, None) is not None:
images = [process_image(image) for image in row_dict.pop(self.image_key)]
# due to the image key is "image" instead of "images" in vllm, we need to use "image" here
# link: https://github.com/vllm-project/vllm/blob/3c545c0c3b98ee642373a308197d750d0e449403/vllm/multimodal/parse.py#L205
multi_modal_data["image"] = images
videos = None
if self.video_key in row_dict and row_dict.get(self.video_key, None) is not None:
videos = [process_video(video) for video in row_dict.pop(self.video_key)]
# due to the video key is "video" instead of "videos" in vllm, we need to use "video" here
# link: https://github.com/vllm-project/vllm/blob/3c545c0c3b98ee642373a308197d750d0e449403/vllm/multimodal/parse.py#L205
multi_modal_data["video"] = [video.numpy() for video in videos]
model_inputs = self.processor(text=[raw_prompt], images=images, videos=videos, return_tensors="pt")
input_ids = model_inputs.pop("input_ids")
attention_mask = model_inputs.pop("attention_mask")
if "second_per_grid_ts" in model_inputs:
model_inputs.pop("second_per_grid_ts")
# There's a trap here, multi_modal_inputs has to be a dict, not BatchFeature
row_dict["multi_modal_data"] = multi_modal_data
# We will do batch.union() in the trainer,
# so we cannot have "multi_modal_inputs" in row_dict if rollout generates new multi_modal_inputs
if self.return_multi_modal_inputs:
row_dict["multi_modal_inputs"] = dict(model_inputs)
# second_per_grid_ts isn't used for training, just for mrope
row_dict["multi_modal_inputs"].pop("second_per_grid_ts", None)
else:
raw_prompt = self.tokenizer.apply_chat_template(messages, add_generation_prompt=True, tokenize=False)
model_inputs = self.tokenizer(raw_prompt, return_tensors="pt", add_special_tokens=False)
input_ids = model_inputs.pop("input_ids")
attention_mask = model_inputs.pop("attention_mask")
input_ids, attention_mask = verl_F.postprocess_data(
input_ids=input_ids,
attention_mask=attention_mask,
max_length=self.max_prompt_length,
pad_token_id=self.tokenizer.pad_token_id,
left_pad=True,
truncation=self.truncation,
)
if self.processor is not None and "Qwen2VLImageProcessor" in self.processor.image_processor.__class__.__name__:
from verl.models.transformers.qwen2_vl import get_rope_index
position_ids = [
get_rope_index(
self.processor,
input_ids=input_ids[0],
image_grid_thw=model_inputs.get("image_grid_thw"),
video_grid_thw=model_inputs.get("video_grid_thw"),
second_per_grid_ts=model_inputs.get("second_per_grid_ts"),
attention_mask=attention_mask[0],
)
] # (1, 3, seq_len)
else:
position_ids = compute_position_id_with_mask(attention_mask)
row_dict["input_ids"] = input_ids[0]
row_dict["attention_mask"] = attention_mask[0]
row_dict["position_ids"] = position_ids[0]
raw_prompt_ids = self.tokenizer.encode(raw_prompt, add_special_tokens=False)
if len(raw_prompt_ids) > self.max_prompt_length:
if self.truncation == "left":
raw_prompt_ids = raw_prompt_ids[-self.max_prompt_length :]
elif self.truncation == "right":
raw_prompt_ids = raw_prompt_ids[: self.max_prompt_length]
elif self.truncation == "middle":
left_half = self.max_prompt_length // 2
right_half = self.max_prompt_length - left_half
raw_prompt_ids = raw_prompt_ids[:left_half] + raw_prompt_ids[-right_half:]
elif self.truncation == "error":
raise RuntimeError(f"Prompt length {len(raw_prompt_ids)} is longer than {self.max_prompt_length}.")
row_dict["raw_prompt_ids"] = raw_prompt_ids
# encode prompts without chat template
if self.return_raw_chat:
row_dict["raw_prompt"] = messages
# get prompts with chat template
if self.return_full_prompt:
row_dict["full_prompts"] = raw_prompt # array of strings
# add index for each prompt
index = row_dict.get("extra_info", {}).get("index", 0)
tools_kwargs = row_dict.get("extra_info", {}).get("tools_kwargs", {})
interaction_kwargs = row_dict.get("extra_info", {}).get("interaction_kwargs", {})
need_tools_kwargs = row_dict.get("extra_info", {}).get("need_tools_kwargs", self.need_tools_kwargs)
if need_tools_kwargs and not tools_kwargs:
logger.warning("tools_kwargs is empty for index {}, data source: {}", index, row_dict["data_source"])
row_dict["index"] = index
row_dict["tools_kwargs"] = tools_kwargs
row_dict["interaction_kwargs"] = interaction_kwargs
return row_dict对于纯文本数据,build_messages方法就是获取prompt_key对应的内容,对于多模态的处理,先不做讲解。processor就是处理多模态数据的,跳到else部分,就是对message调用apply_chat_template,这就要求我们的数据文件需要先处理成这样的格式,详见verl/examples/data_preprocess中的处理。 将raw_prompts保存起来,然后再进行tokenize,postprocess_data是对其进行padding和截断。
def postprocess_data(
input_ids: torch.Tensor,
attention_mask: torch.Tensor,
max_length: int,
pad_token_id: int,
left_pad=True,
truncation="error",
):
"""Process tokenizer outputs to consistent shapes via padding/truncation.
Args:
input_ids: Token indices [batch_size, seq_len]
attention_mask: Mask [batch_size, seq_len]
max_length: Target sequence length
pad_token_id: Padding token ID
left_pad: Pad left if True
truncation: "left", "right", "middle" or "error"
Returns:
(input_ids, attention_mask) padded/truncated to max_length
"""
assert truncation in ["left", "right", "middle", "error"]
assert input_ids.ndim == 2
sequence_length = input_ids.shape[-1]
if sequence_length < max_length:
input_ids = pad_sequence_to_length(
input_ids, max_seq_len=max_length, pad_token_id=pad_token_id, left_pad=left_pad
)
attention_mask = pad_sequence_to_length(
attention_mask, max_seq_len=max_length, pad_token_id=0, left_pad=left_pad
)
elif sequence_length > max_length:
if truncation == "left":
# actually, left truncation may not be reasonable
input_ids = input_ids[:, -max_length:]
attention_mask = attention_mask[:, -max_length:]
elif truncation == "right":
input_ids = input_ids[:, :max_length]
attention_mask = attention_mask[:, :max_length]
elif truncation == "middle":
left_half = max_length // 2
right_half = max_length - left_half
input_ids = torch.cat([input_ids[:, :left_half], input_ids[:, -right_half:]], dim=-1)
attention_mask = torch.cat([attention_mask[:, :left_half], attention_mask[:, -right_half:]], dim=-1)
elif truncation == "error":
raise NotImplementedError(f"{sequence_length=} is larger than {max_length=}")
else:
raise NotImplementedError(f"Unknown truncation method {truncation}")
return input_ids, attention_mask根据传入的不同的截断方式,也有不同的处理。
然后我们再根据pad或者截断后的mask计算position_ids。
接下来的操作主要是为了保存raw_prompt和raw_prompt_ids,raw_prompt是messages进行chat_template之后的变量,最后再将extra_info中的一些信息存入到最终要返回的row_dict中返回。