DataProto
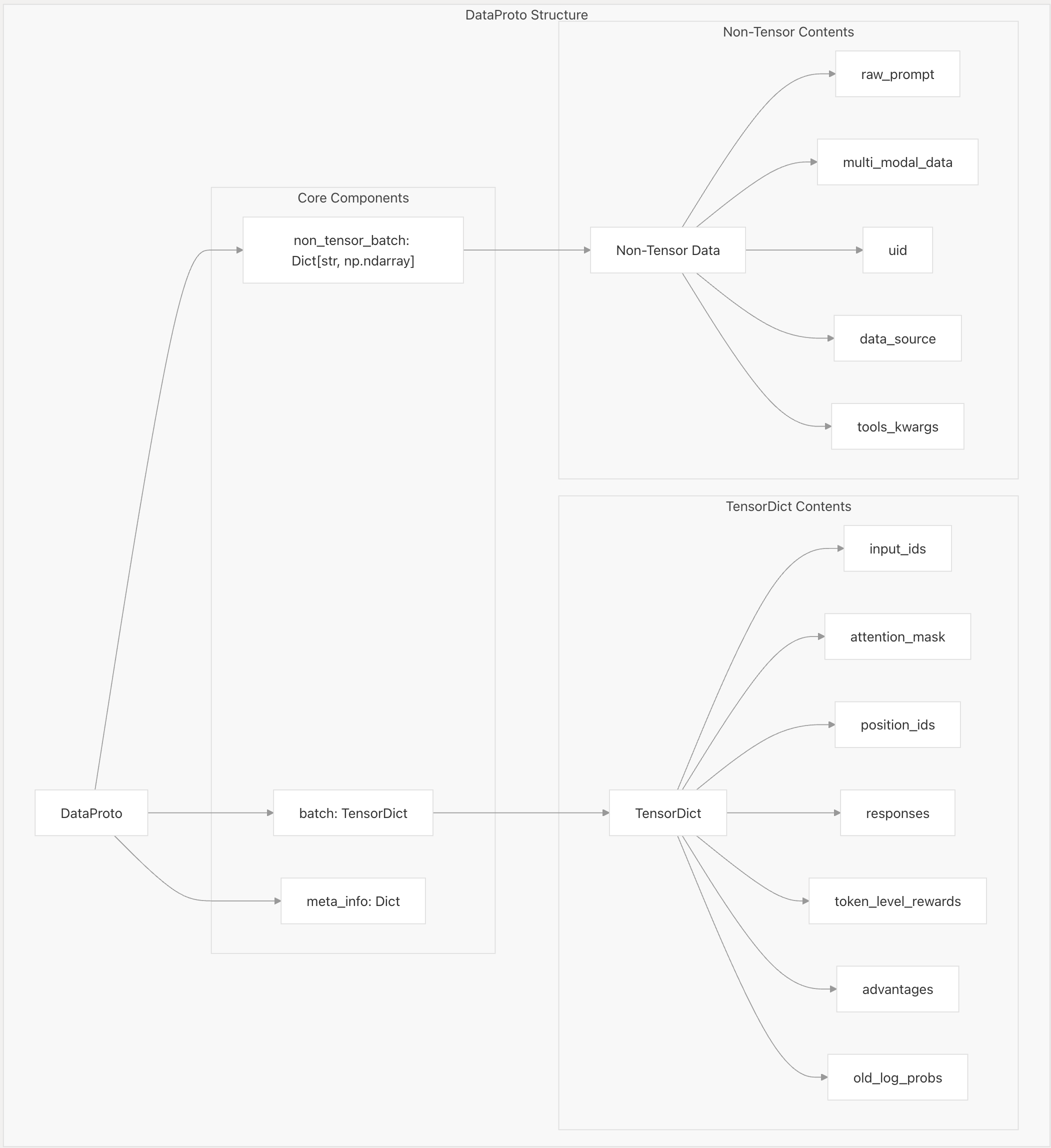
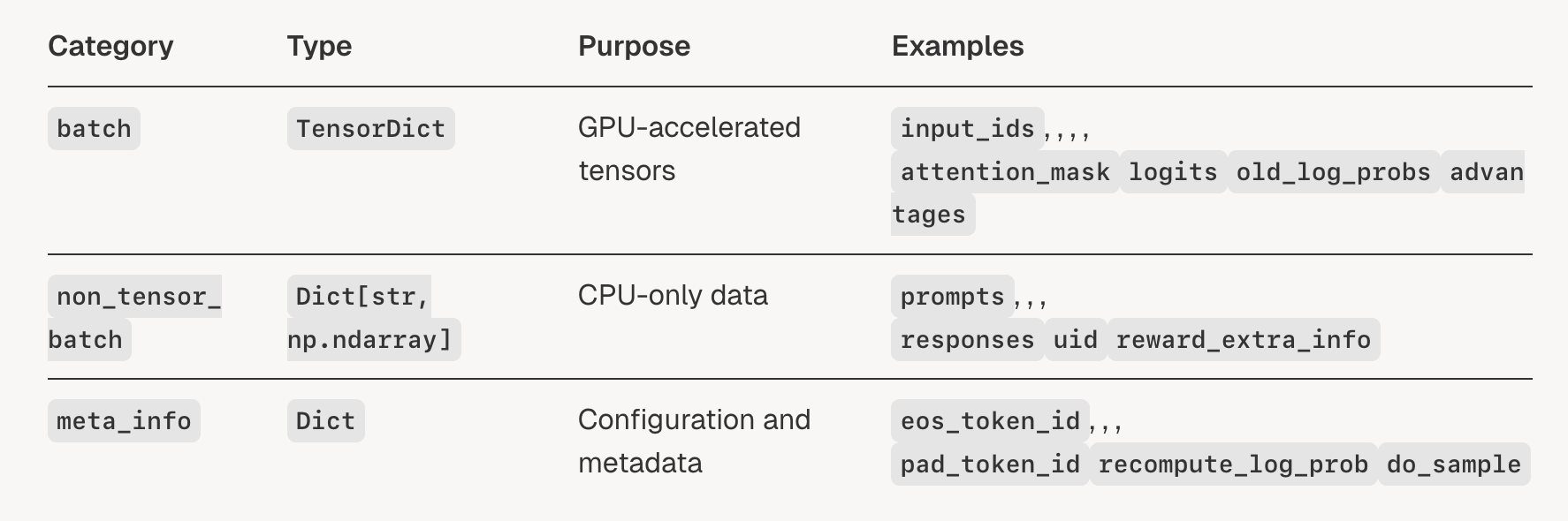
从上图中可以看到DataProto可以分为3个部分: - non_tensor_batch - batch - meta_info 其中non_tensor_batch和meta_info都是个字典,而batch是TensorDict类型的变量。
DataProto支持的一些操作如下:
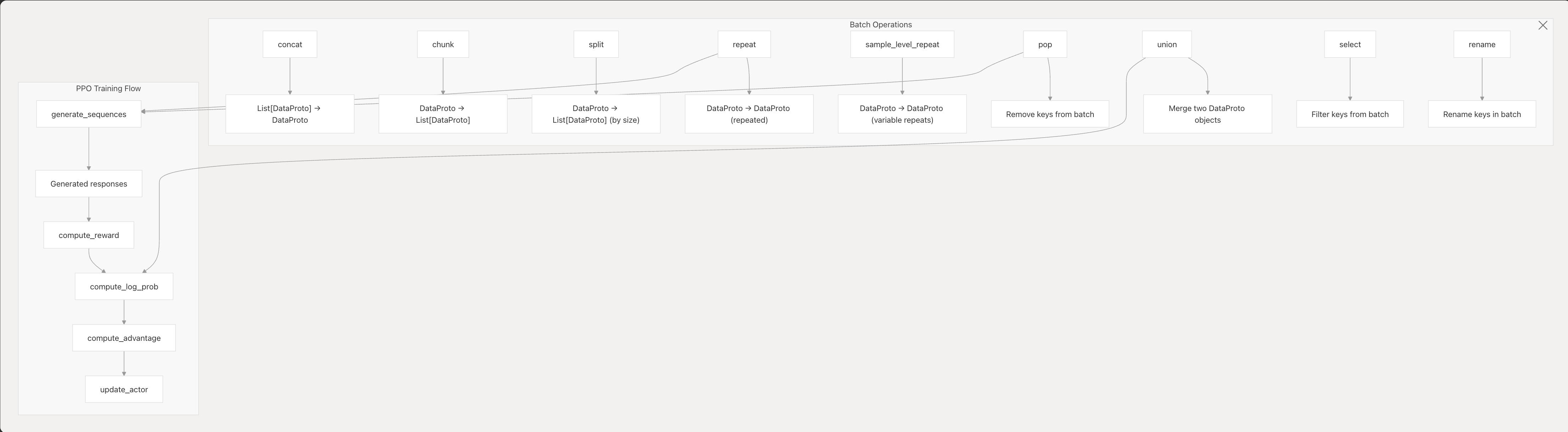 -
- concat: Combines multiple DataProto
objects along the batch dimension - chunk: Splits a
DataProto into equal chunks (requires batch size to be divisible by
chunks) - split: Splits a DataProto into chunks of
specified size (handles uneven splits) - repeat: Repeats
the entire batch a specified number of times -
sample_level_repeat: Repeats each sample a variable number
of times - union: Merges two DataProto objects, combining
their tensors and non-tensors - select/pop:
Filter or remove specific keys from the batch - rename:
Rename keys in the batch
DataProtoConfig
这个设置主要用于管理auto_padding配置,用在dp中,即如果数据批次 / world_size不能整除的话,就需要padding。这部分体现在:
def _split_args_kwargs_data_proto_with_auto_padding(chunks, *args, **kwargs):
from verl.protocol import DataProto, DataProtoFuture
data_proto_len = None
padding_size = None
def _padding_and_split_data(obj, chunks):
nonlocal data_proto_len, padding_size
assert isinstance(obj, DataProto | DataProtoFuture)
if isinstance(obj, DataProto) and obj.is_padding_enabled():
# for padding, we only support DataProto with same length
if data_proto_len is None:
data_proto_len = len(obj)
padding_size = (chunks - (data_proto_len % chunks)) if (data_proto_len % chunks > 0) else 0
else:
assert data_proto_len == len(obj), (
f"expecting all arg share same length of {data_proto_len}, but got {len(obj)}"
)
obj.padding(padding_size=padding_size)
return obj.chunk(chunks=chunks)
splitted_args = [_padding_and_split_data(arg, chunks) for arg in args]
splitted_kwargs = {key: _padding_and_split_data(val, chunks) for key, val in kwargs.items()}
if padding_size is not None:
splitted_kwargs[_padding_size_key] = padding_size
return splitted_args, splitted_kwargs- 计算需要多少个额外的项目才能使批量大小能被目标除数整除
- 从批次的开头获取项以用作填充
- 将原始批次与填充项连接起来
- 跟踪填充大小以供以后删除
DataProtoFuture
DataProtoFuture类用于veRL中的分布式计算
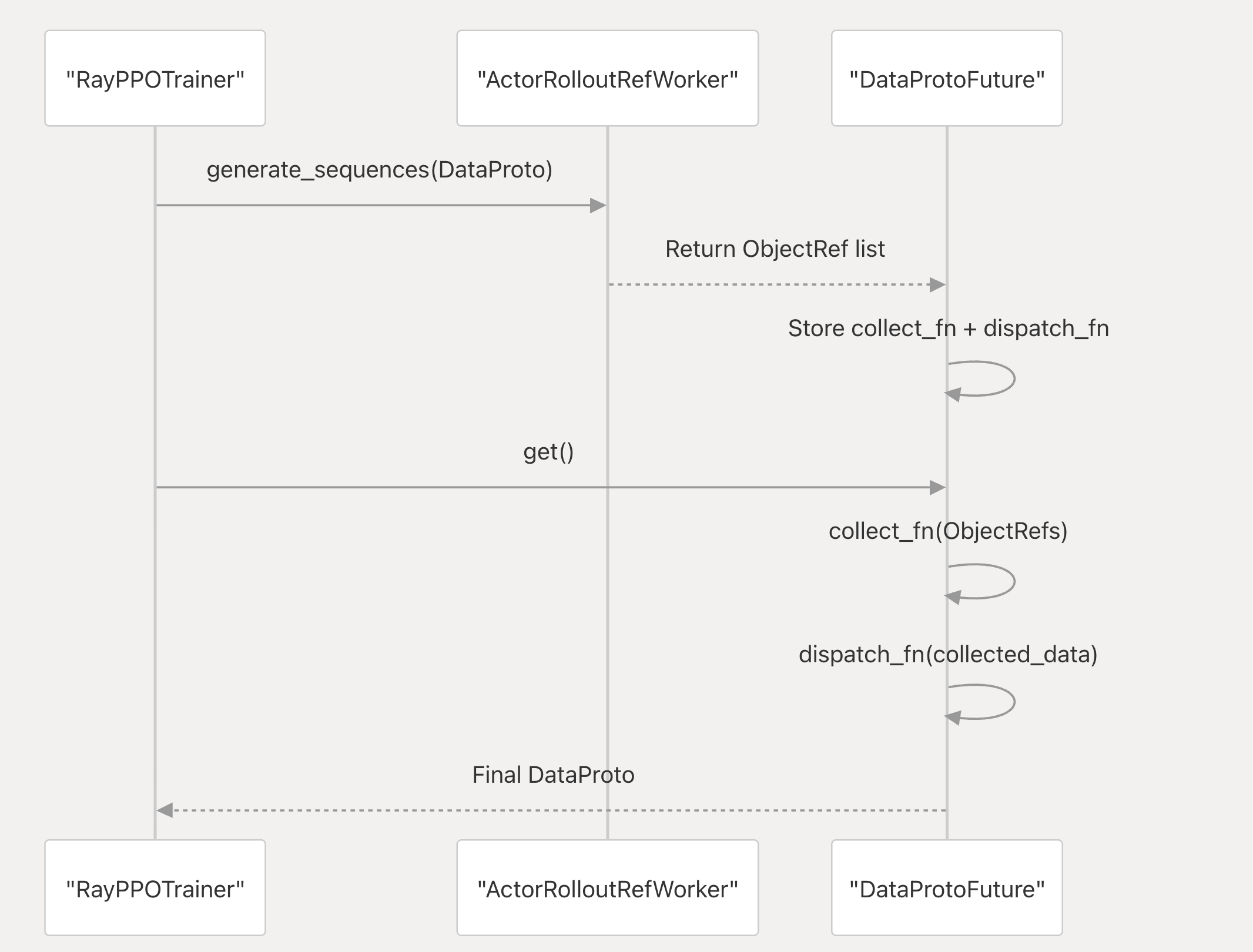
关于collect_fn和dispatch_fn详见init_workers详解
接下来是分布式dataproto的工作流:
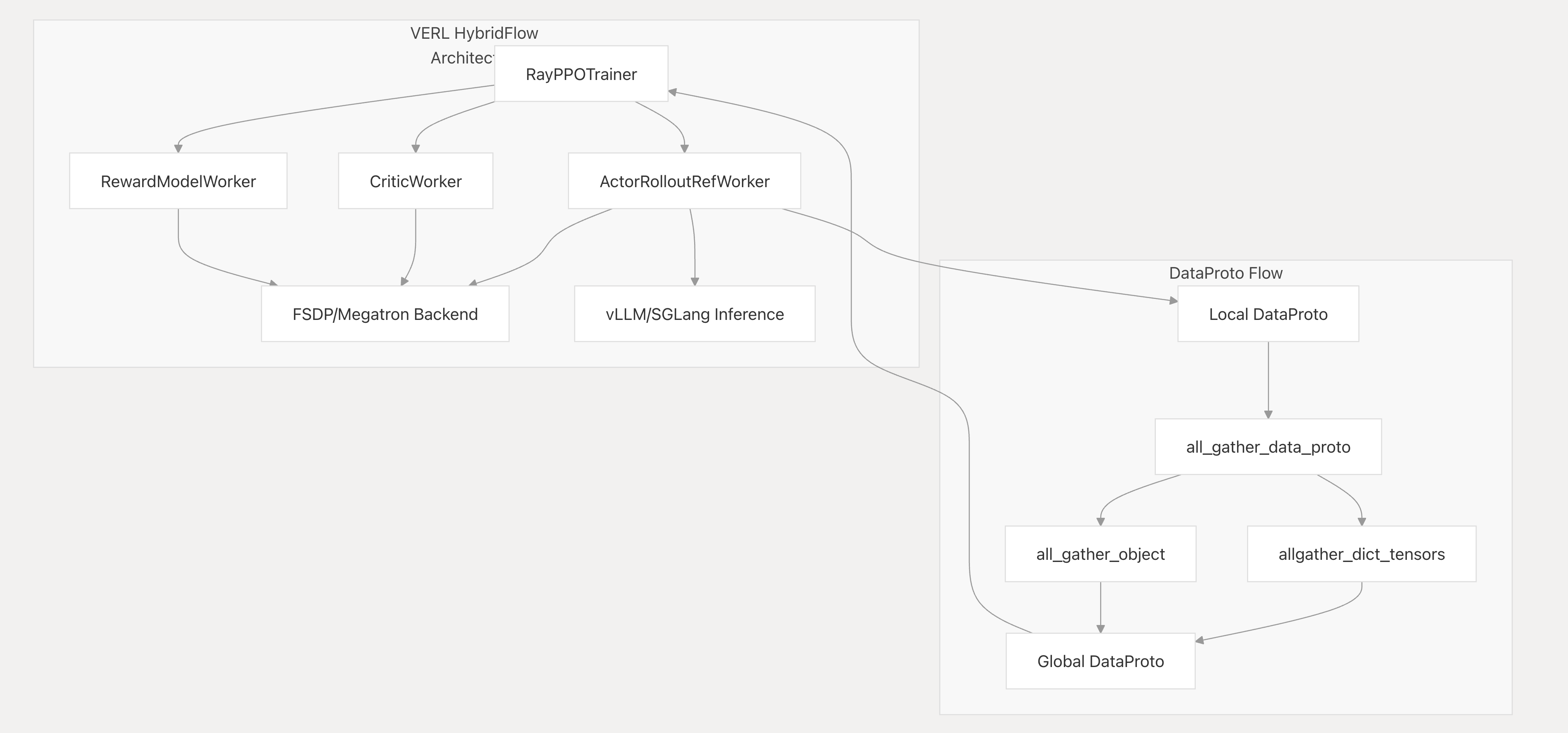
其中all_gather_data_proto函数为:
def all_gather_data_proto(data: DataProto, process_group):
# Note that this is an inplace operator just like torch.distributed.all_gather
group_size = torch.distributed.get_world_size(group=process_group)
assert isinstance(data, DataProto)
prev_device = data.batch.device
data.batch = data.batch.to(get_device_id())
data.batch = allgather_dict_tensors(data.batch.contiguous(), size=group_size, group=process_group, dim=0)
data.batch = data.batch.to(prev_device)
# all gather non_tensor_batch
all_non_tensor_batch = [None for _ in range(group_size)]
torch.distributed.all_gather_object(all_non_tensor_batch, data.non_tensor_batch, group=process_group)
data.non_tensor_batch = {k: np.concatenate([d[k] for d in all_non_tensor_batch]) for k in data.non_tensor_batch}也就是all_gather操作来收集data,主要用于对tp分组上的数据all_gather,因为tp分组需要相同的输入。 >vllm + fsdp 训推时,如果每张卡都是一个 DP,事情会简单很多。但 verl 中有两个功能不满足这一条件,一是 rollout 时让 vllm 开启 TP,二是在 fsdp 中使用 ulysses(SP)。verl 中数据分发使用的是 dispatch mode 这一机制,比如 fsdp workers 主要使用 Dispatch.DP_COMPUTE_PROTO这个 mode,它是在 worker group 的层次上进行数据分发以及结果收集的。由于这个层次是没有 TP/SP 概念的,所以它仅在 one GPU one DP 时才是正确的。那么为了正确支持 TP/SP,就需要对数据做一些前后处理。
(上文引用自浅入理解verl中的batch_size)
体现在ShardingManager中,即:
@GPUMemoryLogger(role="fsdp vllm sharding_manager", logger=logger)
def preprocess_data(self, data: DataProto) -> DataProto:
"""All gather across tp group to make each rank has identical input."""
if self.tp_size == 1:
return data
# TODO: Current impl doesn't consider FSDP with torch micro-dp
group = vllm_ps.get_tensor_model_parallel_group().device_group
all_gather_data_proto(data=data, process_group=group)
return data可见这里获取了tp group,然后在group中进行all_gather操作。post_process_data就是再将数据按照tp分组dispatch出去。在fsdp中需要sp,也有类似的操作。
with self.rollout_sharding_manager:
log_gpu_memory_usage("After entering rollout sharding manager", logger=logger)
prompts = self.rollout_sharding_manager.preprocess_data(prompts)
with simple_timer("generate_sequences", timing_generate):
output = self.rollout.generate_sequences(prompts=prompts)
log_gpu_memory_usage("After rollout generation", logger=logger)
output = self.rollout_sharding_manager.postprocess_data(output)总结:因为我们在进行dispatch的时候,是按照world_size进行的,但是对于tp分组需要相同的输入,所以要进行all_gather。 ## Sequence Balancing
verl中对序列优化的做法有以下几点: - 序列长度平衡:在工作线程之间分配序列以平衡计算工作负载(本章节) - 动态批处理:按令牌计数而不是固定批次大小对序列进行分组(dynamic_bsz) - 序列打包:删除填充标记以提高内存效率remove_padding - 微批次优化:重新排列批次以实现最佳 GPU 利用率
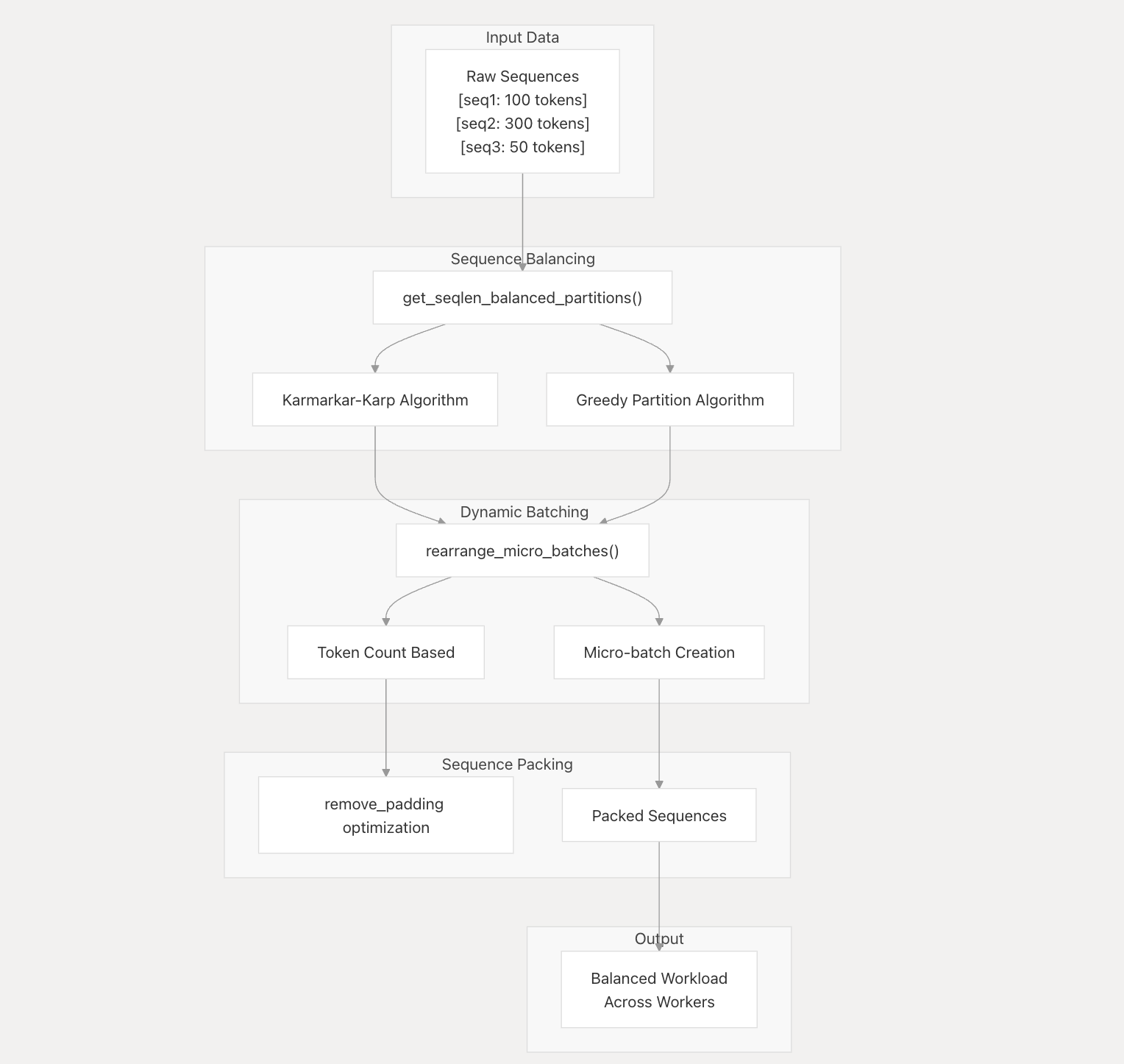
平衡算法:对序列进行分组以最大限度地减少填充,同时尊重标记限制,从而减少填充标记上的计算浪费。
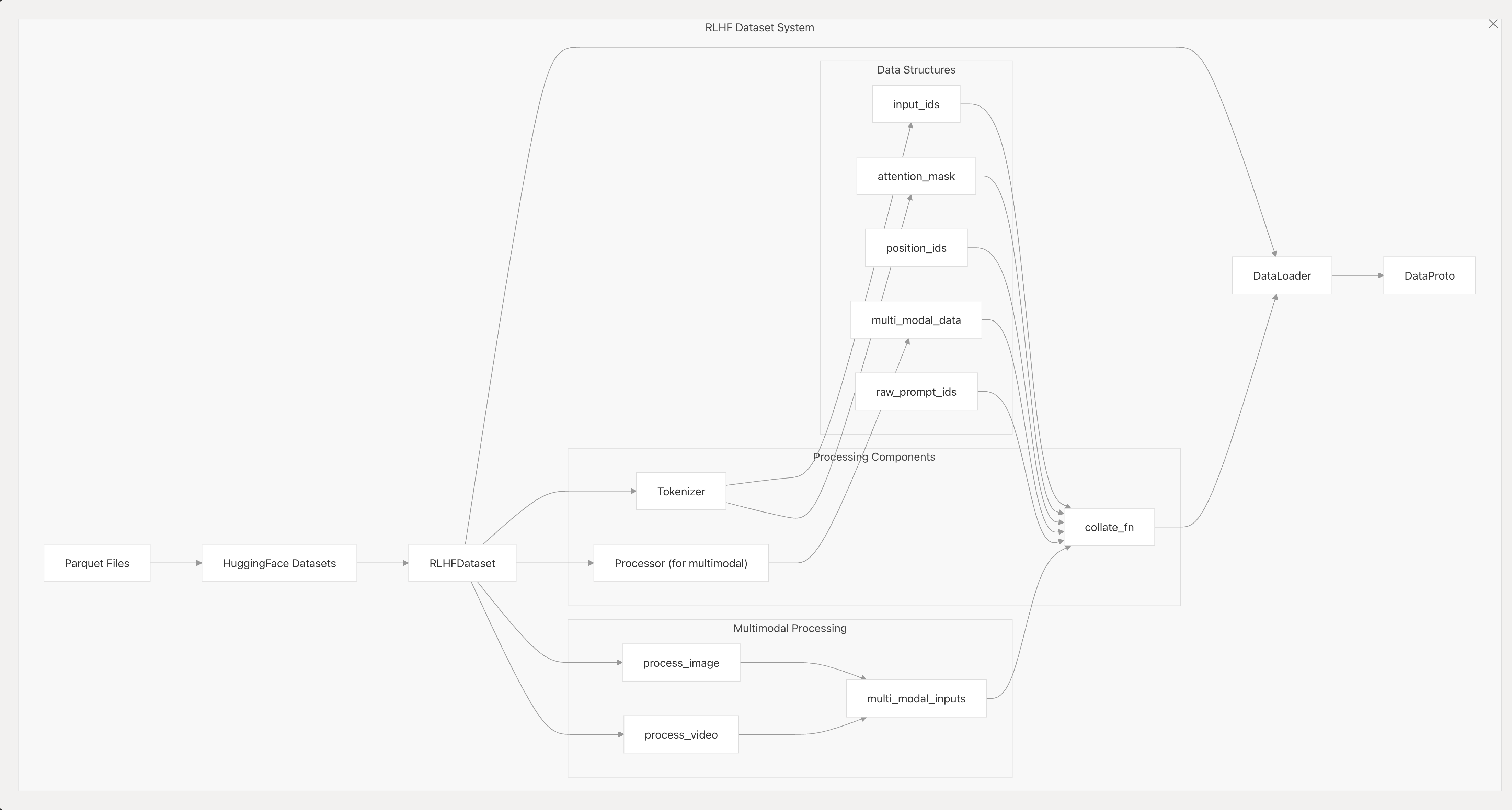
数据处理流程
verl的数据处理流程大概如下图所示: