data_parallel
如果想将模型训练扩展到大的批次,则很快就会达到在单个 GPU
上可以做的极限。具体来说,会发生
RuntimeError: CUDA out of memory。 梯度累计、Activation checkpointing 和 CPU offloading
都可以一定程度上减少显存的占用,为了_有效地_扩展到更大的模型大小和不断增长的数据集,同时仍然在合理的时间内训练模型,我们需要将计算分布在一组机器上。
3 D 并行即:数据并行、张量并行、流水线并行 后两者可以统一划分到模型并行,区别是一个是层内并行,一个是层间并行。
这里介绍数据并行。
Naive data parallel
一个很直觉的做法就是在 batch 维度上进行划分,各个卡上初始化完整的模型,然后将将划分的不同的 batch 发送到各个卡上进行前向传播和反向传播,再由一个卡整合梯度再下发给各 GPU,然后各 GPU 更新自己维护的模型参数。
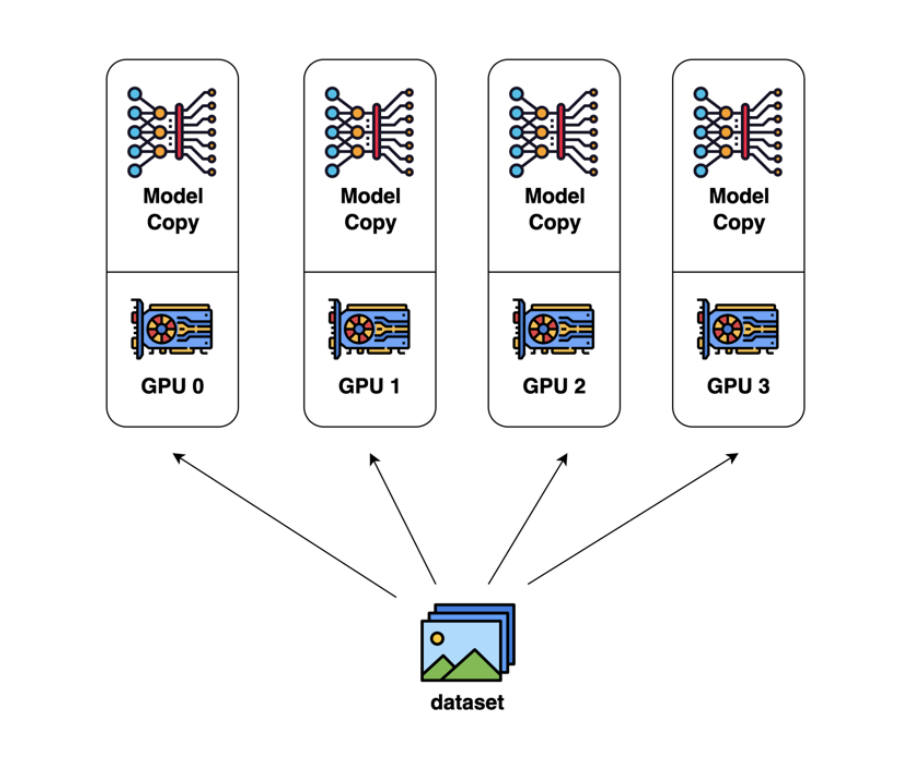
但这种做法显然有很多问题,需要有一个 gpu 担任梯度聚合和下发的角色,如果这个 gpu 出问题了怎么办?每一个 gpu 都需要维护完整的模型参数、梯度和优化器,这部分的显存没有得到减少;此外这种方式通讯量很大,详见显存占用计算
DDP
DDP 解决的问题就是将 Server 上的通讯压力均衡转移到各个 worker 上(Server 即担任梯度聚合和下发的角色,而 worker 就是各个 gpu),因此引入了 ring-all-reduce 算法来解决这个问题。需要把反向传播后的梯度切分成 N(world_size)份来进行 ring-all-reduce 算法。
zero
zero ## fsdp
fsdp ## 参考