dapo
DAPO 是对 GRPO 的改进。DAPO(Decoupled Clip and Dynamic sAmpling Policy Optimization,即解耦裁剪和动态采样策略优化)的优化点有四个(其中前 2 个是主要亮点,是命名的来源)

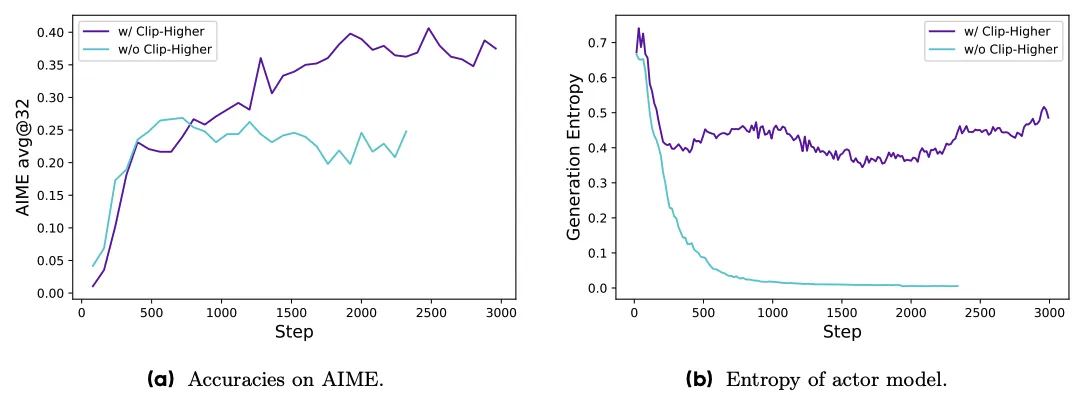
更高裁剪
clip的上边界可以放宽一些,即 clip_high 从 0.2 提高到了 0.28。
传统的PPO算法中,上限裁剪(upper
clip)会限制策略的探索能力。这个问题在低概率的”探索型”token上特别明显,因为这些token的概率提升会被限制在一个严格的范围内。这导致了”熵坍塌”现象,也就是说策略的信息熵下降,采样的响应趋于几个相同的结果,限制了探索。DAPO通过调整上限ehigh裁剪范围来解决这个问题,特别是通过提高ehigh的值,为低概率token的概率提升留出更多空间。实验证明这种方法有效增强了策略的探索性,成功解决了熵坍塌问题。
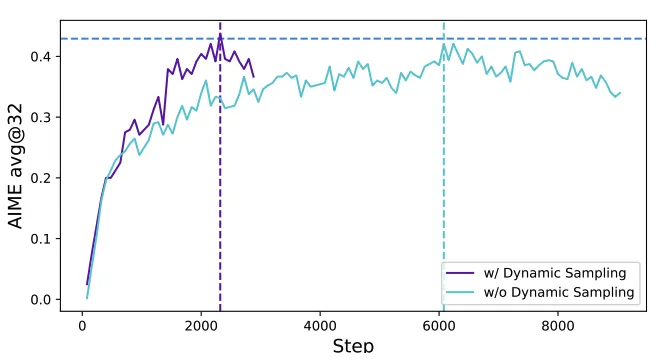
动态采样(Dynamic Sampling)
在现有的RL算法中,如果某些提示的准确率达到1时,会遇到梯度下降的问题。比如在GRPO中,如果一个特定提示的所有输出都是正确的并获得相同的奖励,那么这组数据的优势(advantage)就会变为零。这种情况会导致策略梯度为零,缩小了批次梯度的幅度并增加了噪声敏感性,降低了采样效率。随着训练的进行,准确率为1的样本数量不断增加,这意味着每个批次中有效提示的数量不断减少,导致梯度方差增大并削弱了模型训练的梯度信号。同样地,准确率为0的样本也会导致零梯度问题。DAPO的解决方案是在训练前,采样并过滤准确率为1和0的提示,确保训练批次中有充满准确率既非0也非1的样本。这样可以确保批次中所有的提示都带有有效的梯度信号,保持了批次中有效提示数量的一致性,从而提高了训练效率和稳定性。

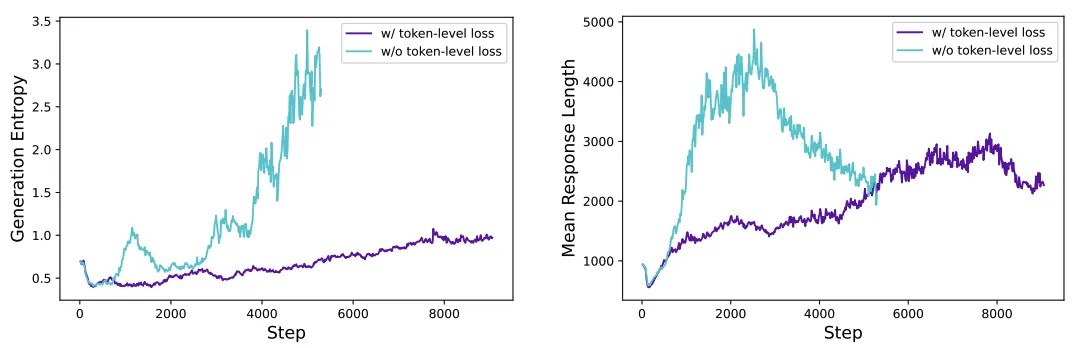
Token 级策略梯度损失(Token-Level Policy Gradient Loss)
这种策略可以使得response length稳步增长,而不是波动大。

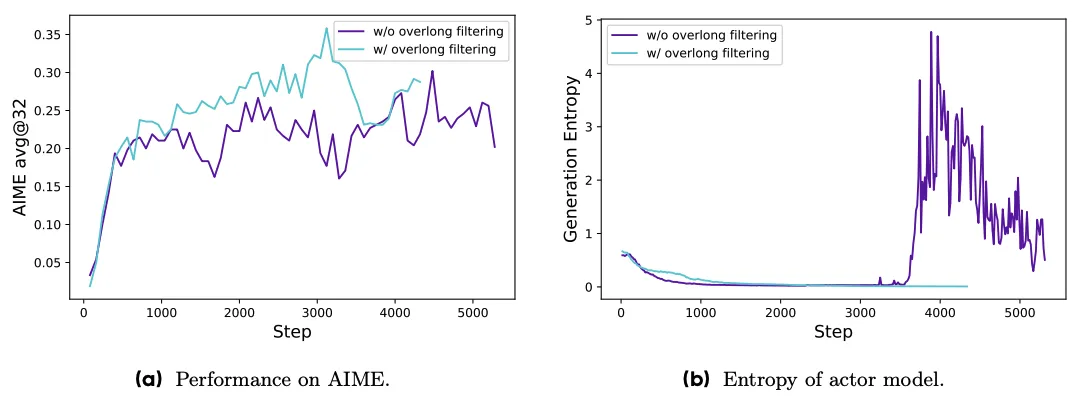
超长奖励塑造(Overlong Reward Shaping)