CoVe
CoVe
Cove代表上下文向量,它是一种有监督的预训练模型,其主要思想就是训练了一个NMT系统,并使用它的编码器,
模型训练
主要假设是,为了翻译一个句子,NMT编码器学会理解句子。 因此来自编码器的向量包含有关单词上下文的信息。
形式上,作者训练了一个带注意力的LSTM模型,比如Bahdanau Model,由于最终我们想使用经过训练的编码器来处理英文句子(不是因为我们只关心英文,而是因为下游任务的大多数数据集都是英文的),所以 NMT 系统必须从英文翻译成其他的语言(例如,德语)。
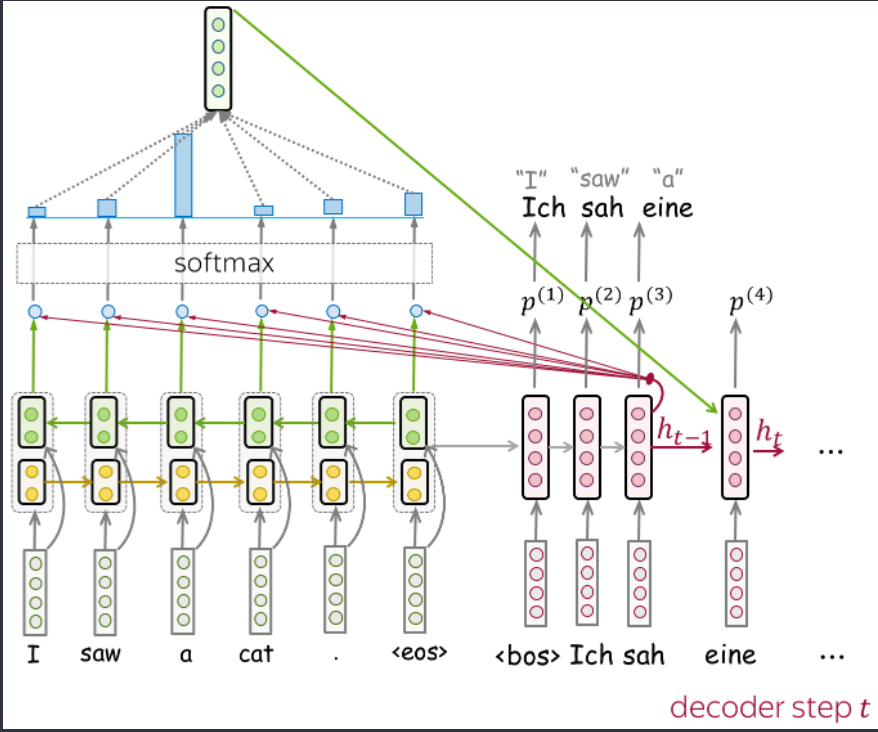
双向编码器
请注意,在这个 NMT 模型中,编码器是双向的:它连接前向和后向 LSTM 的输出。因此,编码器输出包含有关令牌左右上下文的信息。
获取表示(连接 GloVe 和 Cove 向量)
训练 NTM 模型后,我们只需要它的编码器。对于给定的文本,CoVe 向量是编码器的输出。对于下游任务,作者建议使用 Glove(代表单个令牌)和 CoVe(在上下文中编码的令牌)向量的串联。这个想法是这些向量编码不同类型的信息,它们的组合可能很有用。
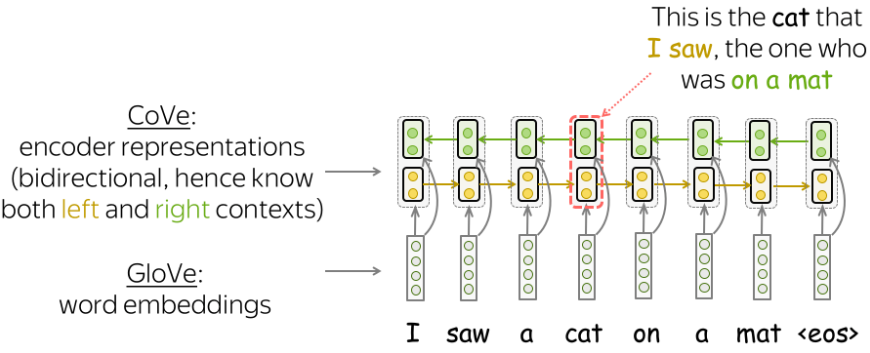

总结
其实思想很简单,就是将已经训练好的机器翻译模型的编码器作为编码,最后再与GloVe进行拼接,可以达到很好的效果,因为使用的是机器翻译模型,因此可以视为有监督学习,有监督的预训练模型是很少的,CoVe就是其中之一,其中更具体的分类可以看本博客的预训练模型。