Can Language Models Serve as Text-Based World Simulators?
这篇论文发表于2024年6月,来自亚利桑那大学、微软研究院、艾伦人工智能研究所等顶尖机构,是一项关于大型语言模型(LLM)能力边界探索的严谨、扎实的量化研究。它并没有提出一个全新的、性能超群的模型,而是像一位严谨的实验物理学家,设计了一套精巧的实验装置,来精确测量并回答一个基础且重要的问题:当前最先进的语言模型,在多大程度上可以取代传统的手工编码,直接作为一个动态世界的“模拟器”?
论文的核心贡献在于,它首次为这个问题提供了定量的答案,而不仅仅是定性的描述或个例的展示。为此,作者们构建了一个全新的基准测试集 BYTESIZED32-State-Prediction (BYTESIZED32-SP),其中包含了超过76,000个从文本游戏中提取的“状态转换”样本。这就像是为语言模型建立了一个“物理实验室”,每一个样本都是一次“实验”,模型需要预测在一个给定的世界状态(State)下,当一个动作(Action)发生后,世界会变成什么新的状态。
为了更精细地剖析模型的能能力,作者们设计了一个巧妙的评估框架。他们将复杂的“世界演化”过程
F 分解为三个关键部分: 1. Fact (Action-driven
transition):由智能体的动作直接引起的状态变化。例如,玩家执行“拿起杯子”的动作,那么杯子就从桌子上转移到了玩家手中。这是对模型理解直接因果关系能力的考验。
2. Fenv (Environment-driven
transition):由环境内在规律驱动的状态变化。例如,玩家打开了水龙头,即使玩家不再做任何动作,水会因为物理规律自动注满水槽里的杯子。这考验的是模型对世界背景知识和物理常识的理解。
3. FR (Game
progress):对游戏进程(如得分、游戏是否结束)的预测。
通过分别测试模型在这三项任务上的表现,论文得以深入洞察模型能力的强项与短板。实验以强大的 GPT-4 模型为主要研究对象,并系统地评估了不同条件下的性能,例如提供由人类专家编写的规则、由LLM自己生成的规则,或者不提供任何规则。
实验结果揭示了深刻的洞见。正如论文在摘要中所言: > We test GPT-4
on this dataset and find that, despite its impressive performance, it is
still an unreliable world simulator without further innovations. >
(我们在这个数据集上测试了GPT-4,发现尽管其性能令人印象深刻,但若无进一步创新,它仍是一个不可靠的世界模拟器。)
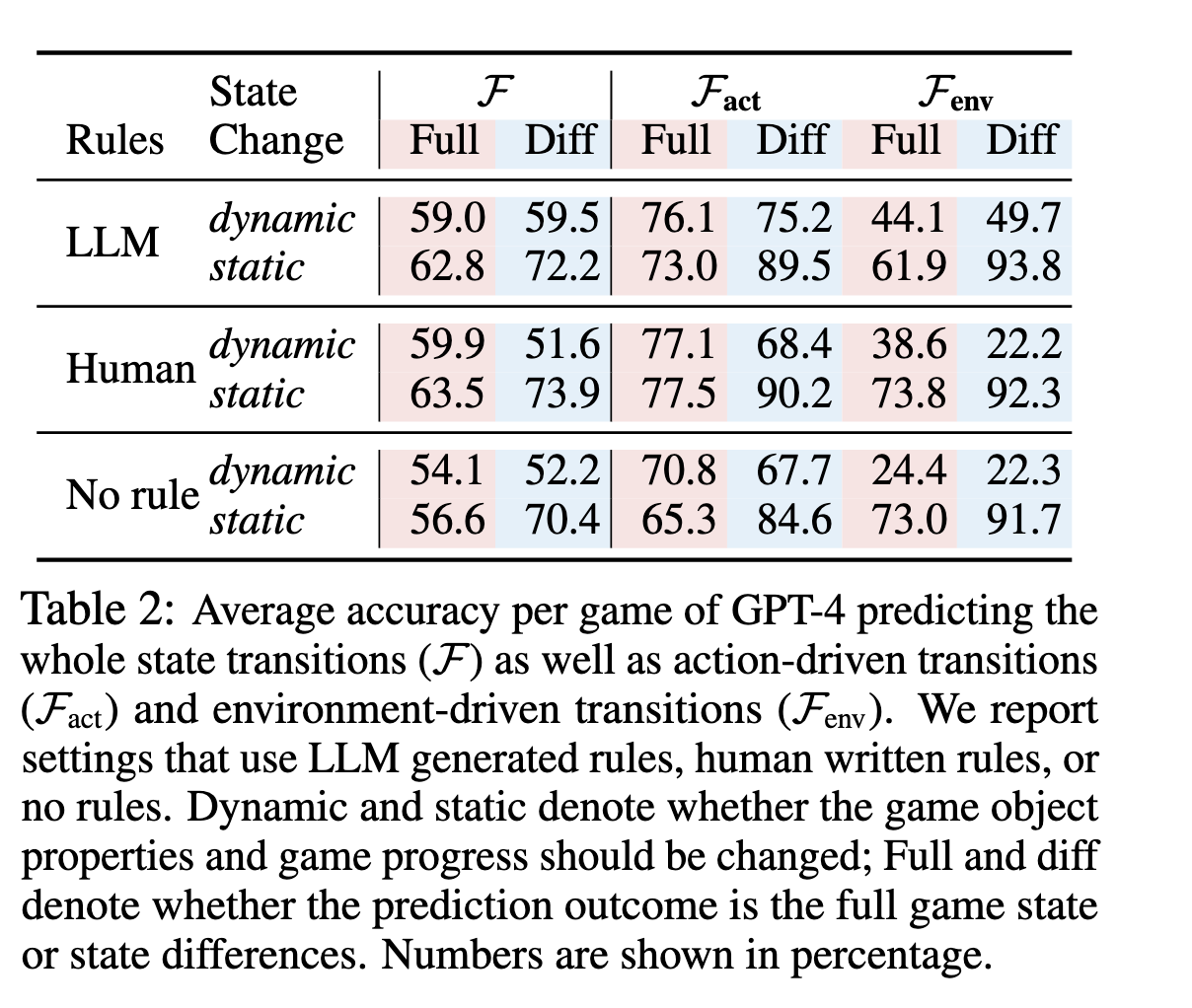 dynamic是指状态发生变化的情况,static是状态没有发生变化的情况。左侧LLM、Human代表制定的不同规则来约束行为。Full是指预测完整的状态转换,而Diff是指预测两个状态的差异。
dynamic是指状态发生变化的情况,static是状态没有发生变化的情况。左侧LLM、Human代表制定的不同规则来约束行为。Full是指预测完整的状态转换,而Diff是指预测两个状态的差异。
具体来说,关键数据(如论文表2所示)表明,GPT-4在模拟由动作直接驱动的转换(Fact)时表现尚可,在有明确规则指导下,对动态变化的预测准确率最高能达到77.1%。然而,一旦涉及到需要理解环境内在规律的转换(Fenv),其准确率便骤降至49.7%。这意味着,模型能够较好地理解“你做了A,就导致B”这种直接指令,但对于“因为A发生了,所以环境中的C会随之发生D”这种间接、隐含的动态,模型的把握能力就差很多。
更有说服力的是,论文进行了细致的错误分析(如图2所示)。分析发现,模型的错误主要集中在那些需要算术(arithmetic)、常识(common-sense)或科学知识(scientific knowledge)的属性上。例如,对于简单的布尔值属性(如“是否开启”),模型预测得很好;但对于需要计算的“温度”变化、需要常识判断的相机“光圈”设置,模型的表现就差强人意。
这引出了论文最核心的结论:单步预测的微小误差会在多步模拟中累积放大,导致模拟结果迅速偏离真实情况。 论文用一个生动的例子阐述了这一点:即使模型在动态变化上的单步最佳准确率为59.9%,在连续模拟10步之后,整体的准确率将下降到 \(0.599^{10}\),即不到1%。这清晰地表明,目前的LLM在作为可靠的世界模拟器方面,还有很长的路要走。
总而言之,这篇论文通过构建新基准、设计精巧的评估框架和进行全面的量化实验,为“LLM作为世界模拟器”这一前沿课题提供了首个系统性的、数据驱动的深刻洞见。它不仅揭示了当前SOTA模型的能力边界,也为未来的研究指明了具体的挑战和方向。
接下来,我将按照您提出的六个问题,逐一进行详细解读。
1. 论文的研究目标是什么? 想要解决什么实际问题?这个问题对于行业发展有什么重要意义?
研究目标:论文的核心研究目标是定量地评估当前的大型语言模型(LLM)在没有任何专门训练的情况下,作为基于文本的虚拟世界模拟器的能力和局限性。它试图回答:LLM能否准确预测在一个给定世界状态下,执行一个动作后,世界将如何演变?
解决的实际问题:该研究旨在解决构建虚拟环境中的一个核心痛点——开发成本高昂且耗时。在AI研究,尤其是强化学习、规划和机器人学领域,研究人员需要大量的、高质量的虚拟环境来训练和测试智能体。传统上,这些环境需要由人类专家花费数周甚至数月的时间手动编码,定义每一个对象、每一个动作及其背后的复杂逻辑。如果LLM能够胜任这项工作,将极大地降低开发门槛,实现“用自然语言描述来即时生成一个可交互的虚拟世界”。
对行业发展的重要意义:
- 加速AI研究:若LLM能成为可靠的模拟器,AI研究者可以快速创建和迭代复杂的测试环境,从而加速在规划、推理和决策等领域的研究进程。
- 变革游戏开发:对于游戏产业,这意味着一种全新的内容生成范式。游戏设计师可以用自然语言来描述游戏世界的规则和动态,快速生成游戏原型,甚至创造出能够动态演化、真正“活”起来的游戏世界,极大地丰富玩家的体验。
- 推动通用人工智能(AGI):构建和理解世界模型(World Models)被认为是通往AGI的关键一步。一个能够准确模拟世界的系统,意味着它在某种程度上理解了世界的运行规律。因此,这项研究也是对LLM作为世界模型潜力的一次基础性探底,其结果对评估我们距离AGI还有多远具有参考价值。
2. 论文提出了哪些新的思路、方法或模型?跟之前的方法相比有什么特点和优势?请尽可能参考论文中的细节进行分析。
这篇论文的创新不在于提出一个新模型,而在于提出了一套新的评估思路和研究框架。
- 新的思路:直接模拟 (Direct Simulation) 的量化评估
- 在本文之前,利用LLM进行世界建模主要有两种思路。一种是神经符号(neurosymbolic)方法,即让LLM生成符号化的代码(如Python程序),然后由确定性的代码执行器来模拟世界。而本文聚焦于第二种思路,也是研究较少的直接模拟,即LLM直接生成下一个世界状态的文本描述(本文中为JSON格式)。
- 特点与优势:这种思路的优势在于其灵活性和通用性,理论上可以模拟任何能用语言描述的动态。而本文的贡献在于,它没有停留在概念层面,而是首次为“直接模拟”这条技术路线建立了一套严谨的量化评估体系,让人们可以清晰地看到它的成效和瓶颈。
- 新的方法与框架:
LLM-Sim 任务的分解框架:如前文所述,将模拟任务
F分解为Fact(动作驱动),Fenv(环境驱动), 和FR(游戏进程) 是本文方法论上的核心创新。 > To better understand LLM’s ability to model each of these transitions, we further decompose the simulator function F into three steps… > (为了更好地理解LLM建模每种转换的能力,我们将模拟器函数F进一步分解为三个步骤…) 优势:这种分解使得分析变得极为精细。如果模型整体表现不佳,我们可以定位到具体是哪个环节出了问题。实验结果也证明了这种分解的价值:LLM在Fact上表现尚可,但在Fenv上表现糟糕,这清晰地指出了模型能力的短板在于对环境内在规律的理解不足。BYTESIZED32-SP 基准数据集:这是一个专门为状态预测任务构建的大规模、高质量数据集。它源自于
BYTESIZED32语料库,包含了31个不同的文本游戏,覆盖了各种常识和初级科学推理概念。 优势:相比于之前依赖于特定游戏或小规模例子的研究,这个大规模数据集保证了评估结果的通用性和鲁棒性,使得出的结论更具说服力。双重预测范式:全状态预测 (Full State) vs. 状态差异预测 (State Difference):论文还测试了两种不同的输出模式。前者要求模型生成完整的下一个状态,后者只要求模型生成发生变化的部分。 优势:这可以用来评估模型输出的简洁性和对“变化”的捕捉能力。有趣的是,实验发现两种范式各有优劣,这为未来如何设计更高效的提示(Prompt)提供了参考。
3. 论文通过什么实验来验证所提出方法的有效性?实验是如何设计的?实验数据和结果如何?请引用关键数据加以说明。
论文的实验设计非常系统和严谨,通过控制变量法,全面地测试了GPT-4在LLM-Sim任务上的表现。
- 实验设计:
- 核心任务:在BYTESIZED32-SP数据集上,给定当前状态
st、动作at和上下文c,预测下一个状态st+1。 - 主要变量:
- 模拟类型:
F(完整模拟),Fact(仅动作驱动),Fenv(仅环境驱动)。 - 规则上下文:提供“人类专家编写的规则”、“LLM生成的规则”或“无规则”。
- 状态变化类型:动态 (Dynamic) (状态发生非平凡变化) vs. 静态 (Static) (状态无变化)。
- 输出格式:全状态预测 vs. 状态差异预测。
- 模拟类型:
- 核心任务:在BYTESIZED32-SP数据集上,给定当前状态
实验数据和结果
关键发现1: - 预测动作直接后果 (Fact) 远比预测环境自发变化 (Fenv) 容易。 - 预测静态转换比动态转换更容易。 - 对于动态状态,预测完整游戏状态比较容易,而预测状态差异则比较容易。这可能是因为状态差异预测旨在减少潜在的格式错误。然而,GPT-4 在大多数情况下能够获得正确的响应格式,而引入状态差异会增加任务输出格式的复杂性。
关键发现2:规则至关重要,但LLM生成的规则已足够好。 * 论文Table
3显示,在预测游戏进程(得分等)时,有规则(LLM生成)的准确率为92.1%,而没有规则时骤降至61.5%。
* 论文Table
2显示,使用LLM生成的规则和人类专家编写的规则,在多数情况下的性能差距很小。这表明LLM在“阅读理解”代码并生成规则方面已经具备了很强的能力。
关键发现3:模型在需要算术、常识和科学推理时更容易出错。 > The errors
are concentrated on non-trivial properties that requires arithmetic
(e.g., temperature, timeAboveMaxTemp),
common-sense (e.g., current_aperture,
current_focus), or scientific knowledge (e.g.,
on).
论文图2的错误分析非常直观,它逐一展示了对不同属性预测的成功率。例如,对isOn(是否开启)这样的简单布尔属性预测得很好,但对temperature(温度)、timeAboveMaxTemp(超过最高温度的时间)等需要计算或物理知识的属性,就会出现大量的“未改变值(unaltered
value)”错误,意味着模型直接忽略了这些复杂的变化。
关键发现4:人类表现远超GPT-4。 在论文Table 4中,研究者选取了一个对GPT-4较难的子集,让模型和人类进行对比。结果显示,人类标注员的平均准确率达到了80%,而GPT-4只有49%,这进一步凸显了当前LLM在可靠性上的差距。
4. 结合大模型领域的当前学术理解,未来在该研究方向上还有哪些值得进一步探索的问题和挑战?这可能催生出什么新的技术和投资机会?
这篇论文为未来的研究打开了一扇门,揭示了诸多挑战与机遇。
- 值得探索的问题和挑战:
- 克服误差累积:这是核心挑战。如何让模拟过程更具鲁棒性?或许可以引入“状态校正”机制,或者让模型进行多步联合预测而非单步预测。
- 混合模拟方法 (Hybrid Simulation):能否将LLM的常识推理能力与传统物理引擎的精确计算能力结合?例如,用LLM处理高层的、基于逻辑和常识的交互,用物理引擎处理底层的、基于数学公式的动态。
- 长时程模拟 (Long-Horizon Simulation):如何让模拟在成千上万个时间步后依然保持真实性?这需要模型具备更强的记忆和对长期因果关系的理解能力。
- 从文本到多模态:如何将这种模拟能力从纯文本扩展到包含图像、声音的多模态世界?
- 模型微调:这篇论文测试的是通用LLM的零样本/少样本能力。如果在一个大规模的“世界状态转换”数据集上对LLM进行专门微调,其性能会有多大提升?
- 可能催生的新技术和投资机会:
- AI原生游戏引擎:可能会出现新一代的游戏引擎,其核心不再是刚性的代码逻辑,而是由一个强大的“世界模型”LLM驱动。开发者只需用自然语言描述规则,引擎即可实时生成和演化游戏世界。这会是一个巨大的投资赛道。
- 自主智能体测试平台:可以投资开发面向企业的、用于训练和测试自主智能体(如自动驾驶、机器人客服、金融交易机器人)的云平台。这些平台利用LLM快速生成各种极端和复杂的模拟场景,大大降低测试成本。
- 教育和培训应用:可以开发基于LLM模拟器的交互式教育软件,例如化学实验模拟、历史事件推演、商业决策培训等,为学习者提供安全且高度动态的虚拟实践环境。
- 专注于“世界模型”的AI公司:未来可能会出现专门致力于训练更大、更强、更可靠的世界模型的AI公司,它们提供的不是通用的聊天机器人,而是作为各种应用(游戏、仿真、机器人)“世界观”基座的核心AI能力。
5. 退一步,从批判的视角看,这篇论文还存在哪些不足及缺失?又有哪些需要进一步验证和存疑的?
尽管这篇论文非常出色,但从批判的角度看,仍然存在一些可以探讨的局限性:
- 模型范围有限:研究主要集中在GPT-4和GPT-3.5上。业界还有其他强大的闭源模型(如Anthropic的Claude系列)和开源模型(如Llama系列、Mistral系列),它们可能有不同的能力画像。将评估范围扩大到更多模型,会使结论更具普适性。
- 数据表征的局限性:实验严重依赖于结构化的JSON格式来表示世界状态。这在很大程度上简化了任务,为模型提供了清晰的“脚手架”。但在更真实的场景中,世界状态可能是以非结构化的自然语言段落来描述的。模型在处理纯文本描述时的模拟能力如何,是一个有待验证的问题。JSON格式可能掩盖了模型在信息提取和结构化理解方面的一些弱点。
- 任务领域的局限性: > Finally, the state spaces produced in this work are focused around the domain of common-sense and early (elementary) scientific reasoning. 论文坦诚,其任务主要围绕常识和初级科学推理。对于需要高度专业化知识的领域(如医学模拟、法律案件推演、金融市场动态),LLM的表现如何还是一个未知数。
- 单步预测的评估模式:论文的评估是基于单步预测的准确性,然后推断多步模拟的误差累积。虽然这个推断是合理的,但缺乏一个真正的、端到端的多步模拟评测。在多步模拟中,模型是否有可能“自我纠错”,或者误差的累积模式是否比指数爆炸更复杂?这需要进一步的实验验证。
- 提示工程的探索不足:论文采用了固定的少样本提示(few-shot prompt)格式。不同的提示策略(如思维链CoT、自我修正等)可能会对结果产生显著影响。探索更优的提示策略可能会进一步解锁模型的模拟潜力。
6. 我希望从这篇论文中找一些拿来即用的创新想法,我应该从这篇论文中重点学什么?有哪些启发?你认为我还需要补充了解哪些背景知识?
这篇论文对于任何希望利用LLM解决复杂问题的人来说,都充满了宝贵的启发。
- 重点学习与启发:
- 分解问题的力量 (The Power of
Decomposition):这是最核心的启发。当面对一个宏大而复杂的任务时(如“模拟世界”),尝试将其分解为更小、更明确、可独立评估的子任务(如
Fact和Fenv)。这种思想不仅适用于学术研究,也适用于工程实践。在你的工作中,当你试图让LLM完成一个复杂流程时,问问自己:这个流程能被分解成哪些关键步骤?LLM在哪个步骤上最可能失败? - 化隐性为显性 (Making the Implicit Explicit):论文证明,提供明确的“规则”能极大地提升LLM的性能。这给我们的实践启示是:不要过于相信LLM的“常识”。在应用中,尽可能将任务的背景知识、约束条件、操作规则以清晰的文本形式提供给模型。这是一种非常实用和高效的提示工程策略。
- 从错误中学习:进行细粒度的失败分析:不要只满足于一个总体的准确率分数。像论文作者一样,深入分析模型的失败案例。搞清楚模型究竟是在“算不对数”,还是“记不住事实”,还是“无法进行逻辑推理”。这种细粒度的分析能帮你找到提升模型性能的最有效途径。
- 建立量化评估基准:在你自己的项目中,思考如何为你的LLM应用建立一个可重复、可量化的评估基准。这能帮助你客观地衡量不同模型、不同提示策略的优劣,避免凭感觉做判断。
- 分解问题的力量 (The Power of
Decomposition):这是最核心的启发。当面对一个宏大而复杂的任务时(如“模拟世界”),尝试将其分解为更小、更明确、可独立评估的子任务(如
- 需要补充的背景知识:
- POMDPs (部分可观察马尔可夫决策过程):这是论文用来形式化定义文本游戏环境的理论框架。了解其基本概念(状态、动作、转移函数、奖励、观测)有助于你理解AI领域对交互式环境的标准描述方式。
- 神经符号AI (Neuro-Symbolic AI):了解这一与“直接模拟”并列的技术路线。它主张将神经网络的模式识别能力与符号系统的逻辑推理能力结合,是当前AI研究的一个热点。
- 世界模型 (World Models):深入了解“世界模型”的概念及其在强化学习和机器人学中的应用。这可以帮助你理解“模拟器”在更宏大的AI图景中所处的位置。
- 文本冒险游戏 (Text-Based Adventure Games):了解像《Zork》或现代的《AI Dungeon》这类游戏的机制,可以让你对论文所研究的问题域有更直观的感受。