BERT
Bert
BERT 的模型架构非常简单,你已经知道它是如何工作的:它只是 Transformer 的编码器。新的是训练目标和 BERT 用于下游任务的方式。
我们如何使用纯文本训练(双向)编码器?我们只知道从左到右的语言建模目标,但它仅适用于每个标记只能使用以前的标记(并且看不到未来)的解码器。BERT 的作者提出了其他未标记数据的训练目标。在讨论它们之前,让我们先看看 BERT 作为 Transformer 编码器的输入。
训练输入:带有特殊标记的句子对
在训练中,BERT 看到用特殊的标记分隔符 [SEP] 分隔的句子对。为了让模型轻松区分这些句子,除了标记和位置嵌入之外,它还使用了段嵌入。
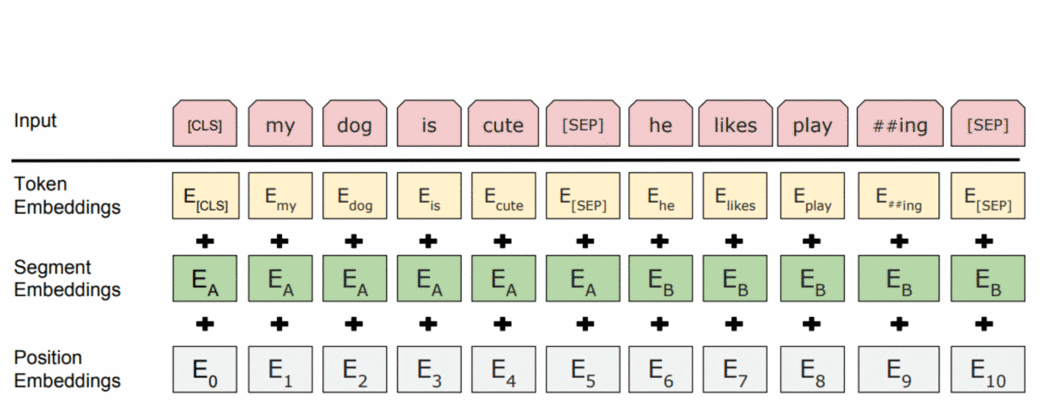
另一个特殊标记是 [CLS] 。顾名思义,它就是表示整个句子的类别的token。在训练中,它用于我们接下来会看到的 NSP 目标。一旦模型被训练,它就会被用于下游任务。
预训练目标:NSP
Next Sentence Prediction (NSP) 目标是一个二元分类任务。根据特殊标记[CLS] 的最后一层表示 ,该模型预测这两个句子是否是某些文本中的连续句子。
输入: [CLS] 这个人去了 [MASK] 商店 [SEP] 他买了一加仑 [MASK]
牛奶 [SEP]
标签: isNext
输入: [CLS] 男子去了 [MASK] 商店 [SEP] 企鹅 [MASK]
正在飞行##less 鸟 [SEP]
标签: notNext
该任务教模型理解句子之间的关系。正如我们稍后将看到的,这将使 BERT 能够用于需要某种推理的复杂任务。
预训练目标:MLM(掩蔽语言模型)
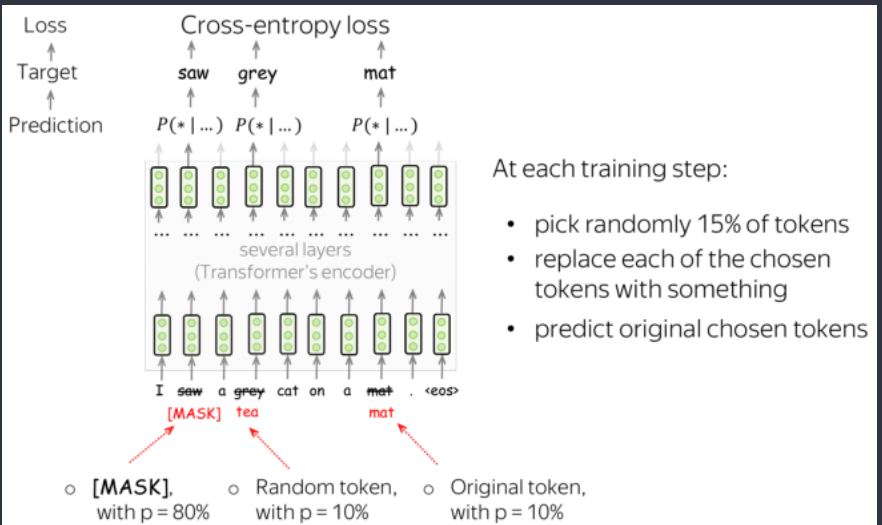
BERT 有两个训练目标,其中最重要的是 Masked Language Modeling (MLM) 目标。对于 MLM 目标,在步骤中会发生以下情况:
- 选择一些标记 (每个标记以 15% 的概率被选中)
- 替换这些选定的标记
(使用特殊标记 [MASK] (p=80%),随机标记 (p=10%),原始标记(保持不变)(p=10%)) - 预测原始标记(计算损失)
 其思想来自于完形填空,也借鉴了CBOW的思想。 MLM
仍然是语言建模:目标是根据文本的某些部分预测句子/文本中的一些标记。为了更清楚,让我们将
MLM 与标准的从左到右的语言建模目标进行比较
其思想来自于完形填空,也借鉴了CBOW的思想。 MLM
仍然是语言建模:目标是根据文本的某些部分预测句子/文本中的一些标记。为了更清楚,让我们将
MLM 与标准的从左到右的语言建模目标进行比较
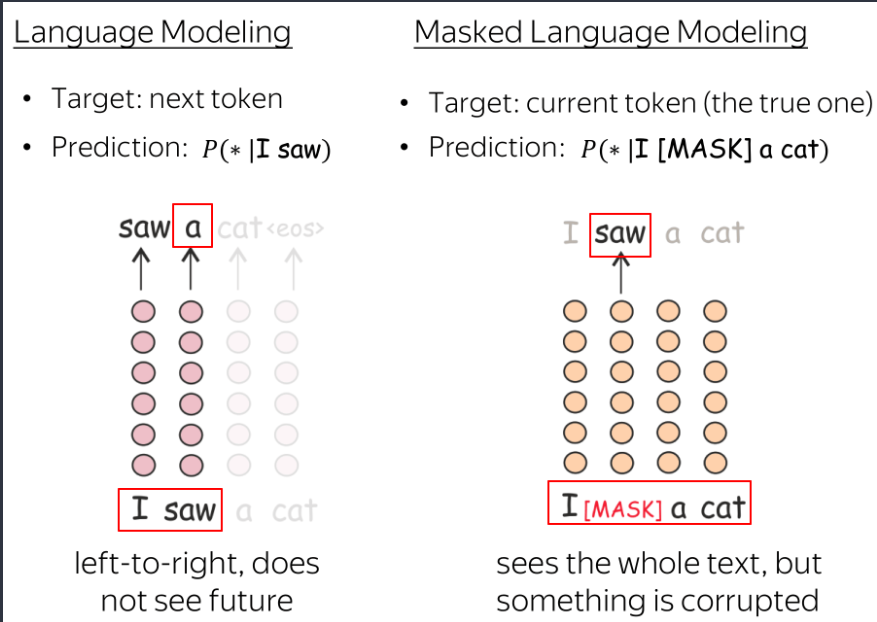
在每一步,标准的从左到右的 LMs 根据之前的标记预测下一个标记。这意味着最终表示,即来自最终层的用于预测的表示,仅编码先前的上下文,即它们 看不到未来。
不同的是,MLM可以一次看到整个文本,但有些标记被破坏了:这就是 BERT 是双向的原因。请注意,为了让 ELMo 知道左右上下文,作者必须训练两个不同的单向 LM(即双向LSTM),然后将它们的表示连接起来。在 BERT 中,我们不需要这样做:一个模型就足够了。
注意一些细节,在代码实现的时候,注意特殊的标记如[SEP][CLS] 等不要替换, 还有[PAD]
数据集构建代码
class BERTDataset(Dataset):
def __init__(self, corpus_path, vocab, seq_len, encoding="utf-8", corpus_lines=None, on_memory=True):
self.vocab = vocab
self.seq_len = seq_len
self.on_memory = on_memory
self.corpus_lines = corpus_lines
self.corpus_path = corpus_path
self.encoding = encoding
with open(corpus_path, "r", encoding=encoding) as f:
if self.corpus_lines is None and not on_memory:
for _ in tqdm.tqdm(f, desc="Loading Dataset", total=corpus_lines):
self.corpus_lines += 1
if on_memory:
self.lines = [line[:-1].split("\t")
for line in tqdm.tqdm(f, desc="Loading Dataset", total=corpus_lines)] # 一行有两个句子,分隔符是\t
self.corpus_lines = len(self.lines)
if not on_memory:
self.file = open(corpus_path, "r", encoding=encoding)
self.random_file = open(corpus_path, "r", encoding=encoding)
for _ in range(random.randint(self.corpus_lines if self.corpus_lines < 1000 else 1000)):
self.random_file.__next__()
def __len__(self):
return self.corpus_lines
def __getitem__(self, item):
t1, t2, is_next_label = self.random_sent(item) # is_next_label: 1 or 0,1代表t2是相邻句子,0代表不是相邻句子
t1_random, t1_label = self.random_word(t1) # mlm任务
t2_random, t2_label = self.random_word(t2)
# [CLS] tag = SOS tag, [SEP] tag = EOS tag
t1 = [self.vocab.sos_index] + t1_random + [self.vocab.eos_index]
t2 = t2_random + [self.vocab.eos_index]
t1_label = [self.vocab.pad_index] + t1_label + [self.vocab.pad_index]
t2_label = t2_label + [self.vocab.pad_index]
segment_label = ([1 for _ in range(len(t1))] + [2 for _ in range(len(t2))])[:self.seq_len]
bert_input = (t1 + t2)[:self.seq_len] # 截断
bert_label = (t1_label + t2_label)[:self.seq_len]
padding = [self.vocab.pad_index for _ in range(self.seq_len - len(bert_input))] #pad
bert_input.extend(padding), bert_label.extend(padding), segment_label.extend(padding)
output = {"bert_input": bert_input,
"bert_label": bert_label,
"segment_label": segment_label,
"is_next": is_next_label}
return {key: torch.tensor(value) for key, value in output.items()}
def random_word(self, sentence): # 对sent token进行mask并返回mask后的label
tokens = sentence.split()
output_label = []
for i, token in enumerate(tokens):
prob = random.random()
if prob < 0.15:
prob /= 0.15
# 80% randomly change token to mask token
if prob < 0.8:
tokens[i] = self.vocab.mask_index
# 10% randomly change token to random token
elif prob < 0.9:
tokens[i] = random.randrange(len(self.vocab))
# 10% randomly change token to current token
else:
tokens[i] = self.vocab.stoi.get(token, self.vocab.unk_index)
output_label.append(self.vocab.stoi.get(token, self.vocab.unk_index)) # 被mask掉的token作为label
else:
tokens[i] = self.vocab.stoi.get(token, self.vocab.unk_index)
output_label.append(0) # label为0,这样计算loss时不用考虑,因为可以设置nn.NLLLoss(ignore_index=0)
return tokens, output_label
def random_sent(self, index): # 根据idx选择某对句子并随机返回相邻或不相邻的句子。
t1, t2 = self.get_corpus_line(index)
# output_text, label(isNotNext:0, isNext:1)
if random.random() > 0.5:
return t1, t2, 1
else:
return t1, self.get_random_line(), 0
def get_corpus_line(self, item): # 通过item idx选择某对句子
if self.on_memory:
return self.lines[item][0], self.lines[item][1]
else:
line = self.file.__next__()
if line is None:
self.file.close()
self.file = open(self.corpus_path, "r", encoding=self.encoding)
line = self.file.__next__()
t1, t2 = line[:-1].split("\t")
return t1, t2
def get_random_line(self): # 随机选一行
if self.on_memory:
return self.lines[random.randrange(len(self.lines))][1]
line = self.file.__next__()
if line is None:
self.file.close()
self.file = open(self.corpus_path, "r", encoding=self.encoding)
for _ in range(random.randint(self.corpus_lines if self.corpus_lines < 1000 else 1000)):
self.random_file.__next__()
line = self.random_file.__next__()
return line[:-1].split("\t")[1]微调
分类
对于分类任务直接取第一个[CLS] token的final hidden state,然后加一层权重后softmax输出。
\[ P = softmax(CW^T) \]
其它任务
其它任务需要一些调整 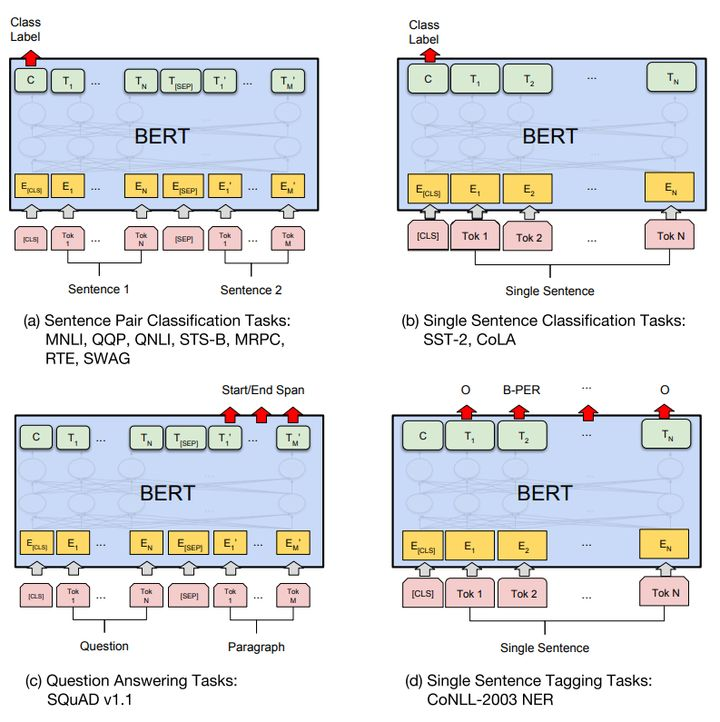
适配器(Adapter)
到目前为止,我们只考虑了将知识从预训练模型(例如 BERT)转移到下游任务的标准方法:微调。“微调”意味着您采用预训练模型并以相当小的学习率训练您感兴趣的任务(例如,情感分类)。这意味着首先,您更新整个(大型)模型,其次,对于每个任务,您需要微调预训练模型的单独副本。最后,对于几个下游任务,您最终会得到很多大型模型 - 这是非常低效的!

Apdater-Bert的想法是将task-specific layer放在预训练模型中间,也就是加入Adapter结构,然后冻结住预训练模型参数,最后我们fientuning的时候,只更新Apdater、layerNorm以及与具体任务相关的layer的参数。具体结构图如下:
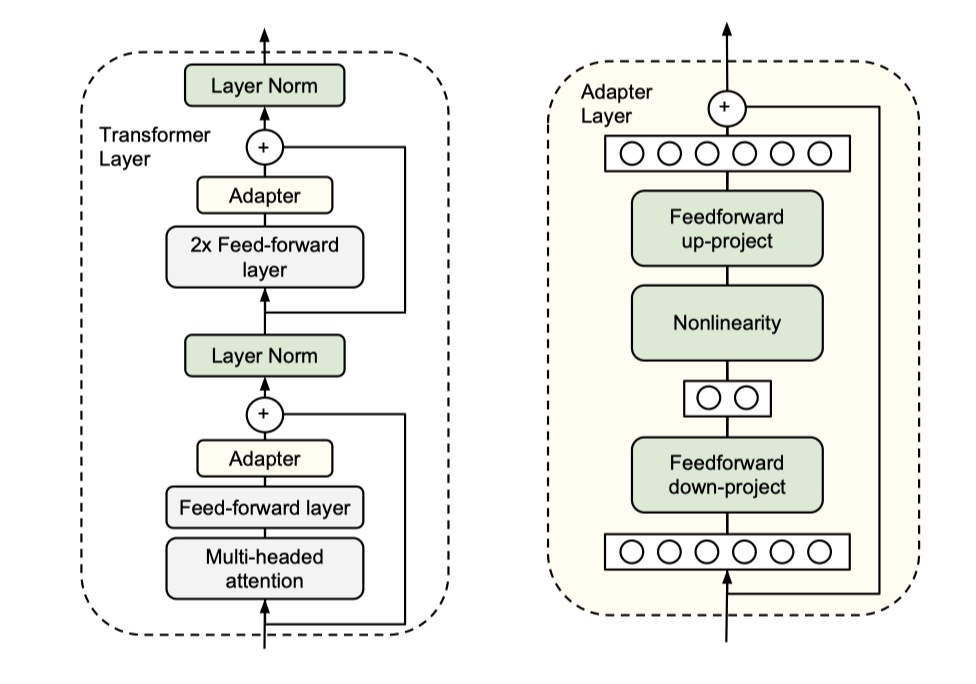
- 左图是Adapter-BERT中的transformer layer,我们可以看到每一个transformer layer增加了两个Adapter layer,分别加在LayerNorm之前,当然了,在进行LayerNorm之前,我们需要进行讲Apdater layer的输出进行残差连接。
- 右图是Adapter layer的具体结构示意 >这里为什么要用残差连接?主要是因为当初始化的时候,权重都很小,残差连接可以保证模型输出与预训练模型相同。
总结
总之BERT就只有这么多新的特性,或者说创新,但是它一经问世就成为了新的霸主,可见效果之好,BERT还有很多细节上的问题,后面看到或者学习到的时候会继续记录下来。 ## 一些问题
为什么 Bert 的三个 Embedding 可以进行相加?
因为三个 embedding 相加等价于三个原始 one-hot 的拼接再经过一个全连接网络。和拼接相比,相加可以节约模型参数。
引用苏建林老师的话: > Embedding的数学本质,就是以one
hot为输入的单层全连接。
也就是说,世界上本没什么Embedding,有的只是one hot。
假设 token Embedding 矩阵维度是 [4,768];position Embedding 矩阵维度是 [3,768];segment Embedding 矩阵维度是 [2,768]。
对于一个字,假设它的 token one-hot 是[1,0,0,0];它的 position one-hot 是[1,0,0];它的 segment one-hot 是[1,0]。
那这个字最后的 word Embedding,就是上面三种 Embedding 的加和。
如此得到的 word Embedding,和concat后的特征:[1,0,0,0,1,0,0,1,0],再过维度为 [4+3+2,768] = [9, 768] 的全连接层,得到的向量其实就是一样的。
transformers中bert模型的输出
