batch_size解释
batch_size的复杂性来自于tp、dp、sp,引用一下浅入理解verl中的batch_size的解释:
vllm + fsdp 训推时,如果每张卡都是一个 DP,事情会简单很多。但 verl 中有两个功能不满足这一条件,一是 rollout 时让 vllm 开启 TP,二是在 fsdp 中使用 ulysses(SP)。verl 中数据分发使用的是 dispatch mode 这一机制,比如 fsdp workers 主要使用
Dispatch.DP_COMPUTE_PROTO这个 mode,它是在 worker group 的层次上进行数据分发以及结果收集的。由于这个层次是没有 TP/SP 概念的,所以它仅在 one GPU one DP 时才是正确的。那么为了正确支持 TP/SP,就需要对数据做一些前后处理。
这一点在DataProto也有提到,具体的实现就是all_gather_data_proto函数。
TP需要在TP rank上all-gather来保证各个tp rank的输入相同,然后再将输出split返回当前rank的部分,保持和输入一致。
SP与 TP 一样,在 SP group 上进行 allgather 来保证各个 SP rank 的输入相同(ulysses 的需要);对输出进行 split 并返回当前 rank 对应的部分。
在fsdp_worker中,初始化阶段对batch_size进行了处理:
# normalize config
if self._is_actor:
self.config.actor.ppo_mini_batch_size *= self.config.rollout.n
self.config.actor.ppo_mini_batch_size //= self.device_mesh.size() // self.ulysses_sequence_parallel_size
assert self.config.actor.ppo_mini_batch_size > 0, (
f"ppo_mini_batch_size {self.config.actor.ppo_mini_batch_size} should be larger than 0 after "
f"normalization"
)
# micro bsz
if self.config.actor.ppo_micro_batch_size is not None:
self.config.actor.ppo_micro_batch_size //= (
self.device_mesh.size() // self.ulysses_sequence_parallel_size
)
self.config.actor.ppo_micro_batch_size_per_gpu = self.config.actor.ppo_micro_batch_size
if self.config.actor.ppo_micro_batch_size_per_gpu is not None:
assert self.config.actor.ppo_mini_batch_size % self.config.actor.ppo_micro_batch_size_per_gpu == 0, (
f"normalized ppo_mini_batch_size {self.config.actor.ppo_mini_batch_size} should be divisible by "
f"ppo_micro_batch_size_per_gpu {self.config.actor.ppo_micro_batch_size_per_gpu}"
)
assert self.config.actor.ppo_mini_batch_size // self.config.actor.ppo_micro_batch_size_per_gpu > 0, (
f"normalized ppo_mini_batch_size {self.config.actor.ppo_mini_batch_size} should be larger than "
f"ppo_micro_batch_size_per_gpu {self.config.actor.ppo_micro_batch_size_per_gpu}"
)
# normalize rollout config
if self._is_rollout and self.config.rollout.log_prob_micro_batch_size is not None:
self.config.rollout.log_prob_micro_batch_size //= (
self.device_mesh.size() // self.ulysses_sequence_parallel_size
)
self.config.rollout.log_prob_micro_batch_size_per_gpu = self.config.rollout.log_prob_micro_batch_size
# normalize ref config
if self._is_ref and self.config.ref.log_prob_micro_batch_size is not None:
self.config.ref.log_prob_micro_batch_size //= self.device_mesh.size() // self.ulysses_sequence_parallel_size
self.config.ref.log_prob_micro_batch_size_per_gpu = self.config.ref.log_prob_micro_batch_size前面创建了fsdp_devicmesh(dp)、ulysses_device_mesh(dp和sp)以及在初始化rollout中创建了rollout_device_mesh(dp和tp)。具体可以查看device_mesh。
Rollout
注意verl v0.5.0的实现中,所有的prompts直接由driver重复然后再dispatch,而不是先dispatch然后再交给Worker重复样本。这样做的目的是如果先分片的话,有可能batch_size小于world_size(对我来说基本不可能),导致不能正确切分,如果是先repeat的话就可以了。
因此对于Rollout: -
全局:train_batch_size * n个prompts,输出train_batch_size * n个prompts
+ responses。 -
单卡:输入train_batch_size * n / world_size个prompts,进行前处理为\(\frac{train\_batch\_size * n}{world\_size} *
tp\_size\)个prompts,然后进行推理,得到\(\frac{train\_batch\_size * n}{world\_size} *
tp\_size\)个prompts+responses,再进行后处理,输出train_batch_size * n / world_size个prompts+responses。
Actor
与Actor有关的参数为ppo_mini_batch_size(决定一批experience的更新次数)、rollout.log_prob_micro_batch_size_per_gpu(计算old_logp)、ref.log_prob_micro_batch_size_per_gpu(计算ref_logp)、micro_batch_size_per_gpu(直接指定单卡上的batch_size)。
重点看ppo_mini_batch_size用于update_policy的处理,其它的都大同小异:
- 全局:
train_batch_size * n大小的batch,包含了部分计算好的experience。 - 单卡:输入为
train_batch_size * n / world_size,经过前处理为train_batch_size * rollout_n * sp_size / world_size。这和fsdp_worker初始化时的ppo_mini_batch_size一致,即
self.config.actor.ppo_mini_batch_size *= self.config.rollout.n
self.config.actor.ppo_mini_batch_size //= self.device_mesh.size() // self.ulysses_sequence_parallel_size这样的话对于一批experience的更新次数,就等于你传入的train_batch_size
//
mini_batch_size。对于micro_batch_size_per_gpu参数来说,可以直接指定单卡的bs。对于传入micro_batch_size再计算的方式,verl已经废弃了。
ppo流程
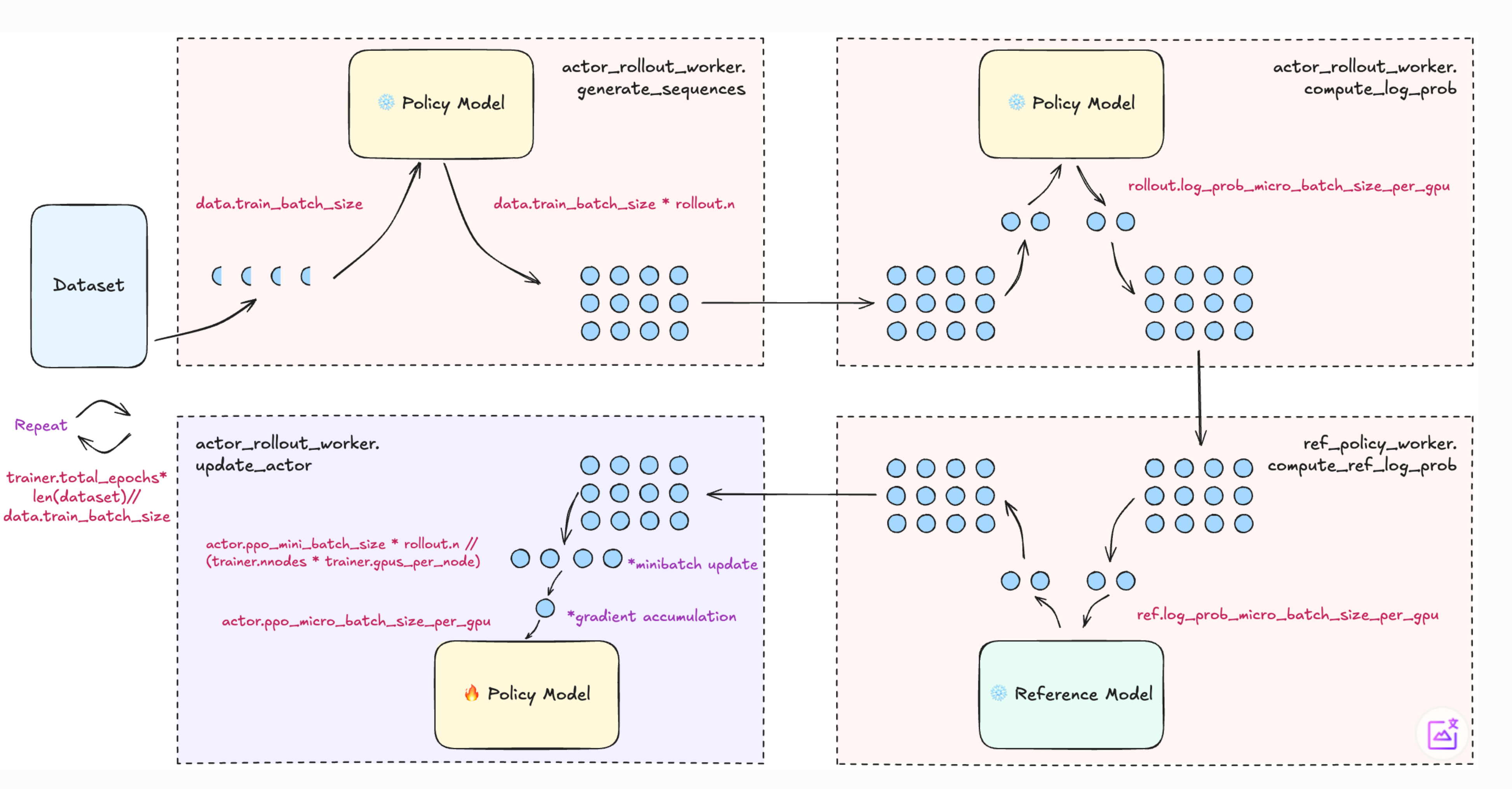 从图中可以得到的是ppo_mini_batch_size是全局的prompt
batch,而ppo_micro_batch_per_gpu是每一个gpu上的prompt+response
batch,所以由此可以得到梯度累计的steps为 ppo_mini_batch_size * n *
sp_size // world_size //
micro_batch_per_gpu。即micro_batch_per_gpu代表梯度累计的bs。
从图中可以得到的是ppo_mini_batch_size是全局的prompt
batch,而ppo_micro_batch_per_gpu是每一个gpu上的prompt+response
batch,所以由此可以得到梯度累计的steps为 ppo_mini_batch_size * n *
sp_size // world_size //
micro_batch_per_gpu。即micro_batch_per_gpu代表梯度累计的bs。