agent_loop
Verl 最近实现了 agent loop 功能,也就是多轮工具调用 RL ,弥补了 verl 中 vllm 无法使用多轮 rollout 的不足。整体流程大致如下(来自 https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/blob/main/rlhf/verl/multi-turn/imgs/Multi-Turn_Rollout_Workflow.png)
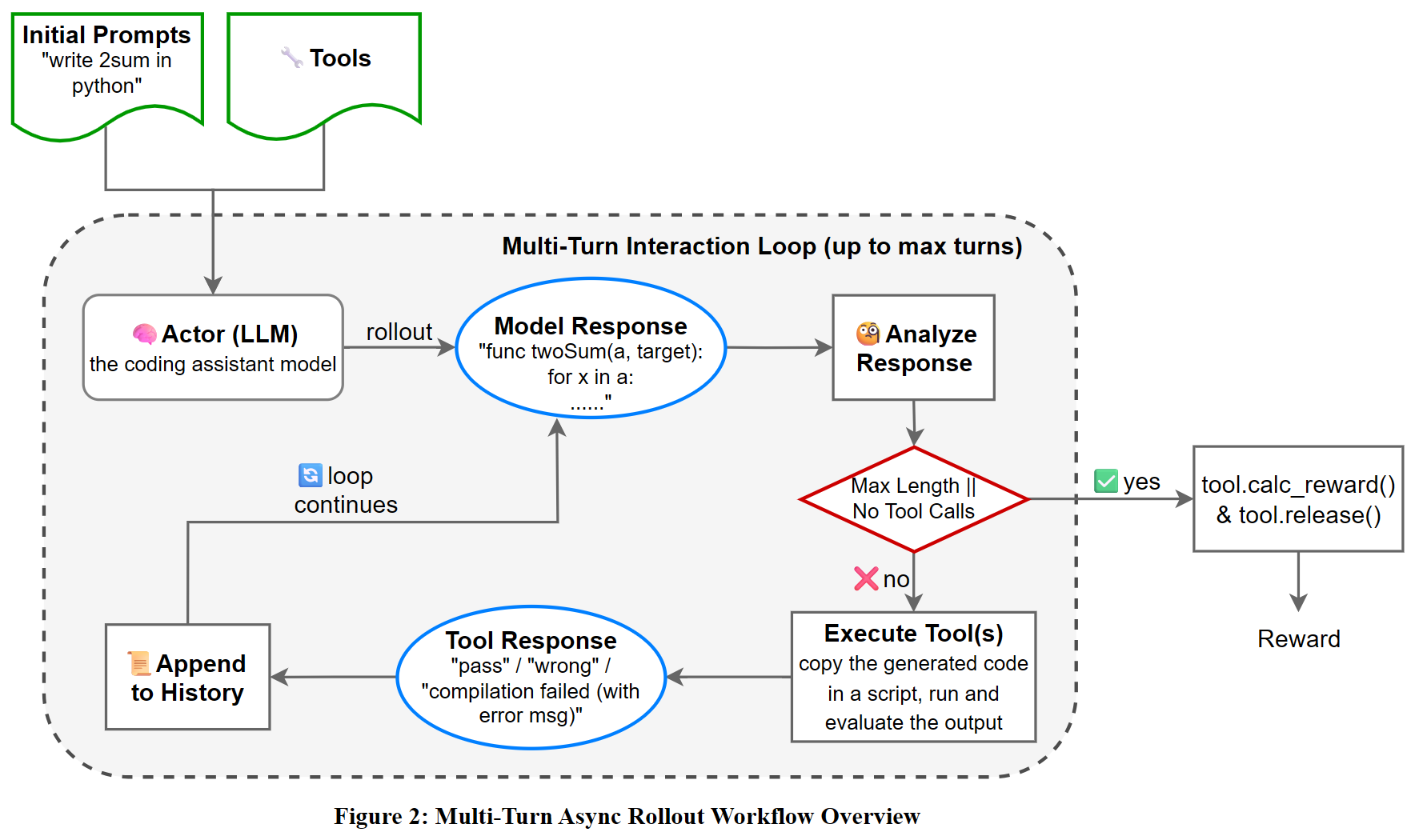
在官方实现中(目前在 verl/experimental/agent_loop 目录下),核心代码在 agent_loop.py中,single_turn_agent_loop.py和tool_agent_loop对应两种agent_loop,tool_parser.py定义了hermes工具解析类。所以重点就是在agent_loop.py中,各个类的协作流程如下图:
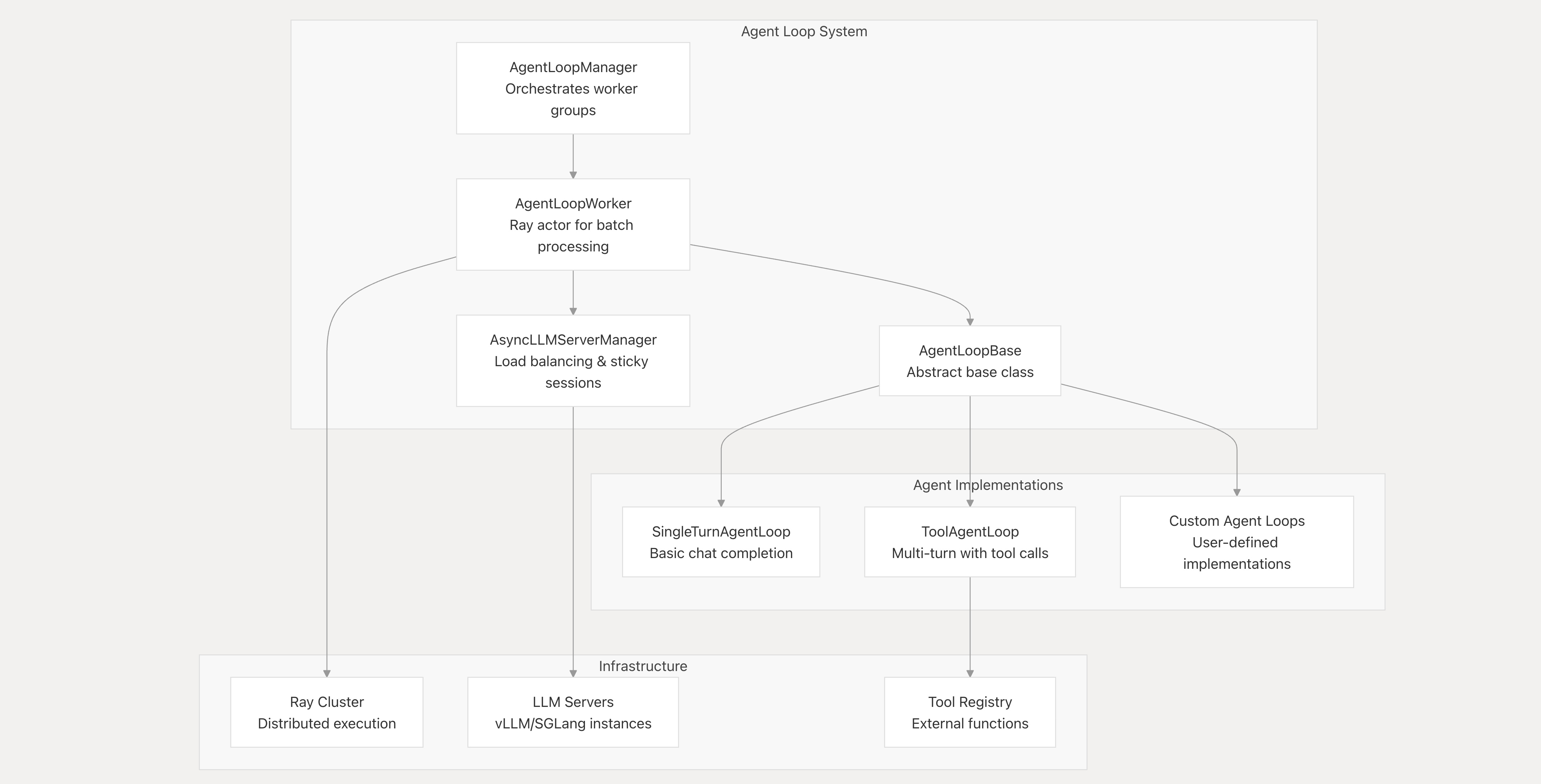
verl官网图如下(Agent
Loop — verl documentation): 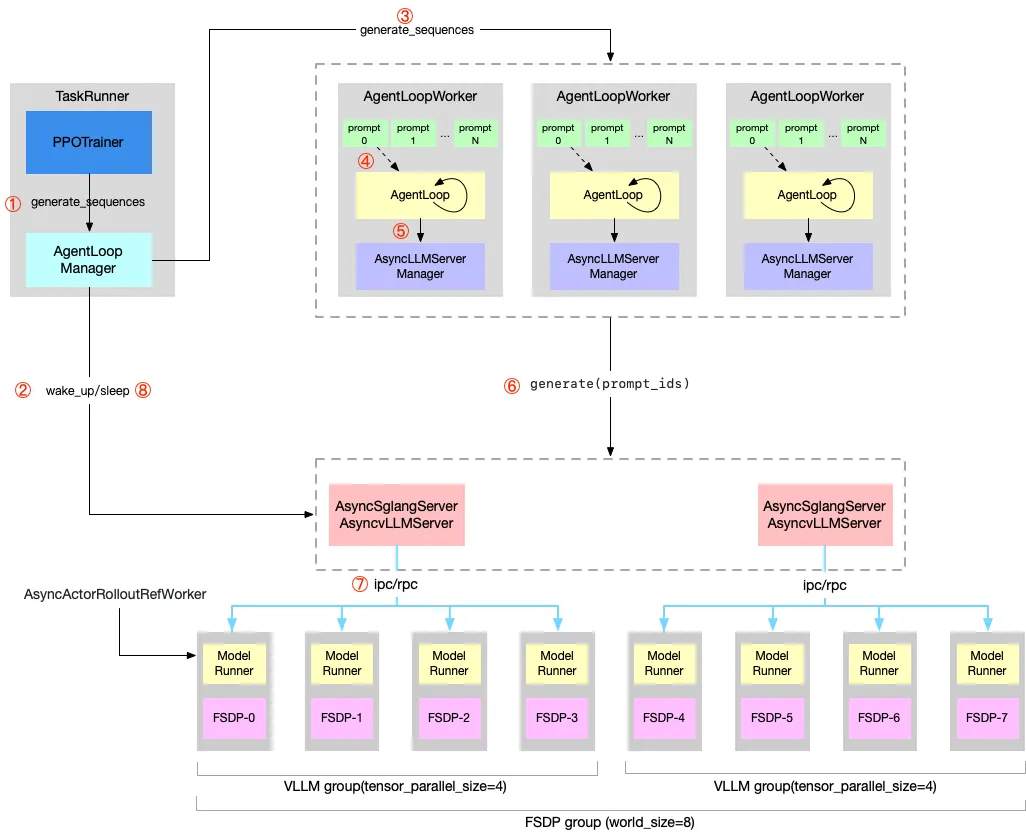
按照上面的流程图进行逐步讲解。
AgentLoopManager
AgentLoopManager是入口处,在ray_trainer.py中由actor_rollout_wg初始化:
if self.config.actor_rollout_ref.rollout.mode == "async":
from verl.experimental.agent_loop import AgentLoopManager
self.async_rollout_mode = True
self.async_rollout_manager = AgentLoopManager(
config=self.config,
worker_group=self.actor_rollout_wg,
)AgentLoopManager需要先启动多个推理引擎服务器,数量为dp_size(world_size/tp_size)。代码:
class AgentLoopManager:
"""Agent loop manager that manages a group of agent loop workers."""
def __init__(self, config: DictConfig, worker_group: RayWorkerGroup):
"""Initialize agent loop manager.
Args:
config (DictConfig): trainer config.
worker_group (RayWorkerGroup): ActorRolloutRef worker group.
"""
self.config = config
self.worker_group = worker_group
self._initialize_llm_servers()
self._init_agent_loop_workers()
def _initialize_llm_servers(self):
# 这里也对应了一开始图中的最下面的部分
self.rollout_tp_size = self.config.actor_rollout_ref.rollout.tensor_model_parallel_size
self.rollout_dp_size = self.worker_group.world_size // self.rollout_tp_size
...
unready_dp_ranks = set(range(self.rollout_dp_size))
while len(unready_dp_ranks) > 0:
servers = {
rollout_dp_rank: server_class.options(
# make sure AsyncvLLMServer colocates with its corresponding workers
scheduling_strategy=ray.util.scheduling_strategies.NodeAffinitySchedulingStrategy(
node_id=workers_info[rollout_dp_rank * self.rollout_tp_size],
soft=False,
),
name=f"async_llm_server_{rollout_dp_rank}",
).remote(self.config, self.rollout_dp_size, rollout_dp_rank, self.worker_group.name_prefix)
for rollout_dp_rank in unready_dp_ranks
}
for rollout_dp_rank, server in servers.items():
try:
address = ray.get(server.get_server_address.remote())
self.server_addresses[rollout_dp_rank] = address
self.async_llm_servers[rollout_dp_rank] = server
unready_dp_ranks.remove(rollout_dp_rank)
except Exception:
ray.kill(server)
print(f"rollout server {rollout_dp_rank} failed, maybe address already in use, restarting...")
# All server instances are ready, init AsyncLLM engine.
ray.get([server.init_engine.remote() for server in self.async_llm_servers])AgentLoopManager负责管理多个AgentLoopWorker,个数由参数rollout.agent.num_workers确定。然后将prompt切分成num_worker个,让各个worker分别进行推理,这部分的代码如下:
## 初始化各个worker
def _init_agent_loop_workers(self):
self.agent_loop_workers = []
for i in range(self.config.actor_rollout_ref.rollout.agent.num_workers):
self.agent_loop_workers.append(
AgentLoopWorker.options(
name=f"agent_loop_worker_{i}",
).remote(self.config, self.async_llm_servers)
)
...
## 根据worker的数量切分prompts,推理后再合并起来
def generate_sequences(self, prompts: DataProto) -> DataProto:
if self.config.actor_rollout_ref.rollout.free_cache_engine:
self.wake_up()
chunkes = prompts.chunk(len(self.agent_loop_workers))
outputs = ray.get(
[
worker.generate_sequences.remote(chunk)
for worker, chunk in zip(self.agent_loop_workers, chunkes, strict=True)
]
)
output = DataProto.concat(outputs)从初始化也说明了,我们在RayPPOTrainer中init_workers方法里面初始化好AgentLoopManager,同时也初始化好了推理服务器和各个workers。 ## AsyncLLMServerManager
在上面的代码中,可以看到我们在创建各个worker的时候传入了初始化好的servers,需要一个类来对这些server进行管理,即AsyncLLMServerManager类。具体的作用就是针对不同的request,来选择哪一个server进行推理,使用LRU算法来进行管理,具体如下:
def __init__(self, config: DictConfig, server_handles: list[ray.actor.ActorHandle], max_cache_size: int = 10000):
"""Initialize the AsyncLLMServerManager.
Args:
config (DictConfig): YAML config.
server_handles (List[ray.actor.ActorHandle]): OpenAI compatible LLM server actor handles.
max_cache_size (int, optional): max cache size for request_id to server mapping. Defaults to 10000.
"""
self.config = config
self.server_handles = server_handles
random.shuffle(self.server_handles)
# Least requests load balancing
self.weighted_serveres = [[0, (hash(server), server)] for server in server_handles]
heapq.heapify(self.weighted_serveres)
# LRU cache to map request_id to server
self.request_id_to_server = LRUCache(maxsize=max_cache_size)
def _choose_server(self, request_id: str) -> ray.actor.ActorHandle:
# TODO: implement server pressure awareness load balancing
if request_id in self.request_id_to_server:
return self.request_id_to_server[request_id]
server = self.weighted_serveres[0][1][1]
self.weighted_serveres[0][0] += 1
heapq.heapreplace(self.weighted_serveres, self.weighted_serveres[0])
self.request_id_to_server[request_id] = server
return server具体做法解释如下: 1.
建立了一个最小堆self.weighted_serveres,列表中的每个元素结构是 [0,
(hash(server), server)],即 [请求计数, (服务器哈希,
服务器句柄)]。heapq.heapify(self.weighted_serveres) 将这个列表转换成一个最小堆,堆的排序依据是每个元素的第一个值,也就是 请求计数。因此,请求数最少的服务器始终位于堆的顶部(self.weighted_serveres[0])。
2. 创建了一个 self.request_id_to_server,这是一个 LRU (Least Recently
Used) 缓存。这个缓存用于存储 request_id 到 server 句柄的映射。 3.
首先检查request_id是否在映射中,如果在的话直接返回对应的服务器句柄,否则需要给它分配一个全新的server,也就是请求计数最少的那个server,然后再更新堆和映射。
这样做的目的是为了各个服务器之间的负载均衡。
实际的生成就是由这个类进行的,即
@rollout_trace_op
async def generate(
self,
request_id,
*,
prompt_ids: list[int],
sampling_params: dict[str, Any],
) -> list[int]:
"""Generate tokens from prompt ids.
Args:
request_id (str): request id for sticky session.
prompt_ids (List[int]): List of prompt token ids.
sampling_params (Dict[str, Any]): Sampling parameters for the chat completion.
Returns:
List[int]: List of generated token ids.
"""
server = self._choose_server(request_id)
output = await server.generate.remote(
request_id=request_id,
prompt_ids=prompt_ids,
sampling_params=sampling_params,
)
return output先选择合适的server,再利用该server的generate方法来进行推理。具体的类和方法在workers/rollout下。
AgentLoopWorker
现在回到AgentLoopWorker中,前面已经提到了,我们用AgentLoopManager管理多个Worker,每一个Worker都可以用所有创建的server进行推理,接下来就看worker的generate_sequcences方法做了什么:
async def generate_sequences(self, batch: DataProto) -> DataProto:
"""Generate sequences from agent loop.
Args:
batch (DataProto): Input batch.
Returns:
DataProto: Output batch.
- prompts: [bsz, prompt_length], prompt token ids from dataset.
- responses: [bsz, response_length], output token ids include response tokens
from LLM generation and observation tokens from tool_calls.
- response_mask: [bsz, response_length], 1 for LLM generated tokens, 0 for observation/padding tokens.
- input_ids: [bsz, prompt_length + response_length], whole sequence token ids, including prompt tokens
and response tokens.
- attention_mask: [bsz, prompt_length + response_length], 0 for padding tokens, 1 for other tokens.
- position_ids: [bsz, prompt_length + response_length], incremental position ids.
For multi-turn conversations:
responses: |<- LLM generation ->|<- tool_calls ->|<- LLM generation ->|<- padding ->|
response_mask: | 1, 1, 1, ..., 1, 1 | 0, 0, .., 0, 0 | 1, 1, 1, ..., 1, 1 | 0, 0, ..., 0|
"""
config = self.config.actor_rollout_ref.rollout
sampling_params = dict(
temperature=config.temperature,
top_p=config.top_p,
repetition_penalty=1.0,
)
# override sampling params for validation
if batch.meta_info.get("validate", False):
sampling_params["top_p"] = config.val_kwargs.top_p
sampling_params["temperature"] = config.val_kwargs.temperature
# by default, we assume it's a single turn agent
if "agent_name" not in batch.non_tensor_batch:
batch.non_tensor_batch["agent_name"] = np.array(["single_turn_agent"] * len(batch), dtype=object)
tasks = []
agent_names = batch.non_tensor_batch["agent_name"]
raw_prompts = batch.non_tensor_batch["raw_prompt"]
if "index" in batch.non_tensor_batch:
index = batch.non_tensor_batch["index"]
else:
index = np.arange(len(raw_prompts))
trajectory_info = await get_trajectory_info(
batch.meta_info.get("global_steps", -1), index, batch.meta_info.get("validate", False)
)
for agent_name, messages, trajectory in zip(agent_names, raw_prompts, trajectory_info, strict=True):
tasks.append(
asyncio.create_task(self._run_agent_loop(agent_name, messages.tolist(), sampling_params, trajectory))
)
outputs = await asyncio.gather(*tasks)
output = self._postprocess(outputs)
return output根据注释的信息,输入为batch数据,输出为推理后的prompt、response、mask等。这里需要先判断使用的agent_loop的类型,前面提到这里实现了single_turn和tool两种agent_loop,此外用户可以根据AgentLoopBase抽象类来自定义agent_loop(init_class和run两个方法)。
这里先是有一个判断,如果数据集中没有agent_name字段,则默认就是single_turn类型,因此如果你想使用agent_loop,必须在数据预处理的时候加入agent_name字段为tool_agent。这里创建了一个叫trajectory_info的变量,目的是为了rollout_trace,来区分保存到文件中的各个prompt生成的response。接下来进入到_run_agent_loop方法中:
async def _run_agent_loop(
self,
agent_name: str,
messages: list[dict[str, Any]],
sampling_params: dict[str, Any],
trajectory: dict[str, Any],
) -> AgentLoopOutput:
with rollout_trace_attr(
step=trajectory["step"],
sample_index=trajectory["sample_index"],
rollout_n=trajectory["rollout_n"],
validate=trajectory["validate"],
name="agent_loop",
):
assert agent_name in _agent_loop_registry, (
f"Agent loop {agent_name} not registered, registered agent loops: {_agent_loop_registry.keys()}"
)
agent_loop_config = _agent_loop_registry[agent_name]
agent_loop = hydra.utils.instantiate(
config=agent_loop_config,
trainer_config=_DummyConfig(config=self.config),
server_manager=self.server_manager,
tokenizer=self.tokenizer,
)
output = await agent_loop.run(messages, sampling_params)
return output对于定义的不同的agent_loop,需要用register装饰器进行注册(设计模式中的工厂模式),register装饰器如下:
def register(agent_name: str):
"""Register agent loop class."""
def decorator(subclass: type[AgentLoopBase]) -> type[AgentLoopBase]:
fqdn = f"{subclass.__module__}.{subclass.__qualname__}"
_agent_loop_registry[agent_name] = {"_target_": fqdn}
return subclass
return decorator对于装饰的类,将这个信息存入一个名为 _agent_loop_registry 的全局字典中。 - 键 (Key):在装饰器中提供的 agent_name 字符串 (e.g., “my_agent”)。
- 值 (Value):一个特殊格式的字典 {“target”: “类的完整路径”}。
这里我们注册了两个agent_name,然后利用hydra进行初始化,本文重点介绍tool_agent_loop,接下来转到ToolAgentLoop这个类中。
ToolAgentLoop
首先看初始化:
@register("tool_agent")
class ToolAgentLoop(AgentLoopBase):
@classmethod
def init_class(cls, config, tokenizer, **kwargs):
if cls._class_initialized:
return
cls._class_initialized = True
print("Performing class-level ToolAgentLoop initialization")
# Initialize tools from config file
cls.tokenizer = tokenizer
cls.max_user_turns = config.actor_rollout_ref.rollout.multi_turn.max_user_turns
cls.max_assistant_turns = config.actor_rollout_ref.rollout.multi_turn.max_assistant_turns
cls.max_parallel_calls = config.actor_rollout_ref.rollout.multi_turn.max_parallel_calls
cls.max_tool_response_length = config.actor_rollout_ref.rollout.multi_turn.max_tool_response_length
cls.tool_response_truncate_side = config.actor_rollout_ref.rollout.multi_turn.tool_response_truncate_side
tool_config_path = config.actor_rollout_ref.rollout.multi_turn.tool_config_path
tool_list = initialize_tools_from_config(tool_config_path) if tool_config_path else []
cls.tools = {tool.name: tool for tool in tool_list}
cls.tool_schemas = [tool.tool_schema.model_dump(exclude_unset=True, exclude_none=True) for tool in tool_list]
cls.tool_parser = ToolParser.get_tool_parser(config.actor_rollout_ref.rollout.multi_turn.format, cls.tokenizer)
print(f"Initialized tools: {cls.tools}")
cls.prompt_length = config.actor_rollout_ref.rollout.prompt_length
cls.response_length = config.actor_rollout_ref.rollout.response_length
cls.system_prompt = tokenizer.apply_chat_template([{}], add_generation_prompt=False, tokenize=True)关于工具的初始化,来自于sglang团队,详细可以看博客:Awesome-ML-SYS-Tutorial/rlhf/verl/multi-turn/release_log/verl-multiturn-rollout-Release_ZH.md at main · zhaochenyang20/Awesome-ML-SYS-Tutorial · GitHub
简单来说就是将工具的信息定义在一个yaml文件中,将文件路径传入到actor_rollout_ref.rollout.multi_turn.tool_config_path参数,然后获取tool_schemas用于后续传入到chat_template中,此外在tool_parser.py中定义了tool_parser。
这里还有一个值得注意的是system_prompt,这是因为进行chat_template的时候如果没有role为system的会自动加上,而在后面对工具返回结果进行单独chat_template的时候需要将自动添加的system prompt给删除,所以这里预存了一个system_prompt。
下面我们来看最核心的多轮rollout代码:
@rollout_trace_op
async def run(self, messages: list[dict[str, Any]], sampling_params: dict[str, Any]) -> AgentLoopOutput:
metrics = {}
request_id = uuid4().hex
prompt_ids = await self.loop.run_in_executor(
None,
lambda: self.tokenizer.apply_chat_template(
messages, tools=self.tool_schemas, add_generation_prompt=True, tokenize=True
),
)
response_mask = []
user_turns, assistant_turns = 0, 0
while True:
with simple_timer("generate_sequences", metrics):
response_ids = await self.server_manager.generate(
request_id=request_id, prompt_ids=prompt_ids, sampling_params=sampling_params
)
prompt_ids += response_ids
response_mask += [1] * len(response_ids)
assistant_turns += 1
# reach max response length
if len(response_mask) >= self.response_length:
break
# reach max assistant turns
if self.max_assistant_turns and assistant_turns >= self.max_assistant_turns:
break
# reach max user turns
if self.max_user_turns and user_turns >= self.max_user_turns:
break
# no tool calls
_, tool_calls = await self.tool_parser.extract_tool_calls(response_ids)
if not tool_calls:
break
# call tools
tasks = []
for tool_call in tool_calls[: self.max_parallel_calls]:
tasks.append(self._call_tool(tool_call))
with simple_timer("tool_calls", metrics):
tool_responses = await asyncio.gather(*tasks)
if any(isinstance(item, Exception) for item in tool_responses):
break
# append tool_response_ids
tool_response_ids = await self.loop.run_in_executor(
None,
lambda messages=tool_responses: self.tokenizer.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True
),
)
tool_response_ids = tool_response_ids[len(self.system_prompt) :]
# NOTE: last turn should not be user turn, or the EOS token reward
# can't be propagated to previous token in GAE.
if len(response_mask) + len(tool_response_ids) >= self.response_length:
break
prompt_ids += tool_response_ids
response_mask += [0] * len(tool_response_ids)
user_turns += 1
response_ids = prompt_ids[-len(response_mask) :]
prompt_ids = prompt_ids[: len(prompt_ids) - len(response_mask)]
output = AgentLoopOutput(
prompt_ids=prompt_ids,
response_ids=response_ids[: self.response_length],
response_mask=response_mask[: self.response_length],
num_turns=user_turns + assistant_turns + 1,
metrics=metrics,
)
return output
async def _call_tool(self, tool_call: FunctionCall) -> dict[str, str]:
"""Call tool and return tool response."""
tool, instance_id = None, None
try:
# TODO: append malformed tool_call to the prompt: invalid function name or arguments
tool_name = tool_call.name
tool_args = json.loads(tool_call.arguments)
tool = self.tools[tool_name]
instance_id = await tool.create()
tool_response, _, _ = await tool.execute(instance_id, tool_args)
except Exception as e:
logger.exception(f"Error when executing tool: {e}")
return e
finally:
if tool and instance_id:
await tool.release(instance_id)
if len(tool_response) > self.max_tool_response_length:
if self.tool_response_truncate_side == "left":
tool_response = tool_response[: self.max_tool_response_length] + "...(truncated)"
elif self.tool_response_truncate_side == "right":
tool_response = "(truncated)..." + tool_response[-self.max_tool_response_length :]
else:
length = self.max_tool_response_length // 2
tool_response = tool_response[:length] + "...(truncated)..." + tool_response[-length:]
return {
"role": "tool",
"content": tool_response,
}还记得我们这里传入的batch是哪里来的吗?没错,是来自于AgentLoopManager根据num_workers切分的prompt。在run方法一开始,我们为每一个切分后的prompts设定一个request_id,在AsyncLLMServerManager中管理映射。 接下来对prompt进行chat_template,传入我们前面定义好的tool_schemas,这样system_prompt就会加入对应格式的工具信息。
之后就进入到了多轮对话中,先是使用ServerManager进行generate,拼接上prompt_ids(为什么直接拼接tokenid详见issue:训练途中突然崩了,无论是grpo还是reinforce++,出现nan · Issue #30 · 0russwest0/Agent-R1)。
我们直接跳到工具解析的部分,定义好的tool_parser从response_ids中解析工具调用信息(其实就是正则表达式匹配),如果没有工具调用,则直接结束,否则就调用_call_tool方法调用工具。调用完工具后返回工具调用的结果,然后将其编码,并截断前面的system
prompt,拼接在prompt_ids后,用于下个循环的推理。注意在训练的时候要将工具返回的结果进行掩码。也就是response_mask += [0] * len(tool_response_ids)。当达到最大循环或者回复长度超出设定的response_length,就结束推理。并按照AgentLoopOutput进行返回。
返回
返回后,我们回到AgentLoopWorker的generate_sequences方法中,可以看到我们将返回的结果都放入了outputs变量中,而在最终输出前,需要进行后处理,也就是_postprocess方法。需要对prompt进行左pad,对response进行右pad,最后整合成DataProto返回。
def generate_sequences(self, prompts: DataProto) -> DataProto:
"""Split input batch and dispatch to agent loop workers.
Args:
prompts (DataProto): Input batch.
Returns:
DataProto: Output batch.
"""
if self.config.actor_rollout_ref.rollout.free_cache_engine:
self.wake_up()
chunkes = prompts.chunk(len(self.agent_loop_workers))
outputs = ray.get(
[
worker.generate_sequences.remote(chunk)
for worker, chunk in zip(self.agent_loop_workers, chunkes, strict=True)
]
)
output = DataProto.concat(outputs)
if self.config.actor_rollout_ref.rollout.free_cache_engine:
self.sleep()
# calculate performance metrics
metrics = [output.meta_info["metrics"] for output in outputs] # List[List[Dict[str, str]]]
timing = self._performance_metrics(metrics, output)
output.meta_info = {"timing": timing}
return output然后回到AgentLoopWorker的generate_sequences方法中,将各个worker推理的结果concat起来。并将一些metric放入meta_info来logger。