语言模型
语言模型
语言模型是一个很大的主题,很多nlp的任务都是基于语言模型进行的,因此理解语言模型是很重要的。
语言模型简单说就是 计算一个句子在语言中出现的概率。
数学表示
一个语言模型通常构建字符串s的概率分布p(s),这里p(s)反应字符串s作为一个句子出现的概率。
对于一个由m个基元(可以是字、词或者短语)构成的句子\(s=w_1,w_2, \dots w_m\),其概率计算公式可以表示为(乘法公式,详见bayes):
\[ p(s) = p(w_1)p(w_2\mid w_1)p(w_3\mid w_1, w_2)\cdots p(w_m\mid w_1w_2\dots w_{m-1})= \prod_{i=1}^mp(w_i\mid w_1\cdots,w_{i-1}) \]
但是很明显这个计算复杂度是极大的。 ## 评价指标 语言模型的常用评价指标是困惑度(perplexity):在一个测试数据上的perplexity越低,说明建模的效果越好。perplexity计算公式如下:
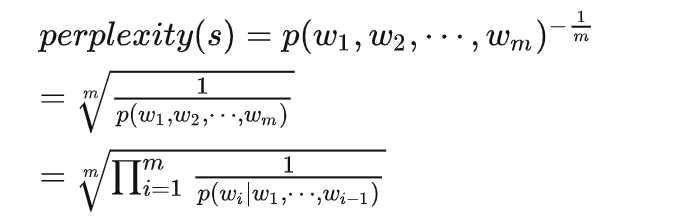
简单来说,困惑度就是刻画一个语言模型预测一个语言样本的能力,其实际上就是计算每一个词得到的概率倒数的几何平均,即模型预测下一个词的平均可选择数量。
在实际应用中通常使用log的形式,即: 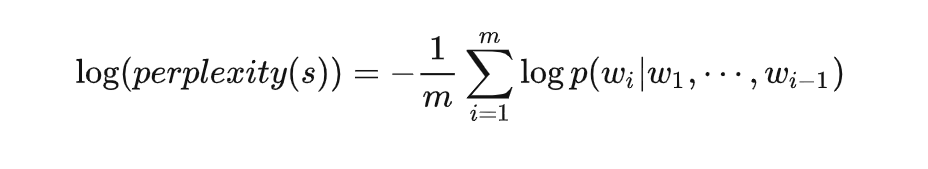
统计语言模型
n-gram
为了解决复杂度高的问题,因此引入马尔科夫假设,即当前词的预测概率只与之前n-1个词相关,基于此,语言模型可以修改如下:
\[ p(s) = p(w_1, w_2, \dots, w_m) = \prod_{i=1}^mp(w_i\mid w_{i-n+1}, w_{i-1}) \] 当n取1,2,3时,n-gram可以称为unigram、bigram、trigram。n越大复杂度越高。
n-gram model一般采用MLE进行参数估计:
\[ p(w_i\mid w_{i-n+1}, \cdots, w_{i-1}) = \frac{C(w_{i-n+1}, \cdots,w_{i-1}, w_i)}{C(w_{i-n+1}, \cdots, w_{i-1})} \]
即使训练语料再大,也存在参数为0的情况,这时候就需要引入数据平滑策略,其中最为常用的就是拉普拉斯平滑。
拉普拉斯平滑
Add one
拉普拉斯平滑,即强制让所有的n-gram至少出现一次,只需要在分子和分母上分别做加法即可。这个方法的弊端是,大部分n-gram都是没有出现过的,很容易为他们分配过多的概率空间。
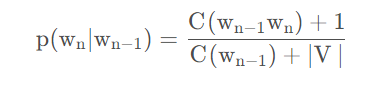 #### Add-K
在Add-one的基础上做了一点小改动,原本是加一,现在加上一个小于1的常数K
K。但是缺点是这个常数仍然需要人工确定,对于不同的语料库K可能不同。
#### Add-K
在Add-one的基础上做了一点小改动,原本是加一,现在加上一个小于1的常数K
K。但是缺点是这个常数仍然需要人工确定,对于不同的语料库K可能不同。 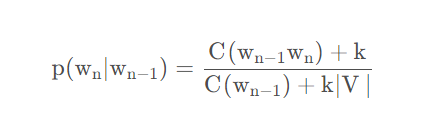 k取1时与add one 相同
k取1时与add one 相同
Kneser-Ney Smoothing
这是目前ngram模型效果最好的平滑方法。 ## 神经网络语言模型
具体可以看本博客有关神经网络语言模型的内容,NNLM是第一个出现的神经网络语言模型。