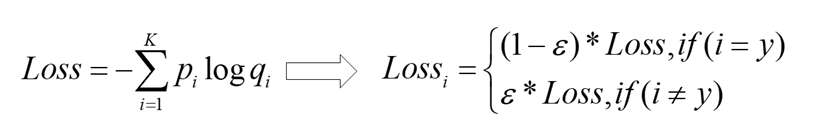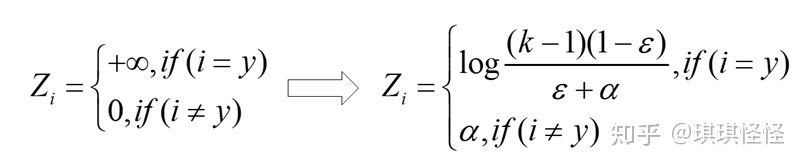标签平滑
神经网络会促使自身往正确标签和错误标签差值最大的方向学习,在训练数据较少,不足以表征所有的样本特征的情况下,会导致网络过拟合。因为onehot本身就是一个稀疏的向量,如果所有无关类别都为0的话,就可能会疏忽某些类别之间的联系。 具体的缺点有: - 真是标签与其它标签之间的关系被忽略了,很多有用的知识学不到了。 - 倾向于让模型更加武断,导致泛化性能差 - 面对有噪声的数据更容易收到影响。
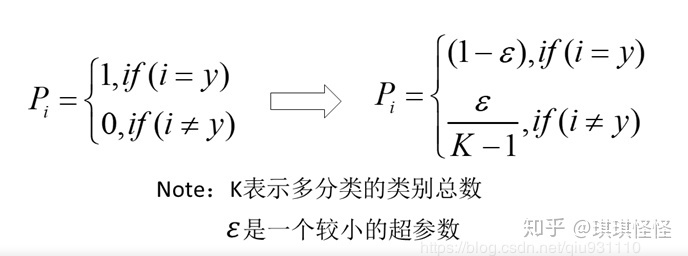
label smoothing可以解决上述问题,这是一种正则化策略,主要是通过soft one-hot来加入噪声,减少了真实样本标签的类别在计算损失函数时的权重,最终起到抑制过拟合的效果。
增加label smoothing后真实的概率分布有如下改变: