协同过滤
协同过滤是推荐系统里面一个常用的算法,因为信息检索领域和推荐系统领域其实是有点相似的(对我目前的认知来说,对两个领域的了解都不深),所以就把协同过滤的笔记整理到了信息检索的目录下。现在主要的都是深度学习的方法了吧,双塔模型什么的。还不是太了解,继续学习。
协同过滤的内核就是一个有关物品和用户的共现矩阵,一般来说,矩阵上的元素是用户对于商品的评价或者说喜爱度。 一般来说,协同过滤分为三种类型,第一种是基于用户的协同过滤,第二种是基于项目的协同过滤,第三种是基于模型的协同过滤。
基于用户的协同过滤
基于用户的协同过滤主要考虑的是用户与用户之间的相似度,只要找出相似用户喜欢的物品,并预测目标用户对对应物品的评分,就可以找到评分最高的若干个物品推荐给用户。 缺点:
- 当用户数大于物品数时,用户相似度矩阵的开销特别大。
- 当用户行为过于稀疏,找到相似用户的准确性很低
- 解释性不强。
基于项目的协同过滤
基于项目的协同过滤与基于用户的协同过滤类似,不过这时需要转向找到物品与物品之间的相似度,只有找到了目标用户对某些物品的评分,我们就可以对相似度高的类比物品进行预测,将评分最高的若干个相似物品推荐给用户。
也有一些缺点:
- 当物品数远大于用户数时,物品相似度矩阵的开销会特别大
- 当有新物品时,没有办法在不离线更新物品相似度表的情况下将新物品推荐给客户。
相似度计算
因为得到共现矩阵后,计算相似度就是向量之间计算相似度,有以下几种方法:
- Jaccard系数
- Cosine相似度,用夹角大小表示相似程度。
- Pearson相关性系数,概率论讲过。
基于模型的协同过滤
矩阵分解
因为原始的矩阵非常稀疏,所以一个想法就是生成一个隐变量,将用户和物品映射到这个隐变量表示空间上。
矩阵分解的主要过程,就是先 分解 协同过滤生成的共现矩阵,生成用户和物品的隐向量,再通过用户和物品隐向量间的相似性进行推荐。
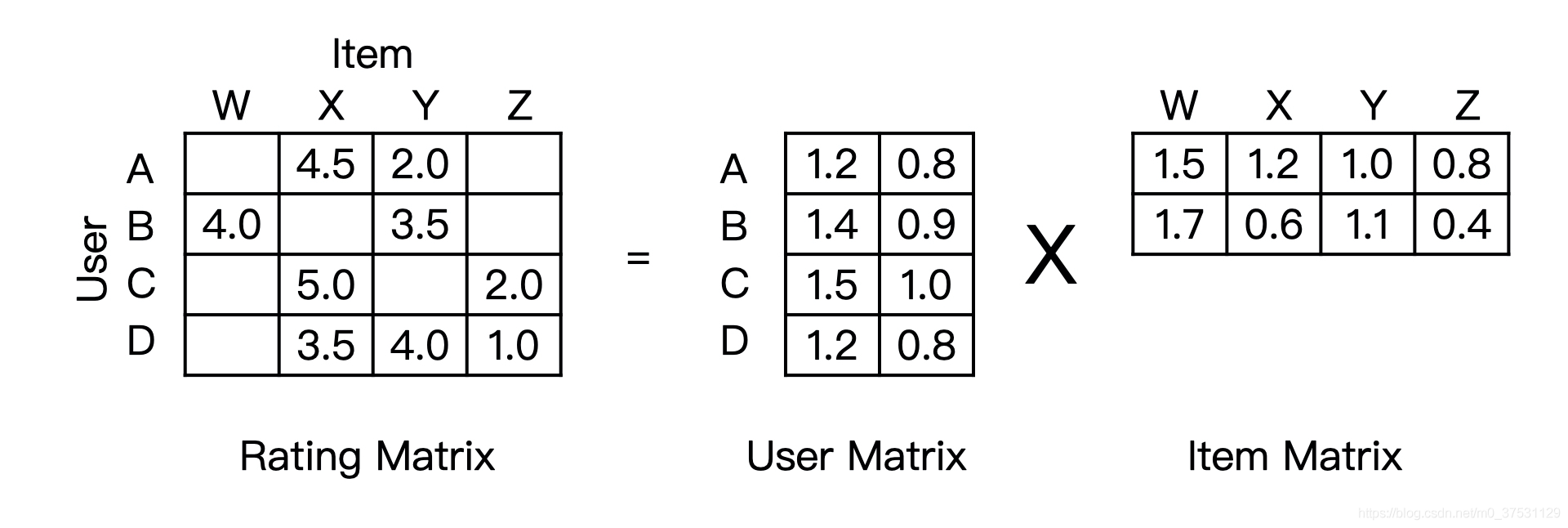
其实和主题模型中LSA很像,学过LSA就很容易理解。
矩阵分解主要有两种做法
- SVD
- 梯度下降
SVD不多说,但它的主要问题很明显,SVD要求原始矩阵是稠密的,但很显然共现矩阵并不稠密,而且无法进行正则化,容易过拟合,因此可以用梯度下降来计算分解矩阵。
梯度下降的最基本的模型是: 
矩阵分解进一步加强了协同过滤的泛化能力,它把协同过滤中的共现矩阵分解成了用户矩阵和物品矩阵,从用户 矩阵中提取出用户隐向量,从物品矩阵中提取出物品隐向量,再利用它们之间的内积相似性进行推荐排序。
基于深度学习的协同过滤
参考文本匹配概述
基于表示学习的模型
结构如下: 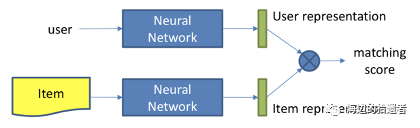
用户和物品分别通过神经网络生成各自的Embedding向量,即表示向量。将其作为中间产物,然后再通过内积等交互函数得到匹配分数,进行排序推荐。 DSSM就是一个基于表示学习的模型。 ### 基于匹配方法学习的模型 基于匹配方法学习的深度推荐模型结构如下:

也就是文本匹配中的基于交互型的。 是一个端到端的模型。 NCF就是一个端对端的模型。
总结
协同过滤在深度学习出现之前在推荐领域非常常用,但其缺点也很明显因为它使用非常稀疏的矩阵进行预测,所以泛化能力很弱,虽然使用了矩阵分解等技术,但是使用内积方式来处理用户和物品的交叉,因此拟合能力非常弱,所以出现了神经网络的方法,比如NeuralCF等。
参考
https://zhuanlan.zhihu.com/p/69888124有关计算可以看这个。