前缀树
什么是前缀树?
前缀树是N叉树的一种特殊形式。通常来说,一个前缀树是用来存储字符串的。前缀树的每一个节点代表一个字符串(前缀)。每一个节点会有多个子节点,通往不同子节点的路径上有着不同的字符。子节点代表的字符串是由节点本身的原始字符串,以及通往该子节点路径上所有的字符组成的。
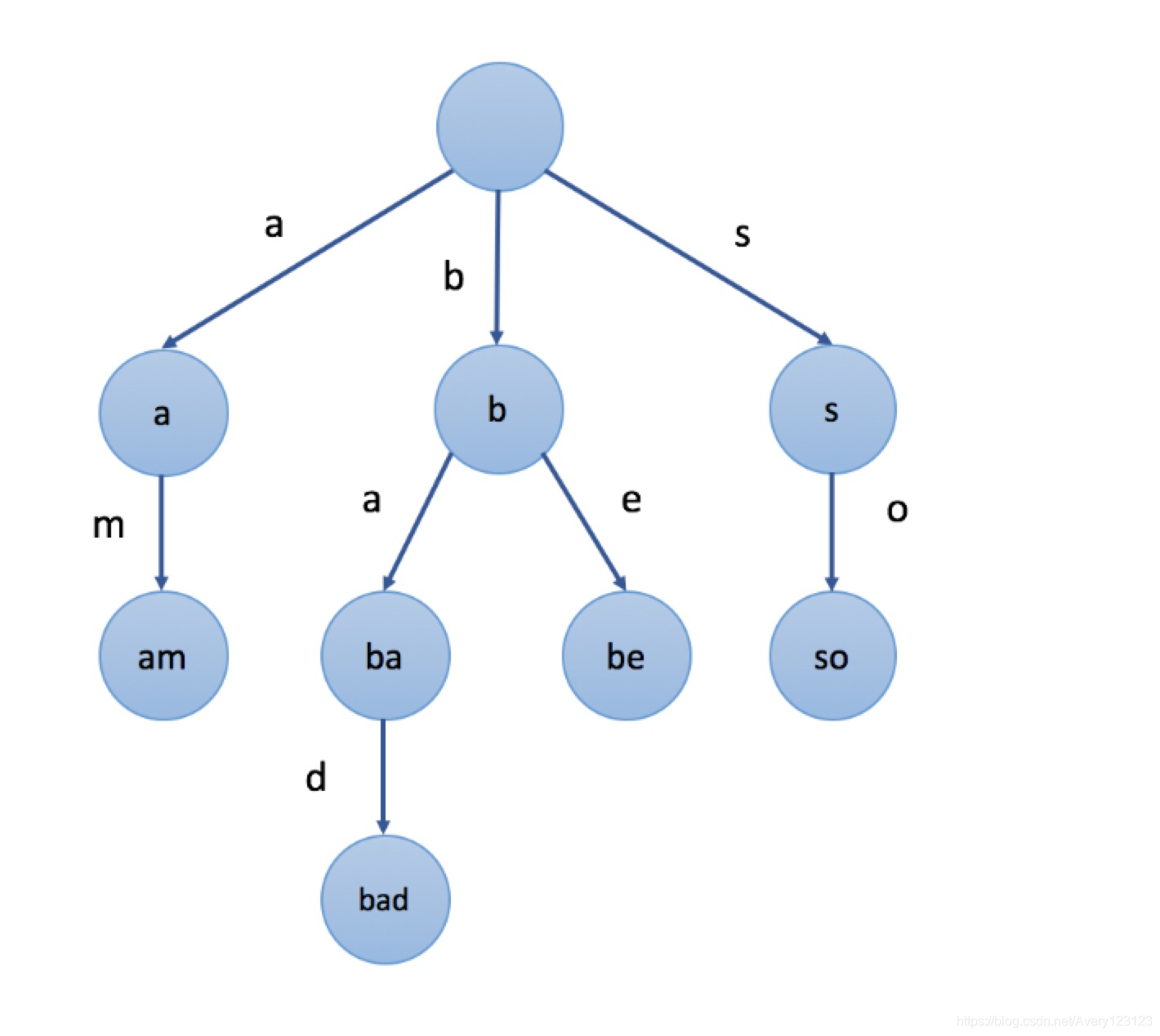 在上图示例中,我们在节点中标记的值是该节点对应表示的字符串。例如,我们从根节点开始,选择第二条路径
‘b’,然后选择它的第一个子节点 ‘a’,接下来继续选择子节点
‘d’,我们最终会到达叶节点
“bad”。节点的值是由从根节点开始,与其经过的路径中的字符按顺序形成的。
在上图示例中,我们在节点中标记的值是该节点对应表示的字符串。例如,我们从根节点开始,选择第二条路径
‘b’,然后选择它的第一个子节点 ‘a’,接下来继续选择子节点
‘d’,我们最终会到达叶节点
“bad”。节点的值是由从根节点开始,与其经过的路径中的字符按顺序形成的。
值得注意的是,根节点表示空字符串。
前缀树的一个重要的特性是,节点所有的后代都与该节点相关的字符串有着共同的前缀。这就是前缀树名称的由来。
我们再来看这个例子。例如,以节点 “b” 为根的子树中的节点表示的字符串,都具有共同的前缀 “b”。反之亦然,具有公共前缀 “b” 的字符串,全部位于以 “b” 为根的子树中,并且具有不同前缀的字符串来自不同的分支。
前缀树有着广泛的应用,例如自动补全,拼写检查等等。
代码
import collections
class TrieNode(object): # 定义节点
# Initialize your data structure here.
def __init__(self):
self.node = collections.defaultdict(TrieNode)
self.char = ""
self.is_word = False
@property
def data(self):
return self.node
def __getitem__(self, key):
return self.node[key]
def __str__(self) -> str:
return self.char
__repr__ = __str__
class Trie(object):
def __init__(self):
"""
Initialize your data structure here.
"""
self.root = TrieNode()
def insert(self, word):
"""
Inserts a word into the trie.
:type word: str
:rtype: void
"""
node = self.root
for chars in word:
temp = node.char
node = node[chars] # 因为defaultdict,如果不存在则自动生成键
node.char = temp + chars # 键可以视为路径上的字符,节点可以视为从根到当前节点表示的前缀或单词。
node.is_word = True # 这里很重要,用于search判断是否为完整的单词
def search(self, word):
"""
Returns if the word is in the trie.
:type word: str
:rtype: bool
"""
node = self.root
for chars in word:
if chars not in node.data.keys(): # 因为defaultdict所以不能判断value为None,要判断键是否存在
return False
node = node[chars]
# 判断单词是否是完整的存在在trie树中
return node.is_word
def startsWith(self, prefix):
"""
Returns if there is any word in the trie that starts with the given prefix.
:type prefix: str
:rtype: bool
"""
node = self.root
for chars in prefix:
if chars not in node.data.keys(): # 和上面同理
return False
node = node[chars]
return True
def get_all_words(self): # 获取所有的单词
q = [self.root]
while q:
node = q.pop(0) # 相当于一个队列
for child in node.data.values():
if child.is_word:
yield child.char
q.append(child)应用
前缀树在中文分词的应用,前缀树的实现和上面的可能不太一样,不过功能都是一样的,主要就是找句子中的词有没有出现在前缀树中。
from trie import Trie
import time
class TrieTokenizer(Trie):
"""
基于字典树(Trie Tree)的中文分词算法
"""
def __init__(self, dict_path):
"""
:param dict_path:字典文件路径
"""
super(TrieTokenizer, self).__init__()
self.dict_path = dict_path
self.create_trie_tree()
self.punctuations = """!?。"#$%&':()*+,-/:;<=>@[\]^_`{|}~⦅⦆「」、、〃》「」『』【】〔〕〖〗〘〙〚〛〜〝〞〟〰〾〿–—‘’‛“”„‟…‧﹏."""
def load_dict(self):
"""
加载字典文件
词典文件内容如下,每行是一个词:
AA制
ABC
ABS
AB制
AB角
:return:
"""
words = []
with open(self.dict_path, mode="r", encoding="utf-8") as file:
for line in file:
words.append(line.strip().encode('utf-8').decode('utf-8-sig'))
return words
def create_trie_tree(self):
"""
遍历词典,创建字典树
:return:
"""
words = self.load_dict()
for word in words:
self.insert(word)
def mine_tree(self, tree, sentence, trace_index):
"""
从句子第trace_index个字符开始遍历查找词语,返回词语占位个数
:param tree:
:param sentence:
:param trace_index:
:return:
"""
if trace_index <= (len(sentence) - 1):
if sentence[trace_index] in tree.data:
trace_index = trace_index + 1
trace_index = self.mine_tree(tree.data[sentence[trace_index - 1]], sentence, trace_index)
return trace_index
def tokenize(self, sentence):
tokens = []
sentence_len = len(sentence)
while sentence_len != 0:
trace_index = 0 # 从句子第一个字符开始遍历
trace_index = self.mine_tree(self.root, sentence, trace_index)
if trace_index == 0: # 在字典树中没有找到以sentence[0]开头的词语
tokens.append(sentence[0:1]) # 当前字符作为分词结果
sentence = sentence[1:len(sentence)] # 重新遍历sentence
sentence_len = len(sentence)
else: # 在字典树中找到了以sentence[0]开头的词语,并且trace_index为词语的结束索引
tokens.append(sentence[0:trace_index]) # 命中词语作为分词结果
sentence = sentence[trace_index:len(sentence)] #
sentence_len = len(sentence)
return tokens
def combine(self, token_list):
"""
TODO:对结果后处理:标点符号/空格/停用词
:param token_list:
:return:
"""
flag = 0
output = []
temp = []
for i in token_list:
if len(i) != 1: # 当前词语长度不为1
if flag == 0:
output.append(i[::])
else:
# ['该', '方法']
# temp=['该']
output.append("".join(temp))
output.append(i[::])
temp = []
flag = 0
else:
if flag == 0:
temp.append(i)
flag = 1
else:
temp.append(i)
return output
if __name__ == '__main__':
now = lambda: time.time()
trie_cws = TrieTokenizer('data/32w_dic.txt')
start = now()
print(f"Build Token Tree Time : {now() - start}")
sentence = '该方法的主要思想:词是稳定的组合,因此在上下文中,相邻的字同时出现的次数越多,就越有可能构成一个词。因此字与字相邻出现的概率或频率能较好地反映成词的可信度。'
'可以对训练文本中相邻出现的各个字的组合的频度进行统计,计算它们之间的互现信息。互现信息体现了汉字之间结合关系的紧密程度。当紧密程 度高于某一个阈值时,'
'便可以认为此字组可能构成了一个词。该方法又称为无字典分词。'
tokens = trie_cws.tokenize(sentence)
combine_tokens = trie_cws.combine(tokens)
end = now()
print(tokens)
print(combine_tokens)
print(f"tokenize Token Tree Time : {end - start}")