共现矩阵
共现矩阵
主要用于发现主题,解决词向量相近关系的表示 例如,语料库如下: - I like deep learning. - I like NLP. - I enjoy flying.
则共现矩阵如下(窗口大小为1) 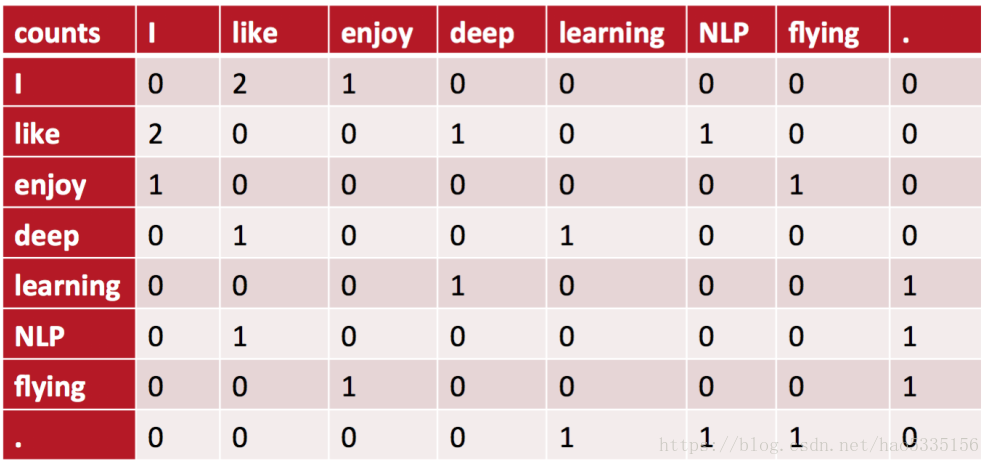 例如:“I like”出现在第1,2句话中,一共出现2次,所以=2。
例如:“I like”出现在第1,2句话中,一共出现2次,所以=2。
对称的窗口指的是,“like I”也是2次
将共现矩阵行(列)作为词向量表示后,可以知道like,enjoy都是在I附近且统计数目大约相等,他们意思相近。
代码
import numpy as np
word2ind = {w:i for i,w in enumerate(words)} # word到key,words就是词汇表
M = np.zeros((num_words, num_words)) # num_words是词汇表的长度
for c in corpus: # 假设语料库是一个列表,元素为一段文本。遍历语料库
for idx, word in enumerate(c): # 遍历文本的每一个词,这里默认空格分词
for i in range(1, window_size+1): # 对窗口大 小进行遍历
left = idx - i # 自己与自己不算共现,所以这里要加减
right = idx + i
if left >= 0: # 左边元素
M[word2ind[word], word2ind[c[left]]] += 1
if right < len(c): # 右边元素
M[word2ind[word], word2ind[c[right]]] += 1